Travel to HP Storage Tech Day/Nth Generation Symposium was paid for by HP; however, no monetary compensation is expected nor received for the content that is written in this blog.
“So, SDN solves a problem for me which doesn’t exist, and never has.”
– Nate (techopsguys.com)
(I think the above quote sums up my thoughts very well so I put it in at the top, it’s also buried down below too)
One of the keynotes of the Nth Generation Symposium last week was from Martin Casado, who is currently a Chief Architect at VMware, and one of the inventors of OpenFlow and the SDN concept in general.
I have read bits and pieces about what Martin has said in the past, he seems like a really smart guy and his keynote was quite good. It was nice to hear confirmation from him many of the feelings I have on SDN in general. There are some areas that I disagree with him on, that is mainly based on my own personal experience in environments I have worked in – the differences are minor, my bigger beef with SDN is not even inside the scope of SDN itself, more on that in a bit.
First off, I was not aware that the term Software Defined Networking was created on the spot by some reporter of the MIT Technology Review. Apparently this reporter who was interviewing Martin had just done an article on Software Defined Radio, the reporter asked Martin what should they call this thing he created? He didn’t know, so the reporter suggested Software Defined Networking since that term was still fresh in the reporter’s head. He agreed and the term was born..
Ripping from one of his slides:
What does SDN Promise?
- Enable rapid innovation in Networking
- Enable new forms of network control
- It’s a mechanism for implementers
- Not a solution for customers
That last bit I did not notice until a few moments ago, that is great to see as well.
He says network virtualization is all about operational simplification
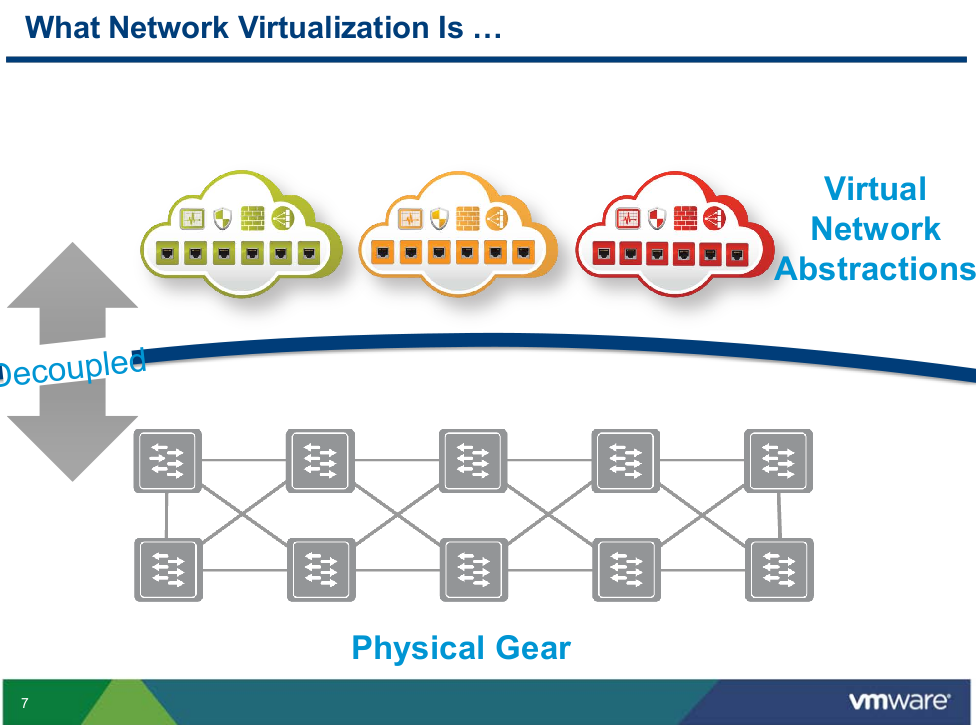
Martin’s view of Network Virtualization
What Network Virtualization is
- Decoupling of the services provided by a virtualized network from the physical network
- Virtual network is a container of network services (L2-L7) provisioned by software
- Faithful reproduction of services provided by physical network
He showed an interesting stat claiming that half of all server access ports are already virtualized, and we’re on track to get to 67% in 2 years. Also apparently 40% of virtualization admins also manage virtual switching.
