First off, sorry about the lack of posts, there just hasn’t been very much in tech that has inspired me recently. I’m sure part of the reason is my job has been fairly boring for a long time now, so I’m not being exposed to a whole lot of stuff. I don’t mind that trade off for the moment – still a good change of pace compared to past companies. Hopefully 2014 will be a more interesting year.
3PAR still manages to create some exciting news every now and then and they seem to be on a 6-month release cycle now, far more aggressive than they were pre acquisition. Of course now they have far more resources. Their ability to execute really continues to amaze me, whether it is on the sales or on the technology side. I think technical support still needs some work though. In theory that aspect of things should be pretty easy to fix it’s just a matter of spending the $$ to get more good people. All in all though they’ve done a pretty amazing job at scaling 3PAR up, basically they are doing more than 10X the revenue they had before acquisition in just a matter of a few short years.
This all comes from HP Discover – there is a bit more to write about but per usual 3PAR is the main point of interest for myself.
Turbo-charging the 3PAR 7000
Roughly six months ago 3PAR released their all-flash array the 7450. Which was basically a souped up 7400 with faster CPUs, double the memory, optimized software for SSDs and a self imposed restriction that they would only sell it with flash(no spinning rust).

3PAR’s Performance and cost improvements for SSDs Dec 2013
At the time they said they were still CPU bound and that their in house ASIC was nowhere near being taxed to the limit. Simultaneously they could not put more (or more powerful) CPUs in the chassis due to cooling restraints in the relatively tiny 2U package that a pair of controllers come in.
Given the fine grained software improvements they released earlier this year I (along with probably most everyone else) was not expecting that much more could be done. You can read in depth details, but highlights included:
- Adaptive read caching – mostly disabling read caching for SSDs, at the same time disabled prefetching of other blocks. SSDs are so fast that there is little benefit to doing either. Not caching reads to SSDs has a benefit of dedicating more of the cache to writes.
- Adaptive write caching – with disks 3PAR would write an entire 16kB block to disk because there is no penalty for doing so. With SSDs they are much more selective in only writing the small blocks that changed, they will not write 16kB if only 4kB has changed because there is no penalty with SSDs like there are with disks.
- Autonomic cache offload – More sophisticated cache management algorithms
- Multi tenant improvements – Multi threaded cache flushing, breaking up large sequential I/O requests into smaller chunks for the SSDs to ingest at a faster rate. 3PAR has always been about multi tenancy.
Net effect of all of these are more effective IOPS and throughput, more efficiency as well.
With these optimizations, the 7450 was rated at roughly 540,000 IOPS @ 0.6ms read latency (100% read). I guesstimated based on the SPC-1 results from the 7400 that a 7450 could perhaps reach around 410,000 IOPS. Just a guess though..
So imagine my surprise when they come out and say the same system with the same CPUs, memory etc is now performing at a level of 900,000 IOPS with a mere 0.7 milliseconds of latency.
The difference? Better software.
Mid range I/O scalability
Storage
Array | 3PAR F200
(2-node)
[EndOfLife] | 3PAR
F400
(4-node)
[EndOfLife] | 3PAR
7200
(2-node) | 3PAR
7400
(4-node) | 3PAR
7450
(4-node) |
100% Random Read
(Backend, between
disks and controllers) | 34,400 | 76,800 | 150,000 | 320,000 | N/A |
100%
Random
Read IOPS
(Front end between
hosts and controllers)
[before
MSI-X
upgrade] | N/A | N/A
| N/A | N/A | 540,000
|
100%
Random
Read
(Front end between
hosts and controllers)
[after
MSI-X] | Not possible | Not possible | Not
Yet
Available | Not
Yet
Available | 900,000
|
SPC-1
I/O | ~45,000
(guesstimate) | 93,050 | ~100,000
(guesstimate) | 258,000 | ~700,000
(guesstimate) |
100%
Random
Read
Throughput
(Backend, between
disks and controllers) | 1.3GB/s | 2.6GB/s | 2.5GB/s | 4.8GB/s | 5.5GB/s |
100%
Random
Read
Throughput
(Front end between
hosts and controllers)
| N/A | N/A | N/A | N/A | N/A |
Stop interrupting me
What allowed 3PAR to reach this level of performance is by leveraging a PCI-express feature called Message Signaled Interrupts, or MSI-X which Wikipedia describes as:
MSI-X (first defined in PCI 3.0) permits a device to allocate up to 2048 interrupts. The single address used by original MSI was found to be restrictive for some architectures. In particular, it made it difficult to target individual interrupts to different processors, which is helpful in some high-speed networking applications. MSI-X allows a larger number of interrupts and gives each one a separate target address and data word. Devices with MSI-X do not necessarily support 2048 interrupts but at least 64 which is double the maximum MSI interrupts.
