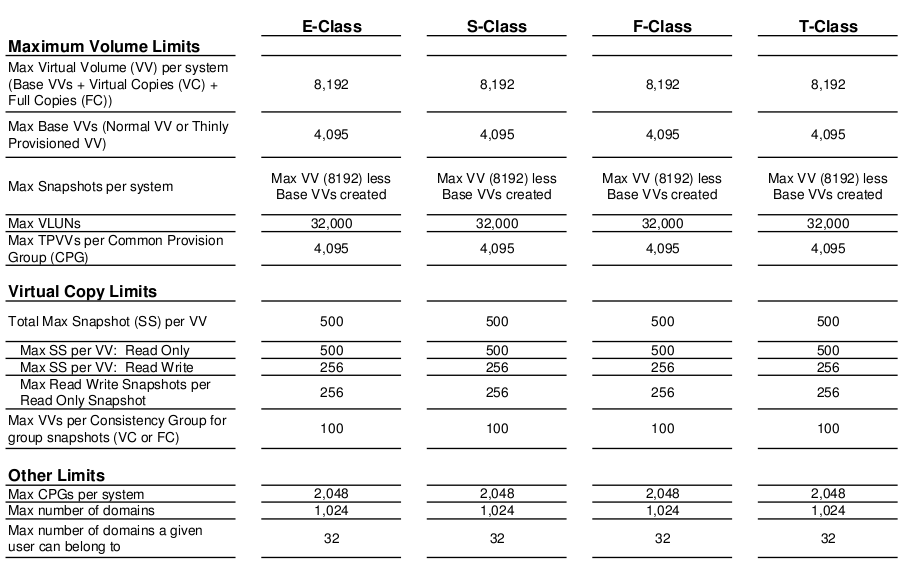
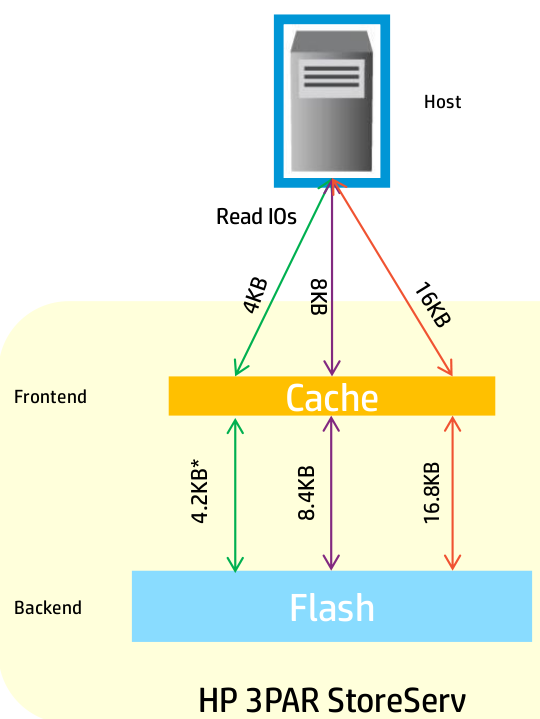
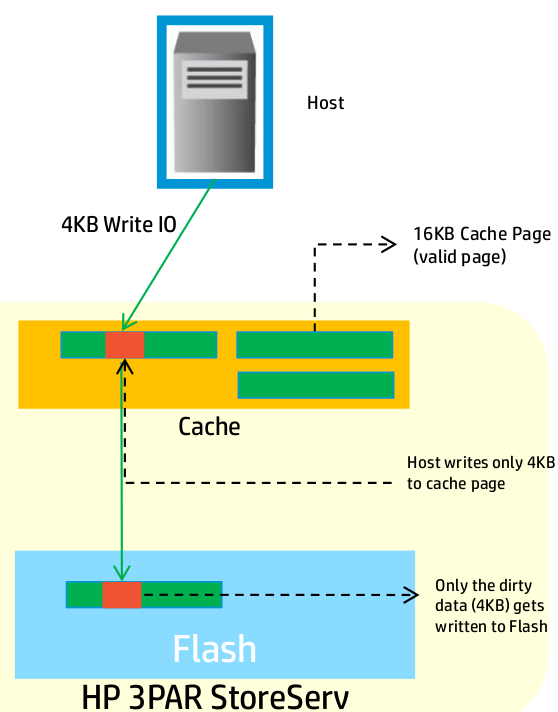
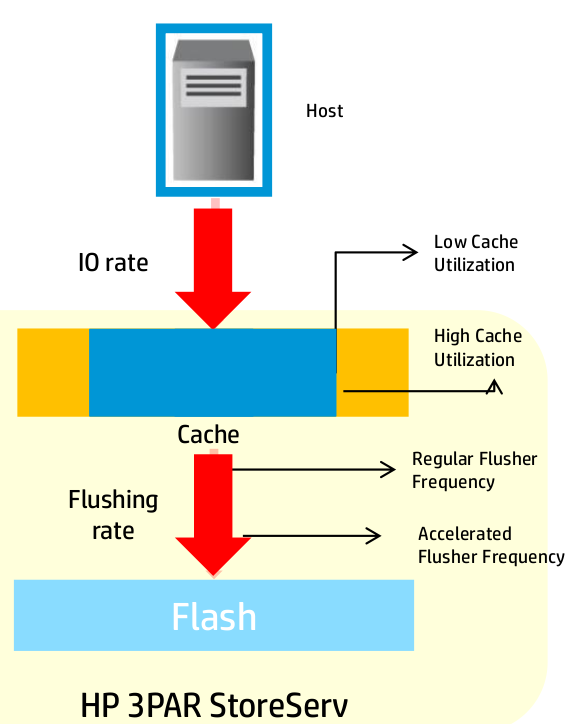
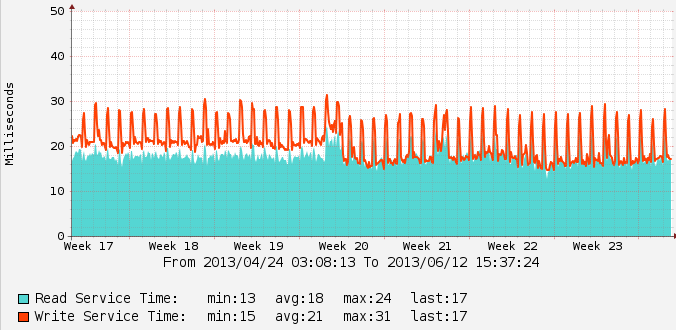
Travel to HP Storage Tech Day/Nth Generation Symposium was paid for by HP; however, no monetary compensation is expected nor received for the content that is written in this blog.
On Monday I attended a private little HP Storage Tech Day event here in Anaheim for a bunch of bloggers. They also streamed it live, and I believe the video is available for download as well.
I wrote a sizable piece on the 3PAR topics which were covered in the morning, here I will try to touch on the other HP Storage topics.
HP StoreAll + Express Query
StoreAll Platform
HP doesn’t seem to talk about this very much, and as time goes on I have understood why. It’s not a general purpose storage system, I suppose it never has been (though I expect Ibrix tried to make it one in their days of being independent). They aren’t going after NetApp or EMC’s enterprise NAS offerings. It’s not a platform you want to run VMs on top of. Not a platform you want to run databases on top of. It may not even be a platform you want to run HPC stuff on top of. It’s built for large scale bulk file and object storage.
They have tested scalability to 1,024 nodes and 16PB within a single name space. The system can scale higher, that’s just the tested configuration. They say it can scale non disruptively and re-distribute existing data across new resources as those resources are added to the system. StoreAll can go ultra dense with near line SAS drives going up to roughly 500 drives in a rack (without any NAS controllers).
It’s also available in a gateway version which can go in front of 3PAR, EVA and XP storage.
They say their main competition is EMC Isilon, which is another scale-out offering.
HP seems to have no interest in publishing performance metrics, including participating in SPECsfs (a benchmark that sorely lacks disclosures). The system has no SSD support at all.
The object store and file store, if I am remembering right, are not shared. So you have to access your data via a consistent means. You can’t have an application upload data to an object store then give a user the ability to browse to that file using CIFS or NFS. To me this would be an important function to serve if your object and file stores are in fact on the same platform.
By contrast, I would expect a scale out object store to do away with the concept of disk-based RAID and go with object level replication instead. Many large scale object stores do this already. I believe I even read in El Reg that HP Labs is working on something similar(nothing around that was mentioned at the event). In StoreAll’s case they are storing your objects in RAID, but denying you the flexibility to access them over file protocols which is unfortunate.