Here is an interesting slide showing a somewhat complex physical network design and how that can be adapted to be something more flexible with SDN and network virtualization:
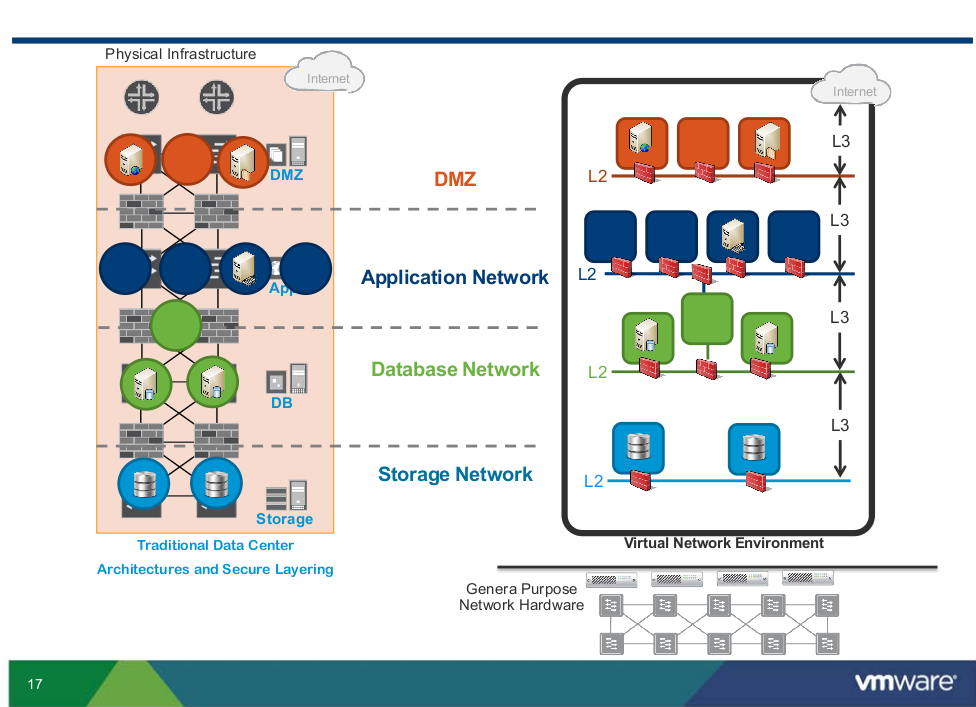
The migration of physical to virtual
Top three reasons for deploying software defined networks
- Speed
- Speed
- Speed
(from another one of Martin’s slides – and yes he had #1,#2,#3 as all the same anything beyond speed was viewed as a distant reason relative to speed)
Where I stand on Martin’s stuff
So first off let me preface this as I am a customer. I have managed L2-L7 networks off and on for the past 12 years now, on top of all of my other stuff. I have designed and built from the ground up a few networks. Networking has never been my primary career path. I couldn’t tear apart an IP packet and understand it if my life depended on it. That being said I have been able to go toe to toe with every “Network Engineer” I have worked with(on almost everything except analyzing packet dumps beyond the most basic of things). I don’t know if that says something about me, or them, or both.
I have worked in what you might consider nothing but “web 2.0” stuff for the past decade. I have never had to support big legacy applications, everything has been modern web based stuff. In two cases it was a three tier application (web+app+db) the others were two tier. I have supported Java, PHP, Ruby and Perl apps (always on Linux).
None of the applications I supported were “web scale” (and I will argue till I am blue in the face that most(99%) organizations will never get to web scale). The biggest scaling application was at the same time my first application – I calculated the infrastructure growth as 1,500%(based on raw CPU capacity) over roughly 3 years – to think the ~30 racks of servers could today fit into a single blade enclosure with room to spare..
What does SDN solve?