(tangent time)
I’m not a hardware guy to this depth for sure. But I did immediately recognize MSI-X from a really complicated troubleshooting process I went through several years ago with some Broadcom network chips on Dell R610 servers (though the issue wasn’t Dell specific). It ended up being a bug with how the Broadcom driver was handling(or not) MSI-X (Redhat bug here). It took practically a year of (off and on) troubleshooting before I came across that bug report. The solution was to disable MSI-X via a driver option (which apparently the Dell supplied drivers came with by default, the OS-supplied drivers did not have that disabled by default).
(end tangent)
So some fine grained kernel work improving interrupts gave them a 1.6 fold improvement in performance.
This performance enhancement applies to the SAS-based 3PAR 7000-series only, the 10000-series had equivalent functionality already in place, and the previous generations (F/T platforms) are PCI-X based(and I believe are all in their end of life phases), and this is a PCI Express specific optimization. I think this level of optimization might really only help SSD workloads as they push the controllers to the limit, unlike spinning rust.
This optimization also reduces the latency on the system by 25%, because the CPU is no longer being interrupted nearly as often it can no only do more work but do the work faster too.
Give me more!
There are several capacity improvements here as well.
New SSDs
There are new 480GB and 920GB SSDs available, which takes the 3PAR 4-node 7400/7450 to a max raw capacity of 220TB (up from 96TB) on up to 240 SSDs.
Bigger entry level
The 3PAR 7200’s spindle capacity is being increased by 60% – from 144 drives to 240 drives. The 7200 is equipped with only 8GB of data cache (4GB per controller – it is I believe the first/only 3PAR system with more control cache than data cache), though it still makes a good low cost bulk data platform with support for up to 400TB of raw storage behind two controllers(which is basically the capacity of the previous generation’s 4-node T400 which had 48GB of data cache, 16GB of control cache, 24 CPU cores, 4 ASICs — obviously the T400 had a much higher price point!).
4TB Drives
Not a big shocker here just bigger drives – 4TB Nearline SAS is now supported across the 7k and 10k product lines, bringing the high end 10800 array to support 3.2PB of raw capacity, and the 7400 sporting up to 1.1PB now. These drives are obviously 3.5″ so on the 7000 series you’ll need the 3.5″ drive cages to use them – the 10k line uses 3PAR’s custom enclosures which support both 2.5″ and 3.5″ (though for 2.5″ drives the enclosures are not compact like they are on 7k).
I was told at some point that the 3PAR OS would start requiring RAID 6 on volumes that were on nearline drives at some point – perhaps that point is now(I am not sure). I was also told you would be able to override this at an OS level if you wish, the parallel chunklet architecture recovers from failures far faster than competing architectures. Obviously with the distributed architecture on 3PAR you are not losing any spindles to dedicated spares nor dedicated parity drives.
If you are really paranoid about disk failures you can on a per-volume basis if you wish use quadruple mirroring on a 3PAR system – which means you can lose up to 75% of the disks in the system and still be OK on those volume(s).
3PAR also uses dynamic sparing –Â if the default spare reserve space runs out, and you have additional unwritten capacity(3PAR views capacity as portions of drives, not whole drives) the system can sustain even more disk failures without data loss or additional overhead of re-configuration etc.
Like almost all things on 3PAR the settings can be changed on the fly without application impact and without up front planning or significant effort on the part of the customer.
More memory
The 3PAR 10400 has received a memory boost – doubling it’s memory configuration from the original configuration. Basically it seems like they decided it was a better idea to unify the 10800 and 10400 controller configurations, though the data sheet seems to have some typos in it(pending clarification). I believe the numbers are 96GB of cache per controller (64GB data, 32GB control), giving a 4-node system 384GB of memory.
Compare this to the 7400 which has 16GB of cache per controller (8GB data, 8GB control) giving a 4-node system 64GB of memory. The 10400 has six times the cache, and still supports 3rd party cabinets.