From a competitive standpoint, I am not sure what features HP may offer that are unique from an object storage perspective that would encourage a customer to adopt StoreAll for that purpose. If it were me I would probably take a good hard look at something like Red Hat Storage server(I would only consider RHSS for object storage, nothing else) or other object offerings if I was to build a large scale object store.
Express Query (below) cannot currently run on object stores at this time, it will with a future release though.
Express Query
This was announced a while back, which is what seems to be a SQL database of sorts that is running on the storage controllers, with some hooks into the file system itself. It provides indexes of common attributes as well as gives the user the ability to provide custom attributes to search by. As a result, obviously you don’t have to search the entire file system to find files that match these criteria.
It is exposed as a Restful API which has it’s ups and downs. As an application developer you can take this and tie it into your application. It returns results in JSON format (developer friendly, hostile to users such as myself – remember my motto “if it’s not friends with grep or sed, it’s not friends with me”).
The concept is good, perhaps the implementation could use some more work, as-is it seems very developer oriented. There is a java GUI app which you can run that can help you build and submit a query to the system which is alright. I would like to see a couple more things:
- A website on the storage system (with some level of authentication – you may want to leave some file results open to the “public” if those are public shares) that allows users to quickly build a query using a somewhat familiar UI approach.
- A drop in equivalent to the Linux command find. It would only support a subset of functionality but you could get a large portion of that functionality I believe fairly simply with this. The main point being don’t make the users have to make significant alterations to their processes to adopt this feature, it’s not complicated, lower the bar for adoption.
To HP’s credit they have written some sort of plugin to the Windows search application that gives windows users the ability to easily use Express Query(I did not see this in action). Nothing so transparent exists for Linux though.
My main questions though were things HP was unable to answer. I expected more from HP on this front in general. I mean specifically around competitive info. In many cases they seem to rely on the publicly available information on the competition’s platforms – maybe limited to the data that is available on the vendor website. HP is a massive organization with very deep pockets – you may know where I’m going here. GO BUY THE PRODUCTS! Play with them, learn how they work, test them, benchmark them. Get some real world results out of the systems. You have the resources, you have the $$. I can understand back when 3PAR was a startup company they may not be able to go around buying arrays from the competition to put them through their paces. Big ‘ol HP should be doing that on a regular basis. Maybe they are — if they are — they don’t seem to be admitting that their data is based on that(in fact I’ve seen a few times where they explicitly say the information is only from data sheets etc).
Another approach might be, if HP lacks the man power to run such tests and stuff, to have partners or customers do it for them. Offer to subsidize the cost of some purchase by some customer of some competitive equipment in exchange for complete open access to competitive information as a result of using such a system. Or fully cover the cost.. HP has the money to make it happen. It would be really nice to see..
So in regards to Express Query I had two main questions about performance related to the competition. HP says they view Isilon as the main competition for StoreAll. A couple of years back Isilon started offering a product(maybe it is standard across the board now I am not sure) where they stored the metadata in SSD. This would dramatically accelerate these sorts of operations, without forcing the user to change their way of doing things. Lowers the bar of adoption. Now price wise it probably costs more, StoreAll does not have any special SSD support whatsoever. But I would be curious as to the performance in general comparing Isilon’s accelerated metadata vs HP Express query. Obviously Express Query is more flexible with it’s custom meta data fields and tagging etc, so for specific use cases there is no comparison. BUT.. for many things I think both would work well..
Along the same notes – back when I was a BlueArc customer one of their big claims was their FPGA accelerated file system had lightning fast meta data queries. So how does Express Query performance compare to something like that? I don’t know, and got no answer from HP.
Overall
Overall, I’d love it if HP had a more solid product in this area, it feels like whoever I talk to that they have just given up trying to be competitive with an in house enterprise file offering(they do have a file offering based on Windows storage server but I don’t really consider that in the same ballpark since they are just re-packaging someone else’s product). HP StoreAll has it’s use cases and it probably does those fairly well, but it’s not a general purpose file platform, and from the looks of things it’s never going to be one.