Going briefly to another keynote by someone at Intel they had this slide, which goes to show some of the pain they have –
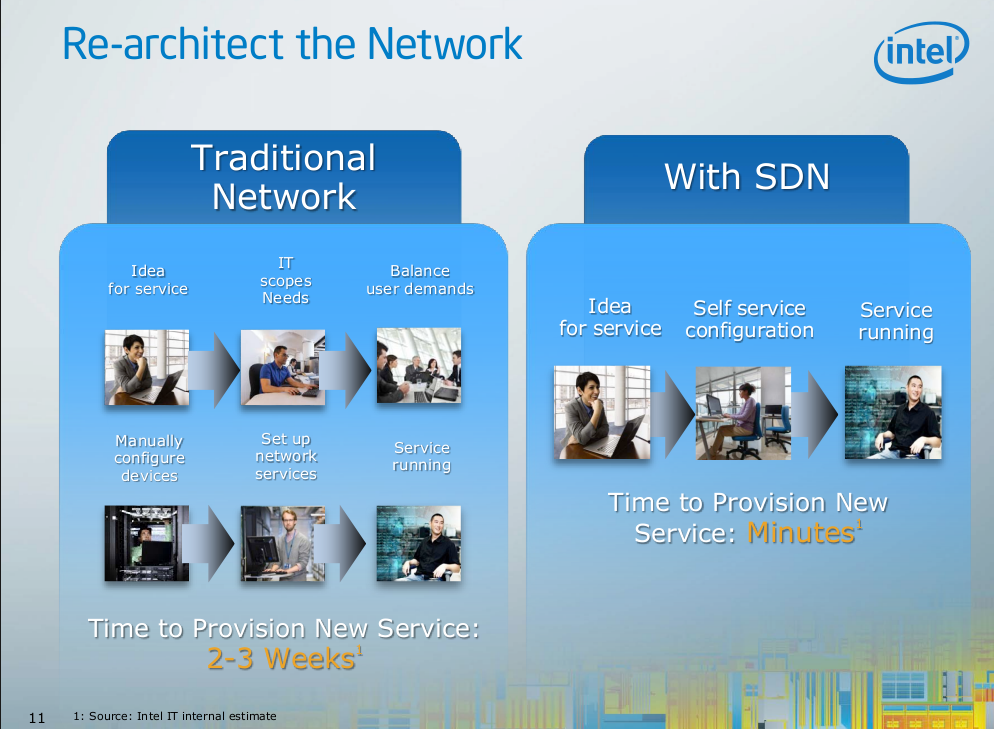
Intel’s network folks take 2-3 weeks to provision a service
Intel’s own internal IT estimates say it takes them 2-3 weeks to provision a new service. This makes really no sense to me, but there is no description as to what is involved with configuring a new service.
So going back to SDN. From what I read, SDN operates primarily at L2-L3. The firewalls/load balancers etc are less SDN and more network virtualization and seem to be outside the scope of core SDN (OpenFlow). To-date I have not seen a single mention of the term SDN when it comes to these services from any organization. It’s all happening at the switch/routing layer.
So I have to assume here for a moment that it takes Intel 2-3 weeks to provision new VLANs, perhaps deploy some new switches, or update some routes or something like that (they must use Cisco if it takes that long!).
My own network designs
Going to my own personal experience – keeping things simple. Here is a sample network design of mine that is recent:
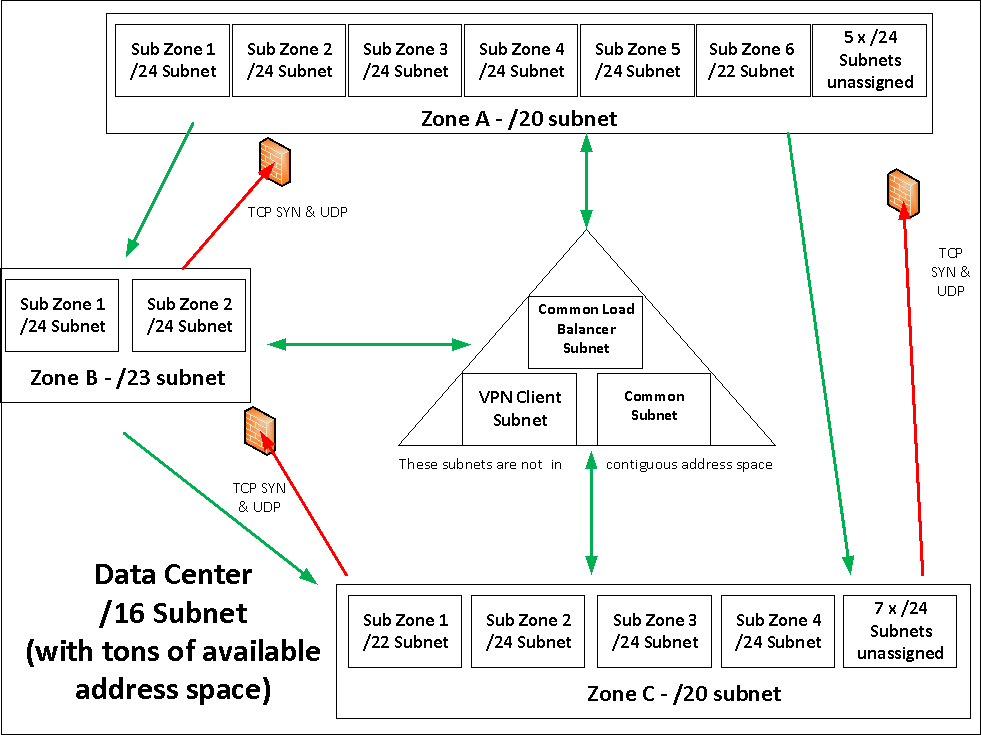
Basic Network Zoning architecture
There is one major zone for the data center itself, which is a /16(levering Extreme’s Layer 3 Virtual switching), then within that, at the moment are three smaller zones (I think supernet may be the right word to describe them), and within those supernets are sub zones (aka subnets aka VLANs). A couple of different sizes for different purposes. Some of the sub zones have jumbo frames enabled, most do not. There is a dedicated sub zone for Vmotion(this VLAN has no router interface on it, in part for improved security perhaps), infrastructure management interfaces, etc. Each zone (A-C) has a sub zone dedicated to load balancer virtual IPs for internal load balancing. The load balancer is directly connected to all of the major zones. Routing to this data center (over VPN – either site to site, or end user VPN) is handled by a simple /16 route, and individual WAN-based ACLs are handled by the VPN appliance.
There are a few misc zones in the middle for various purposes, these have no access restrictions on them at all. Well the VPN client stuff, the ACLs for those are handled by the VPN appliance, not by the rest of the network.