Now if they would just double the 7200 and 7400’s memory that would be nice 🙂
Keeps getting better
Multi tenant improvements
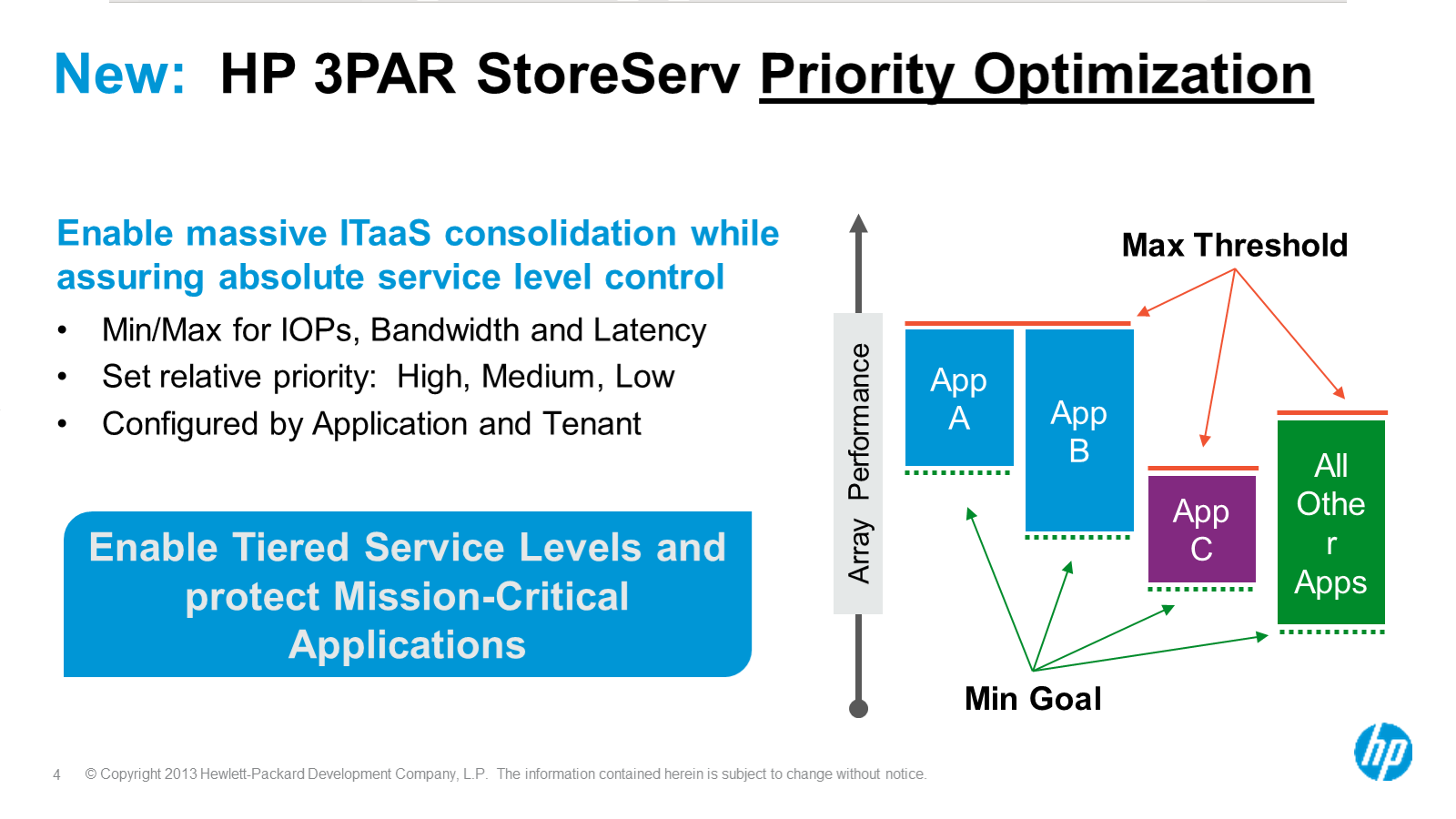
Six months ago 3PAR released their storage quality of service software offering called Priority Optimization. As mentioned before 3PAR has always been about multi tenancy, and due to their architecture they have managed to do a better job at it than pretty much anyone else. But it still wasn’t perfect obviously – there was a need for real array based QoS. They delivered on that earlier this year and now have announced some significant improvements on that initial offering.
Brief recap of what their initial release was about – you were able to define both IOP and bandwidth threshold levels for a particular volume(or group of volumes), the system would respond basically in real time to throttle the workload if it exceeded that level. 3PAR has tons of customers that run multi tenant configurations so they went further in being able to define both a customer as well as an application.

Priority Optimization
So as you can see from the picture above, the initial release allowed you to specify say 20,000 IOPS for a customer, and be able to over provision IOPS for individual applications that customer uses, allowing for maximum flexibility, efficiency and control at the same time.