Software Defined Storage
Just hearing the phrase Software Defined <anything> makes me shudder. Our friends over at El Reg have started using the term hype gasm when referring to Software Defined Networking. I believe the SDS space is going to be even worse, at least for a while.
(On a side note there was an excellent presentation on SDN at the conference today which I will write about once I have the password to unlock the presentations so I can refresh my memory on what was on the slides – I may not get the password until Friday though)
As of today, the term is not defined at all. Everyone has their own take on it, and that pisses me off as a technical person. From a personal standpoint I am in the camp leaning more towards some separation of data and control planes ala SDN, but time will tell what it ends up being.
I think Software Defined Storage, if it is not some separation of control and data plan instead could just be a subsystem of sorts that provides storage services to anything that needs them. In my opinion it doesn’t matter if it’s from a hardware platform such as 3PAR, or a software platform such as a VSA. The point is you have a pool of storage which can be provisioned in a highly dynamic & highly available manor to whatever requests it. At some point you have to buy hardware – having infrastructure that is purpose built, and shared is obviously a commonly used strategy today. The level of automation and API type stuff varies widely of course.
The point here is I don’t believe the Software side of things means it has to be totally agnostic as to where it runs – it just needs a standard interfaces in which anything can address it(APIs, storage protocols etc). It’s certainly nice to have the ability to run such a storage system entirely as a VM, there are use cases for that for certain. But I don’t want to limit things to just that. So perhaps more focus on the experience the end user gets rather than how you get there. Something like that.
StoreVirtual
HP’s take on it is of course basically storage resources provisioned through VSAs. Key points being:
- Software only (they also offer a hardware+software integrated package so…)
- Hypervisor agnostic (right now that includes VMware and Hyper-V so not fully agnostic!)
- Federated
I have been talking with HP off and on for months now about how confusing I find their messaging around this.
In one corner we have:
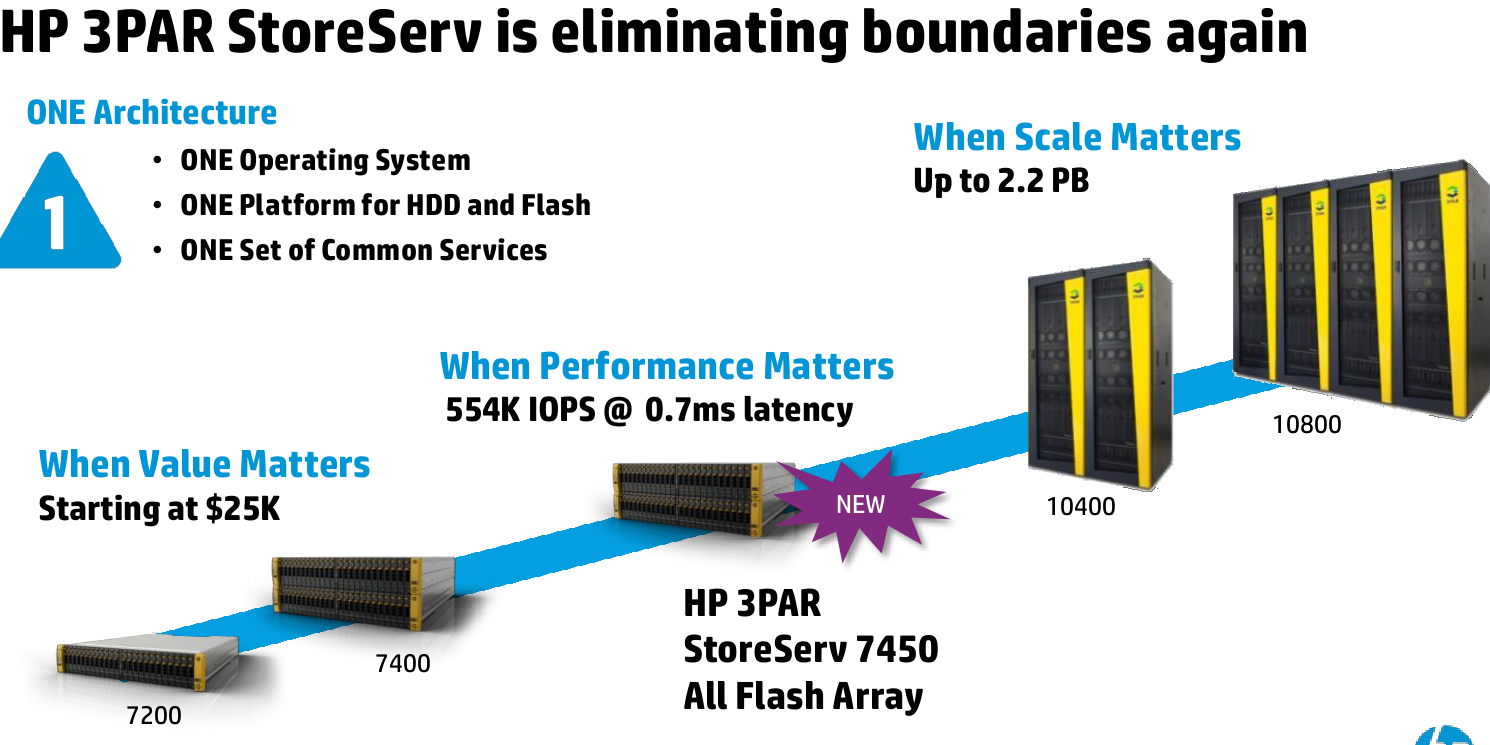
3PAR Eliminating boundaries.