This specific network design is not meant to be extremely high security as that need does not exist in this organization (realistic need, I have seen on several occasions network engineers over engineer something for security when it really was not required and as a result introduce massive bottlenecks into the network – this became an even greater concern for me with all servers running with multiple 10GbE links). The access controls are mainly to protect casual mistakes. Internet facing services in all zones have the same level of security, so if you happen to be able to exploit one of them(I’ve never seen this happen at any company on anything I’ve been responsible for – not that I go to paranoid lengths to secure things either), there’s nothing stopping you from exploiting the others in the exact same way. Obviously nothing is directly connected to the internet other than the load balancer(which runs a hardened operating system), and a site to site VPN appliance(also hardened).
The switch blocks TCP SYNÂ & UDP packets between the respective zones above, since it is not stateful. The switch operates at line rate 10GbE w/ASIC-based ACLs, and performing this function in a hardware (or software) firewall I figured would be too much complexity and reduce performance (not to mention the potential costs of a firewall that is capable of line rate 10Gbps+ – given multiple servers each with multiple 10GbE ports – the possibility exists of throughput far exceeding that of 10Gbps – with the switch it is line rate on every port – up to 1.2Tbps on this switching platform – how much is that firewall again?).
There are four more VLANs related to IP-based storage- two for production and two for non production though they have never really been used to-date. I have the 3PAR iSCSI on these VLANs, with jumbo frames(the purpose of the VLANs), though all of the client systems at the moment use standard frame sizes (iSCSI runs on top of TCP which provides MTU auto negotiation).
There is a pair of hardware load balancers, each has a half dozen or so VLANs, each zone has a dedicated load balancer VLAN for that zone, for services in that zone. The LBs are also the connected to the internet of course, in a two-armed configuration.