So the initial release was all about basically rate limiting workloads on a multi tenant system. I suppose you could argue that there wasn’t a lot of QoS it was more rate limiting.
The new software is more QoS oriented – going beyond rate limiting they now have three new capabilities:
- Allows you to specify a performance minimum threshold for a given application/customer
- Allows you to specify a latency target for a given application
- Using 3PAR’s virtual domains feature(basically carve a 3PAR up into many different virtual arrays for service providers) you can now assign a QoS to a given virtual domain! That is really cool.
3PAR Priority Optimization: true array based QoS
Like almost everything 3PAR – configuring this is quite simple and does not require professional services.
3PAR Replication: M to N
With the latest software release 3PAR now supports M to N topologies for replication. Before this they supported 1 to 1, as well as synchronous long distance replication
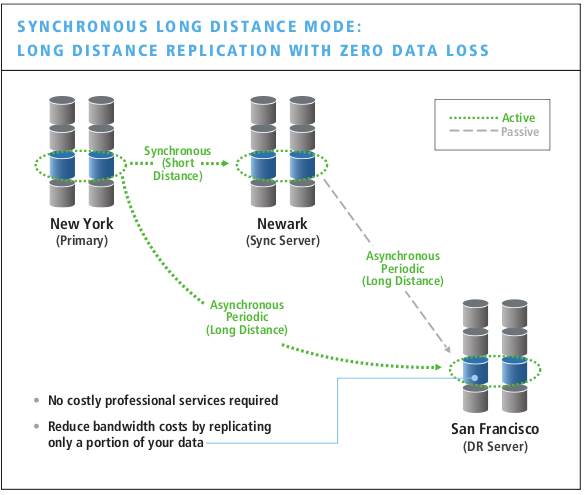
3PAR Synchronous long distance replication: unique in the mid range
All configurable via point and click interface no less, no professional services required.
New though is M to N.
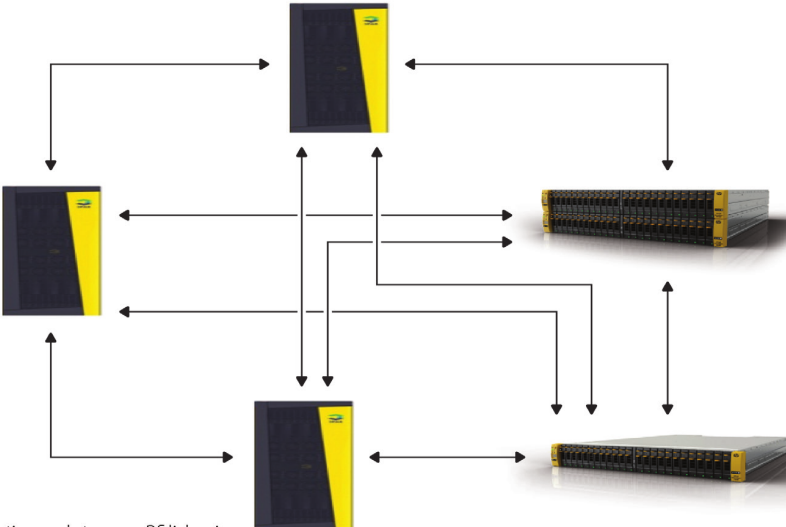
Five 3PAR storage arrays in an any-any bi-directional M:N replication scheme
Need Bigger? How about nine arrays all in some sort of replication party? That’s a lot of arrows.