In the other corner we have
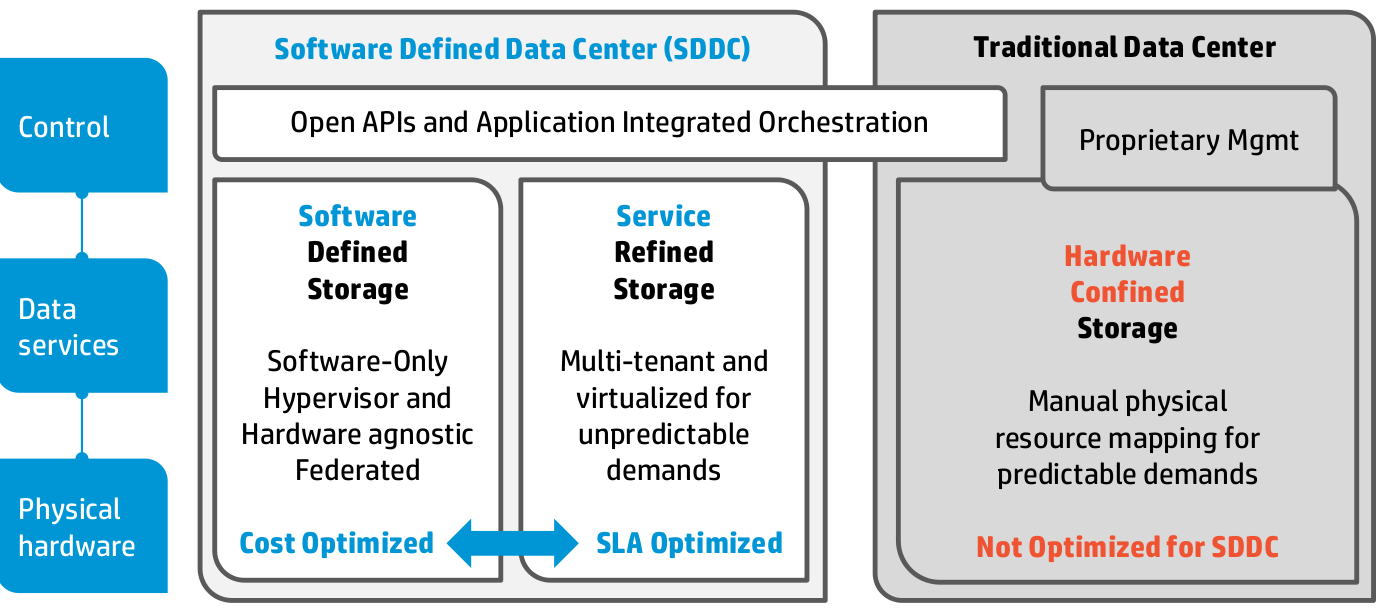
Software Defined Data Center – Storage (3PAR is implied to be Service Refined Storage – Storevirtual is Cost Optimized)

Store Virtual key features
Mixed messages
(thinking from a less technical user’s perspective – specifically thinking back to some of my past managers who thought they knew what they were doing when they really didn’t – I’m looking out for other folks like me in the field who don’t want their bosses to get the wrong message when they see something like this)
What’s the difference between 3PAR’s SLA Optimized storage when value matters, and StoreVirtual Cost Optimized?