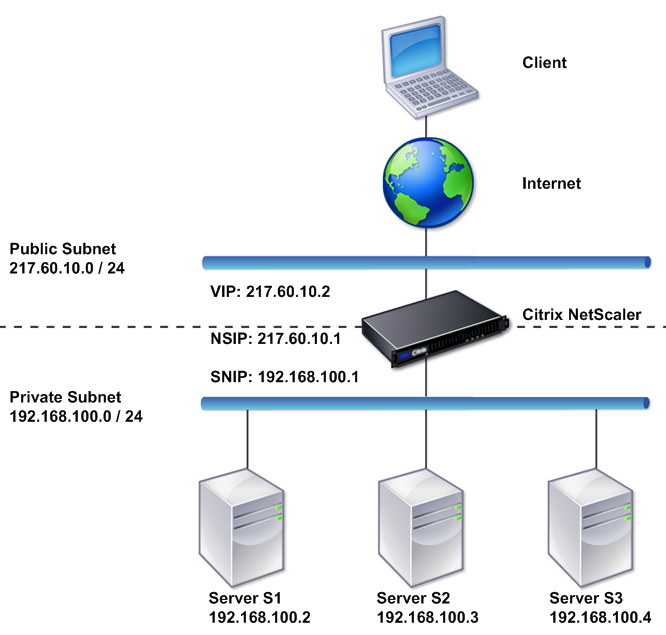
Sample two-arm configuration for a LB from Citrix documentation
I have a similar configuration in another data center using a software load balancer of the same type – however the inability to support more than 4 NICs (4 VLANs at least in vSphere 4.1 – not sure if this is increased in 5.x) limits the flexibility of that configuration relative to the physical appliances, so I had to make a few compromises in the virtual’s case.
So I have all these VLANs, a fully routed layer 3 switching configuration, some really basic ACLs to prevent certain types of communication, load balancers to route traffic from the internet as well as distribute load in some cases.
Get to the point already!
The point of all of this is things were designed up front, provisioned up front, and as a result over the past 18 months we have not had to make any changes to this configuration despite more than doubling in size during that time. We could double again and not have a problem. Doubling again beyond that I may need to add one or two VLANs (sub zones), though I believe the zones as they exist today could continue to exist, I would not have to expand them. I really do not think the organization running this will ever EVER get to that scale. If they do then they’re doing many billions in revenue a year and we can adapt the system if needed(and probably at that point we’d have one or more dedicated network engineers who’d likely promptly replace whatever I have built with something significantly more(overly so) complicated because they can).
If we are deploying a new application, or a new environment we just tell VMware where to plop the VM. If it is QA/Dev then it goes in that zone, if it is testing, it goes in another, production etc.. blah blah…
More complexity outside switching+routing
The complexity when deploying a new network service really lies in the load balancer from an network infrastructure perspective. Not that it is complicated but that stuff is not pre-provisioned up front. Tasks include:
- Configuring server name to IP mappings (within the LB itself)
- Creating Service group(s) & adding servers to the service groups
- Creating virtual server(s) & assigning IPs + DNS names to them
- Creating content switching virtual server(s) & assigning IPs + DNS names to them
- Configuring content switching virtual server(s) – (adding rules to parse HTTP headers and route traffic accordingly)
- Importing SSL cert(s) & assigning them to the virtual servers & cs virtual servers
The above usually takes me maybe 5-20 minutes depending on the number of things I am adding. Some of it I may do via GUI, some I may do via CLI.
None of this stuff is generic, unless we know specifically what is coming we can’t provision that in advance(I’m a strong believer in solid naming conventions – which means no random names!!!).
The VMs by contrast are always very generic(other than the names of course), there’s nothing special to them, drop them in the VLAN they need to be and they are done – we have no VMs that I can think of that have more than one vNIC other than the aforementioned software load balancers. Long gone are the days (for me) where a server was bridged between two different networks – that’s what routers are for.
Network is not the bottleneck for deploying a new application
In fact in my opinion the most difficult process of getting a new application up and running is getting the configuration into Chef. That is by far the longest part of any aspect of the provisioning process. It can take me, or even us, hours to days to get it properly configured and tested. VMs take minutes, load balancer takes minutes. Obviously a tool like Chef makes it much easier to scale an existing application since the configuration is already done. This blog post is all about new applications or network services.
Some of the above could be automated with using the APIs on the platform(they’ve been there for years), and some sort of dynamic DNS or whatever. The amount of work involved to build such a system for an operation of our scale isn’t worth the investment.