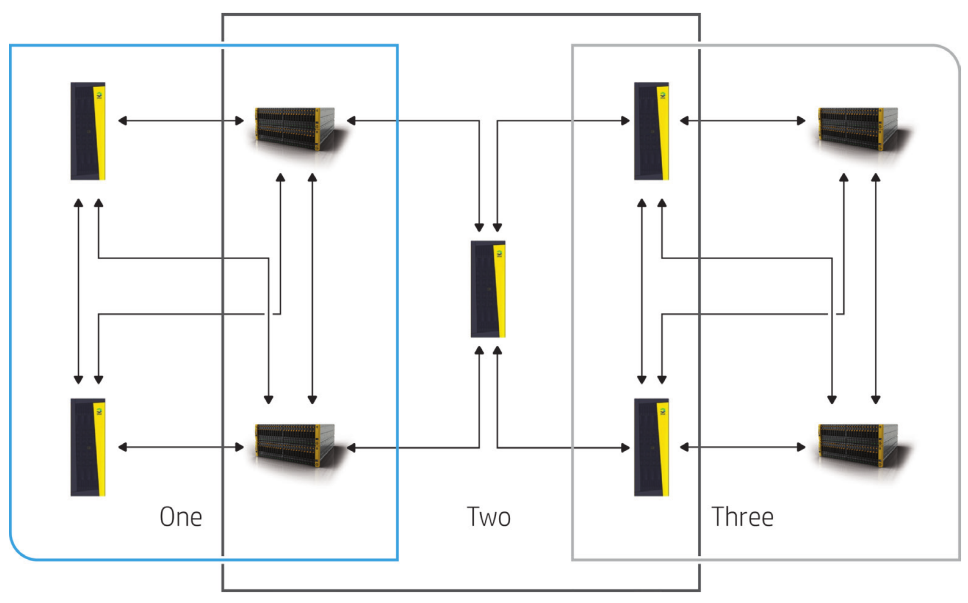
*NINE* 3PAR storage arrays in an any-any bi-directional M:N replication scheme
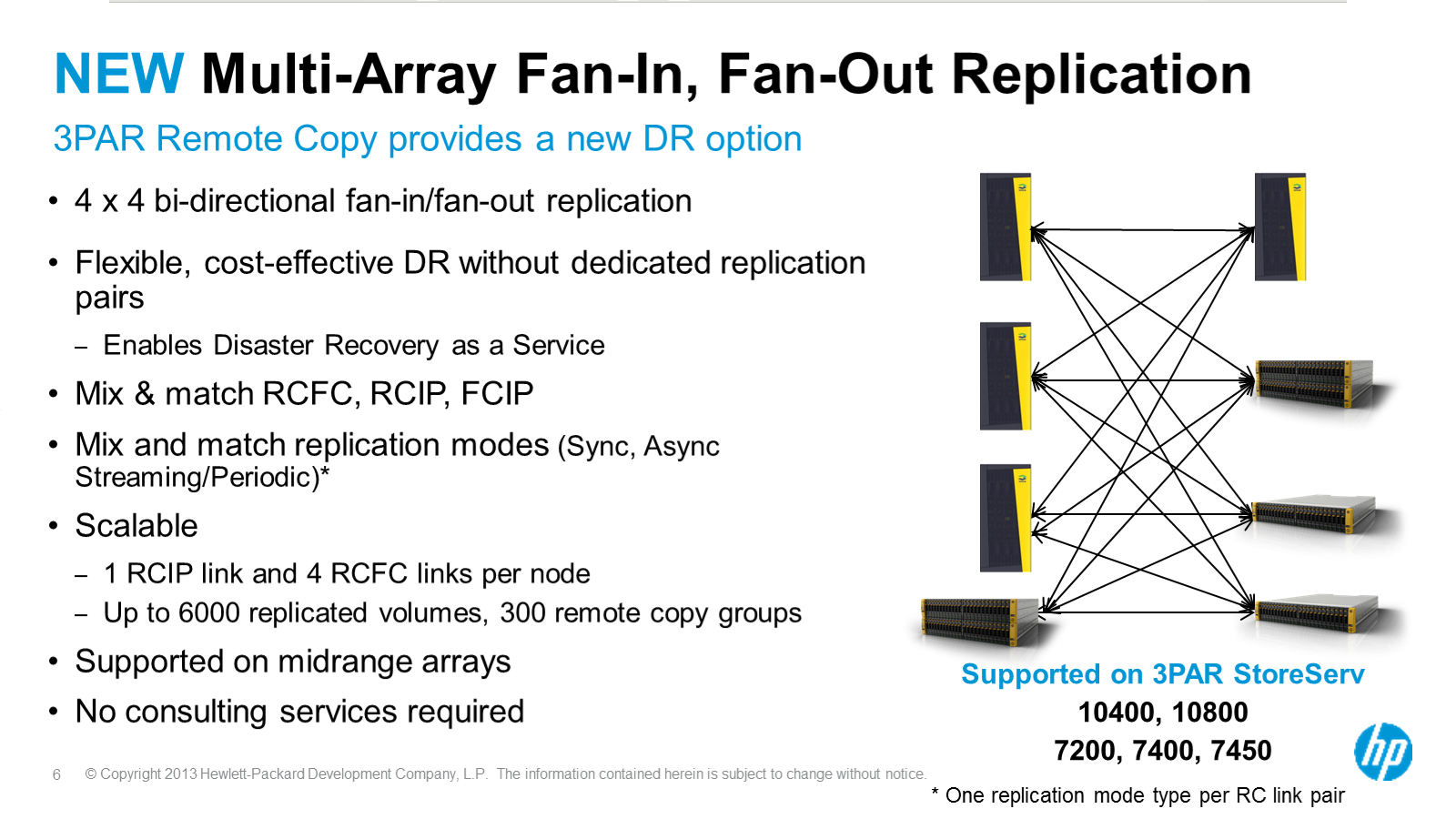
3PAR Multi array replication
More scalable replication
On top of the new replication topology they’ve also tripled(or more) the various limits around the maximum number of volumes that can be replication in the various modes. A four node 3PAR can now replicate up to a maximum of 6,000 volumes in asynchronous mode and 2,400 volumes in synchronous mode.