Hardware agnostic and federated sounds pretty cool, why do I need 3PAR when I can just scale out with StoreVirtual? Who needs fancy 3PAR Peer Persistence (fancy name for transparent full array high availability) when I have built in disaster recovery on the StoreVirtual platform?
Expensive 3PAR software licensing? StoreVirtual is all inclusive! The software is the same right? I can thin provision, I can snapshot, I can replicate, I can peer motion between StoreVirtual systems. I have disaster recovery, I have iSCSI, I have Fibre channel. I have scale out and I have a fancy shared-nothing design. I have Openstack integration. I have flash support, I have tiering, I have all of this with StoreVirtual. Why did HP buy 3PAR when they already have everything they need for the next generation of storage?
(stepping back into technical role now)
Don’t get me wrong – I do see some value in the StoreVirtual platform! It’s really flexible, easy to deploy, and can do wonders to lower costs in certain circumstances – especially branch office type stuff. If you can deploy 2-3 VM servers at an edge office and leverage HA shared storage without a dedicated array I think that is awesome.
But the message for data center and cloud deployments – do I run StoreVirtual as my primary platform or run 3PAR ? The messaging is highly confusing.
My idea to HP on StoreVirtual vs. 3PAR
I went back and forth with HP on this and finally, out of nowhere I had a good idea which I gave to them and it sounds like they are going to do something with it.
So my idea was this – give the customer a set of questions, and based on the answers of those questions HP would know which storage system to recommend for that use case. Pretty simple idea. I don’t know why I didn’t come up with it earlier (perhaps because it’s not my job!). But it would go a long way in cleaning up that messaging around which platform to use. Perhaps HP could take the concept even further and update the marketing info to include such scenarios (I don’t know how that might be depicted, assuming it can be done so in a legible way).
When I gave that idea, several people in the room liked it immediately, so that felt good 🙂
 HP StoreOnce
(This segment of the market I am not well versed in at all, so my error rate is likely to go up by a few notches)
HP StoreOnce is of course their disk-based scale-out dedupe system developed by HP Labs. One fairly exciting offering in this area that was recently announced at HP Discover is the StoreOnce VSA. Really nice to see the ability to run StoreOnce as a VM image for small sites.
They spent a bunch of time talking about how flexible the VSA is, how you can vMotion it and Storage vMotion it like it was something special. It’s a VM, it’s obvious you should be able to do those things without a second thought.
StoreOnce is claimed to have a fairly unique capability of being able to replicate between systems without ever re-hydrating the data. They also claim a unique ability to be the first platform to offer real high availability. In a keynote session by David Scott (which I will cover in more depth in a future post once I get copies of those presentations) he mentioned that Data Domain as an example, if a DD controller fails during a backup or a restore operation the operation fails and must be restarted after the controller is repaired.
This surprised me – what’s the purpose of dual controllers if not to provide some level of high availability? Again forgive my ignorance on the topic as this is not an area of the storage industry I have spent much time at all in.
HP StoreOnce however can recover from this without significant downtime. I believe the backup or restore job still must be restarted from scratch, but you don’t have to wait for the controller to be repaired to continue with work.
HP has claimed for at least the past year to 18 months now that their performance far surpasses everyone else by a large margin, they continued those claims this week. I believe I read at one point from their competition that the claims were not honest in that I believe the performance claims was from a clustered StoreOnce system which has multiple de-dupe domains(meaning no global dedupe on the system as a whole), and it was more like testing multiple systems in parallel against a single data domain system(with global dedupe). I think there were some other caveats as well but I don’t recall specifics (this is from stuff I want to say I read 18-20 months ago).
In any case, the product offering seems pretty decent, is experiencing a good amount of growth and looks to be a solid offering in the space. Much more competitive in the space than StoreAll is, probably not quite as competitive as 3PAR, perhaps a fairly close 2nd as far as strength of product offering.
Next up, converged storage management and Openstack with HP. Both of these topics are very light relative to the rest of the material, I am going to go back to the show room floor to see if I can dig up more info.