The point here is, the L2/L3 stuff is trivial – at least for an operation that we run at today – and that goes for all of the companies I have worked at for the past decade. The L2/L3 stuff flat out doesn’t change very often and doesn’t need to. Sometimes if there are firewalls involved perhaps some new holes need to be poked in them but that just takes a few minutes — and from what I can tell is outside the scope of SDN anyway.
I asked Martin a question on that specific topic. It wasn’t well worded but he got the gist of it. My pain when it comes to networking is not the L2/L3 area – it is the L7 area. Well if we made extensive use of firewalls than L3 fire-walling would be an issue as well. So I asked him how SDN addresses that(or does it). He liked the question and confirmed that SDN does not in fact address that. That area should be addressed by a “policy management tool” of some kind.
I really liked his answer – it just confirms my thoughts on SDN are correct.
Virtual Network limitations
I do like the option of being able to have virtual network services, whether it is a load balancer or firewall or something. But those do have limitations that need to be accounted for. Whether it is performance, flexibility (# of VLANs etc), as well as dependency (you may not want to have your VPN device in a VM if your storage shits itself you may lose VPN too!). Managing 30 different load balancers may in fact be significantly more work(I’d wager it is- the one exception is service provider model where you are delegating administrative control to others – which still means more work is involved it is just being handled by more staff) than managing a single load balancer that supports 30 applications.
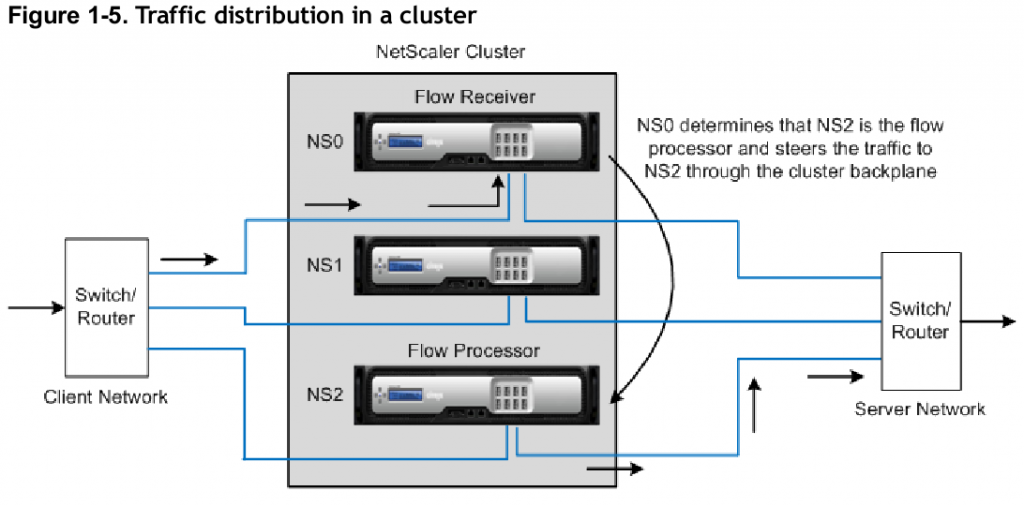
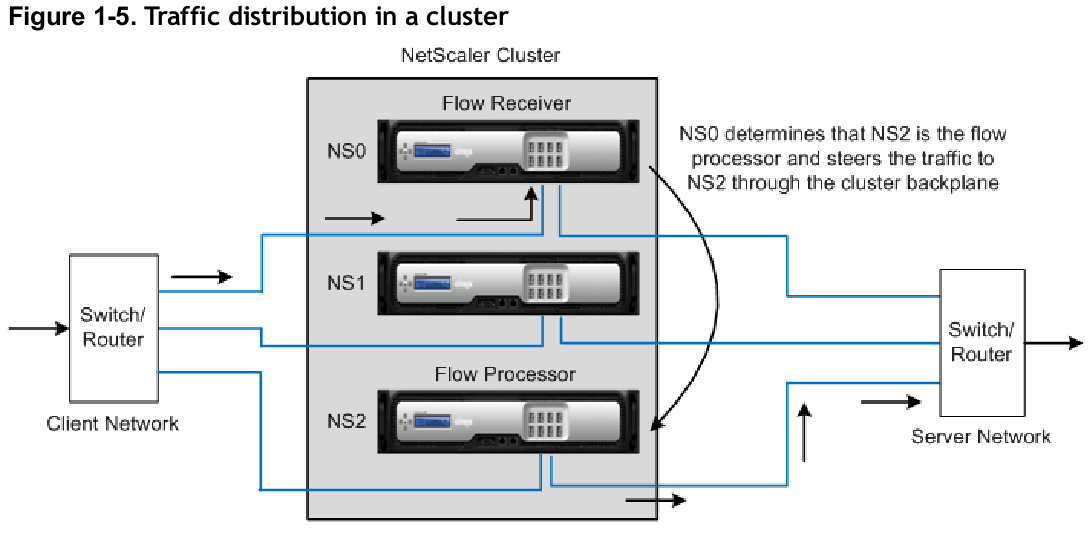
Citrix Netscaler Cluster Traffic Flow
Above is a diagram from Citrix from an earlier blog post I wrote about last year. At the time their clustering tech scaled to 32 systems, which if that still holds true today, at the top end @ 120Gbps/system that’d be nearly 4Tbps of theoretical throughput. Maybe cut that in half to be on the safe side, so roughly 2Tbps..that is quite a bit.