You can also run up to 32 remote copy fibre channel links per system and up to 8 remote copy over IP links per system (RCIP links are dedicated 1GbE ports on each controller).
Peer motion enhancements
Peer motion is 3PAR’s data mobility package which allows you to transparently move volumes between arrays. It came out a few years ago primarily as a means to provide ease of migration/upgrade between 3PAR systems, and was later extended to support EVA->3PAR migrations. HP’s StoreVirtual platform also does peer motion, though as far as I know it is not yet directly inter-operable with 3PAR. Not sure if it ever will be.
Anyway like most sophisticated things there are always caveats – the most glaring of which in peer motion is they did not support SCSI reservations. Which basically means you couldn’t use peer motion with VMware or other clustering software. With the latest software that limitation has been removed! VMware, Microsoft and Redhat clustering are all supported now.
Persistent port enhancements
Persistent ports is an availability feature 3PAR introduced about a year ago which basically leverages NPIV at the array level – it allows a controller to assume the Fibre Channel WWNs of it’s peer in the event the peer goes offline. This means fail over is much faster, and it removes the dependency of multi pathing software to provide for fault tolerance. That’s not to say that you should not use MPIO software you still should if for nothing else other than better distribution of I/O across multiple HBAs, ports and controllers. But the improved recovery times are a welcome plus.
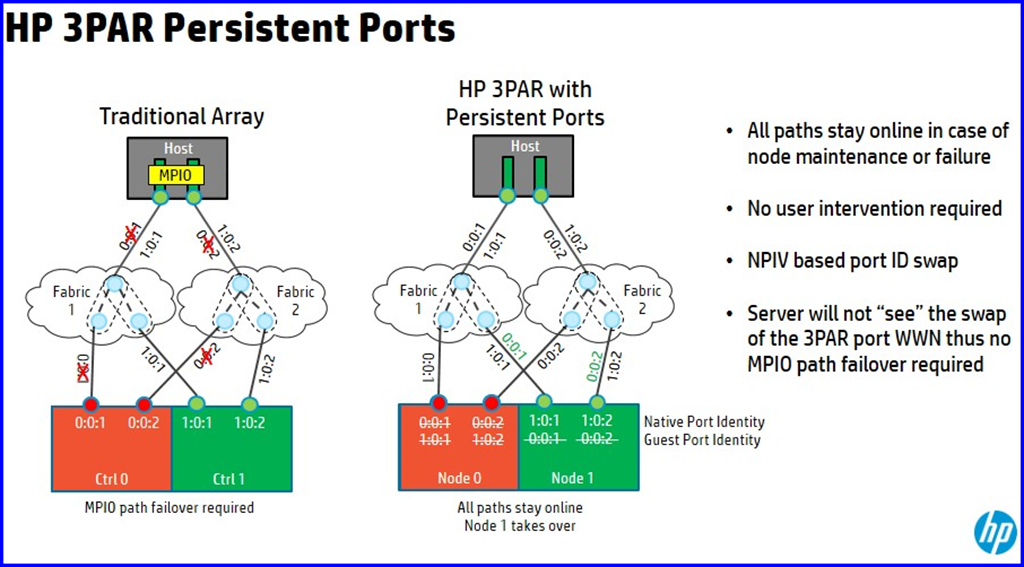
3PAR Persistent ports – transparent fail over for FC/iSCSI/FCoE without MPIO
So what’s new here?
- Added support for FCoE and iSCSI connections
- Laser loss detection – in the event a port is disconnected persistent ports kick in (don’t need to have a full controller failure)
- The speed at which the fail over kicks in has been improved
Combine Persistent Ports with 3PAR Persistent cache on a 4-8 controller system and you have some pretty graceful fail over capabilities.
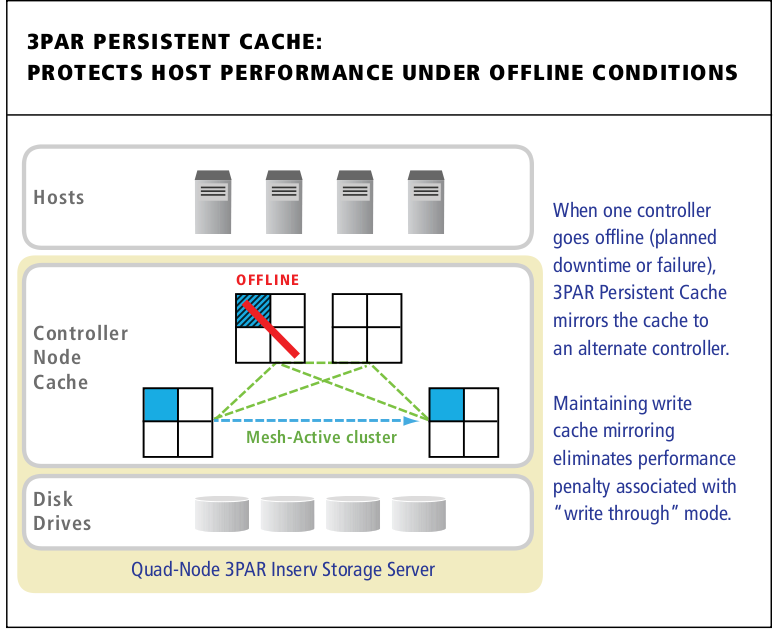
3PAR Persistent Cache mirrors cache from a degraded controller pair to another pair in the cluster automatically.
3PAR Persistent Cache was released back in 2010 I believe, no updates here, just put the reference here for people that may not know what it is since it is a fairly unique ability to have especially in the mid range.
More Secure
Also being announced is a new set of FIPS 140-2 validated self encrypting drives with sizes ranging from 450GB 10k to 4TB nearline.
3PAR also has a 400GB SSD encrypting drive as well though I don’t see any mention of FIPS validation on that unit.
3PAR arrays can either be encrypted or not encrypted – they do not allow you to mix/match. Also once you enable encryption on a 3PAR array it cannot be disabled.
I imagine you probably aren’t allowed to use Peer Motion to move data from an encrypted to a non encrypted system? Same goes for replication ? I am not sure, I don’t see any obvious clarifications in the docs.
Adaptive Sparing
SSDs, like hard drives all come with a chunk of hidden storage set aside for when blocks wear out or go bad, the disk transparently re-maps from this spare pool. I think SSDs take it to a new level with their wear leveling algorithms.
Anyway, 3PAR’s Adaptive sparing basically allows them to utilize some of the storage from this otherwise hidden pool on the SSDs. The argument is 3PAR is already doing sparing at the sub-disk (chunklet) level, if a chunklet fails then it is reconstructed on the fly – much like a SSD would do to itself if a segment of flash went bad. If too many chunklets fail over time on a disk/SSD the system will pro actively fail the device.
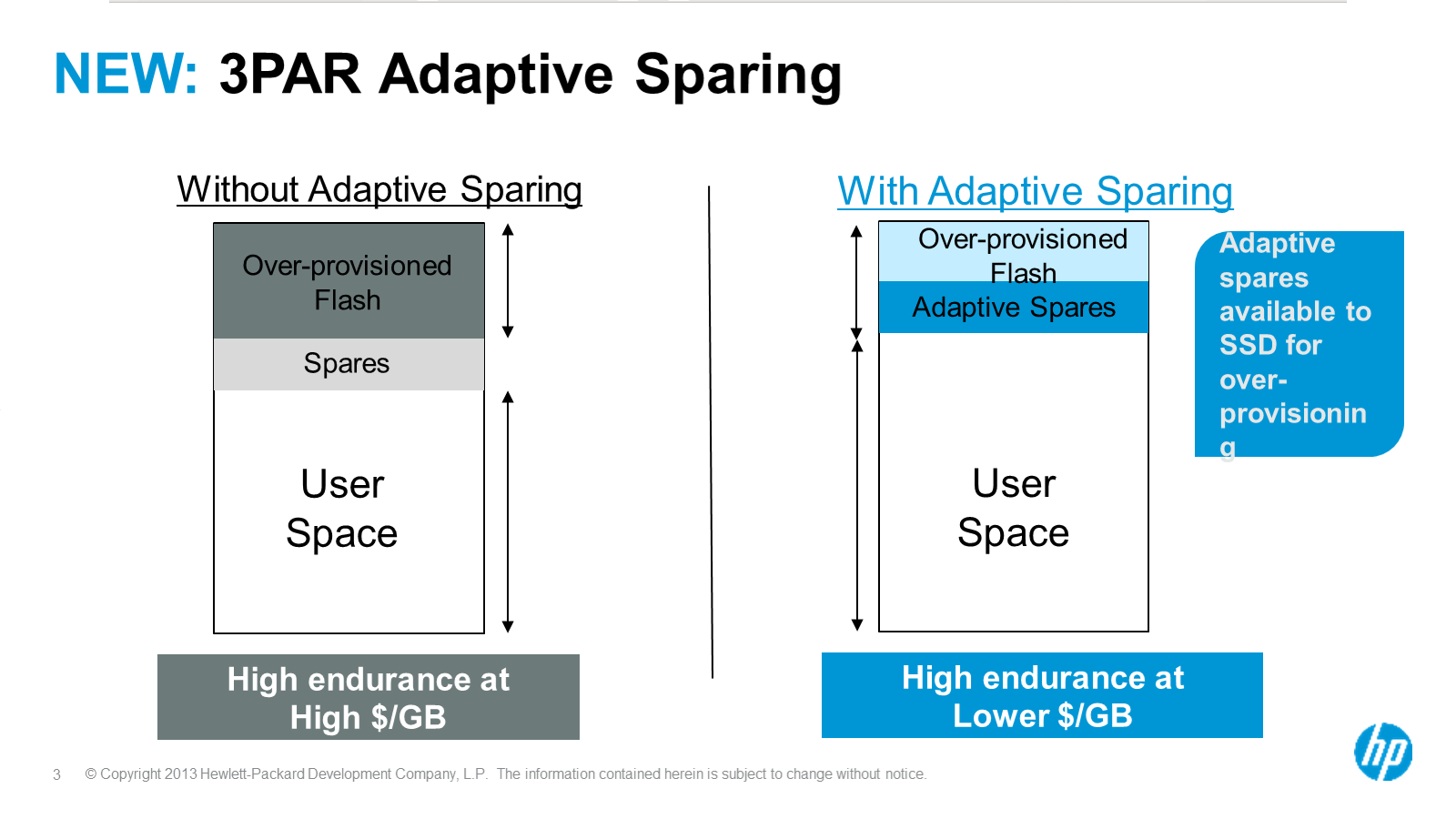
3PAR Adaptive Sparing: gain capacity without sacrificing availbility
At the end of the day the customer gets more usable capacity out of the system without sacrificing any availability. Given the chunklet architecture I think this approach is probably going to be a fairly unique capability.
Lower cost SSDs
Take Adaptive sparing, and combine it with the new SSDs that are being released and you get SSD list pricing(on a per GB basis) which is reduced by 50%. I’d really love to see an updated SPC-1 for the 7450 with these new lower cost devices(plus MSI-X enhancements of course!), I’d be surprised if they weren’t working on one already.