Purpose built hardware network devices have long provided really good performance and flexibility. Some of them even provide some layer of virtualization built in. This is pretty common in firewalls. More than one load balancing company has appliances that can run multiple instances of their software as well in the event that is needed. I think the instances that would be required (outside of a service provider giving each customer their own LB) is quite limited.
Design the network so when you need such network resources you can route to them easily – it is a network service after all, addressable via the network – it doesn’t matter if it lives in a VM or on a physical appliance.
VXLAN
One area that I have not covered with regards to virtualization is something that VXLAN offers, which is make the L2 network more portable between data centers and stuff. This is certainly an attractive feature to have for some customers, especially if perhaps you rely on something like VMware’s SRM to provide fail over.
My own personal experience says VXLAN is not required, nor is SRM. Application configurations for the most part are already in a configuration management platform. Building new resources at a different data center is not difficult (again in my experience most of the applications I have supported this could even be done in advance), in the different IP space and slightly different host names (I leverage the common airportcode.domain for each DC to show where each system is physically located). Replicate the data(use application based replication where available e.g. internal database replication) that is needed(obviously that does not include running VM images) and off you go. Some applications are more complex, most web-era applications are not though.
So, SDN solves a problem for me which doesn’t exist, and never has.
I don’t see it existing in the future for most smaller scale (sub hyper scale) applications unless your network engineers are crazy about over engineering things. I can’t imagine what is involved that takes 2-3 weeks to provision a new network service at Intel. I really can’t. Other than perhaps procuring new equipment, which can be a problem regardless.
Someone still has to buy the hardware
Which leads me into a little tangent. Just because you have cloud doesn’t mean you automatically have unlimited capacity. Even if your Intel, if someone internally built something on their cloud platform(assuming they have one), and said “I need 100,000 VMs each with 24 CPUs and I plan to drive them to 100% utilization 15 hours a day“, even with cloud, I think it is unlikely they have that much capacity provisioned as spare just sitting around(and if they do that is fairly wasteful!).
Someone has to buy and provision the hardware, whether it is in a non cloud setup, or in a cloud setup. Obviously once provisioned into a pool of “cloud” (ugh) it is easier to adapt that system to be used for multiple purposes. But the capacity has to exist, in advance of the service using it. Which means someone is going to spend some $$ and there is going to be some lead time to get the stuff in & set it up. An extreme case for sure, but consider if you need to deploy on the order of 10s of thousands of new servers that lead time may be months, to get the floor space/power/cooling alone.
I remember a story I heard from SAVVIS many years ago, a data center they operated in the Bay Area had a few 10s of thousands of square feet available, and it was growing slow and steady. One day Yahoo! walks in and says I want all of your remaining space. Right Now. And poof it was given to them. There was a data center company Microsoft bought (forgot who now) and there was one/more facilities up in the Seattle area where (I believe) they kicked out the tenants of the company they bought so they could take over the facility entirely(don’t recall how much time they granted the customers to GTFO but I don’t recall hearing them being polite about it).
So often — practically all the time — when I see people talk about cloud they think that the stuff is magical and no matter how much capacity you need it just takes minutes to be made available (Intel slide above). Now if you are a massive service provider like perhaps Amazon, Microsoft, Google – you probably do have 100,000 systems available at any given time. Though the costs of public cloud are ..not something I will dive into again in this post, I have talked about that many times in the past.