Improved accessibility
3PAR came out with their first web services API a year ago. They’ve since improved upon that, as well as adding enhancements for Openstack Havana (3PAR was the reference implementation for Fibre Channel in Openstack).
They’ve also added management/monitoring tools for both IOS and Android (looks at HP Pre3 and cries in his mind).
HP 3PAR Storefront: Monitor your 3PAR from your mobile device
Screaming sales
3PAR is continuing to kick butt in the market place with their 7000-series, with El Reg reporting that their mid range products have had 300% year over year increases in sales and they have overtaken IBM and NetApp in market share to be #2 behind EMC (23% vs 17%).
This might upset the ethernet vendors but they also report that fibre channel is the largest and fastest growing storage protocol in the mid range space(at least year over year), I’m sure again largely driven by 3PAR who historically has been a fibre channel system. Fibre channel has 50% market share with 49% year over year growth.
What’s missing
Well the elephant in the room that is still not here is some sort of SSD-based caching. HP went so far as to announce something roughly a year ago with their SmartCache technology for Gen8 systems, though they opted not to mention much on that this time around. It’s something I have hounded 3PAR for the past four years to get going, I’m sure they are working on something……
Also I would like to see them support, or at least explain why they might not support, the Seagate Enterprise Turbo SSHD – which is a hybrid drive providing 32GB of eMLC flash cache in front of what I believe is an otherwise 10k RPM 300-600GB disk with self proclaimed upwards of 3X improvement in random I/O over 15k disks. There’s even a FIPS 140-2 model available. I don’t know what the price point of this drive is but find it hard to believe that it’s not a cost effective alternative to flash tiering when you do not have a flash-based cache to work off of.
Lastly I would like to see some sort of automatic workload load balancing with Peer motion – as far as I know that does not yet exist. Though moving TBs of data around between arrays is not something to be taken lightly anyway!