Back to Martin’s Presentation
Don’t get me wrong — I think Martin is a really smart guy and created a wonderful thing. My issue isn’t with SDN itself, it’s much more with the marketing and press surrounding it, making it sound like everyone needs this stuff! Buy my gear and get SDN!! You can’t build a network today without SDN!! Even my own favorite switching company Extreme Networks can’t stop talking about SDN.
Networking has been boring for a long time, and SDN is giving the industry something exciting to talk about. Except that it’s not exciting – at least not to me, because I don’t need it.
Anyway one of Martin’s last slides is great as well

Markitechture war with SDN
Self explanatory, I especially like the SDN/python point.
 Conclusion
I see SDN as a great value primarily for service providers and large scale operations at this point. Especially in situations where providers are provisioning dedicated network resources for each customer(network virtualization here works great too).
At some point, perhaps when SDN matures more and it becomes more transparent, then mere mortals will probably find it more useful. As Martin says in one of his first slides, SDN is not for customers(me?), it’s for implementers (that may be me too depending on what he means there, but I think it’s more for the tools builders, people who make things like cloud management interfaces, vCenter programmers etc).
Don’t discount the power/performance benefits of ASICs too much. They exist for a reason, if network manufacturers could build 1U switches to shift 1+Tbps of data around with nothing more than x86 CPUs and have a reasonable power budget I have no doubt they would. Keep this in mind when you think about a network running in software.
If you happen to have a really complicated network then SDN may provide some good value there. I haven’t worked in such an organization, though my first big network(my biggest) was a bit complicated (though it was simpler than the network that it replaced), I learned some good things from that experience and adapted future designs accordingly.
I’ll caveat this all by saying the network design work I have done again has been built for modern web applications, I don’t cover ultra security things like say processing credit cards (that IMO would be a completely physically separate infrastructure for that subsystem to limit the impact of PCI and other compliance things – that being said my first network again did process credit cards directly – this was before PCI compliance existed though, there were critical flaws in the application with regards to credit card security at the time as well). Things are simple, and fairly scalable (not difficult to get to low thousands of systems easily, and that already eclipses the networks of most organizations out there by a big margin).
I believe if your constantly making changes to your underlying L2/L3 network (other than say perhaps adding physical devices to support more capacity) then you probably didn’t design it right to begin with (maybe not your fault). If you need to deploy a new network service, just plug it in and go..
For myself – my role has always been a hybrid of server/storage/network/etc management. So I have visibility into all layers of the application running on the network. So perhaps that makes me better equipped to design things in a way vs. someone who is in a silo and has no idea what the application folks are doing.
Maybe an extreme example but now that I wrote that I remember back many years ago, we had a customer who was a big telco, and their firewall rule change process was once a month a dozen or more people from various organizations(internal+external) get on a conference call to co-ordinate firewall rule changes(and to test connectivity post changes). It was pretty crazy to see. You probably would of had to get the telco’s CEO approval to get a firewall change in that was outside that window!
Before I go let me give a shout out to my favorite L3 switching fault tolerance protocol: ESRP.
I suppose the thing I hesitate most about this post, is paranoid around missing some detail which invalidates every network design I’ve ever done and makes me look like even more of an idiot than I already am!! Though I have talked with enough network people over the years that I don’t believe that will happen…
If you’re reading this and are intimately familiar with an organization that takes 2-3 weeks to spin up a network service I’d like to hear from you (publicly or privately) as to the details around what specifically takes the bulk of that time. Anonymous is fine too, I won’t write anything on it if you don’t want me to. I suspect the bulk of the time is red tape – processes, approvals etc..and not related to the technology.
So, thanks Martin for answering my questions at the conference last week! (I wonder if he will read this…some folks have google alerts for things that are posted and stuff). If you are reading this and you are wondering – yes I really have been a VMware customer for 14 years – going back to pre 1.0 days when I was running VMware on top of Linux. I still have my CD of Vmware 1.0.2 around here somewhere — I think that was the first available physical media distributed. Though my loyalty to VMware has eroded significantly in recent years for various reasons.



{kind=link}