Travel to HP Storage Tech Day/Nth Generation Symposium was paid for by HP; however, no monetary compensation is expected nor received for the content that is written in this blog.
I can feel the flames I might get for this post but I’m going to write about it anyway because I found it interesting. I have written about Cisco UCS in the past(very limited topics), have never been impressed with it, and really at the end of the day I can’t buy Cisco on principle alone – doesn’t matter if it was $1, I can’t do it (in part because I know that $1 cost would come by screwing over many other customers to make that price possible for me).
Cisco has gained a lot of ground in the blade market since they came out with this system a few years ago and I think they are in 3rd place, maybe getting close to 2nd (last I saw 2nd was a very distant position behind HP).
So one of the keynotes (I guess you can call it that? it was on the main stage) was someone from HP who says they recently re-joined HP earlier in the year(or perhaps last year) after spending a couple of years at Cisco both selling and training their partners on how to sell UCS to customers. So obviously that was interesting to me, hearing this person’s perspective on the platform. There was a separate break-out session on this topic that went into more detail but it was NDA-only so I didn’t attend.
I suppose what was most striking is HP going out of their way to compare themselves against UCS, that says a lot right there. They never mentioned Dell or IBM stuff, just Cisco. So Cisco obviously has gotten some good traction (as sick as that makes me feel).
Out of band management
HP claims that Cisco has no out of band management on UCS, there are primary and backup data paths but if those are down then you are SOL. HP obviously has (optionally) redundant out of band management on their blade system.
I love out of band management myself, especially full lights out. My own HP VMware servers have dedicated in-band(1GbE) as well as the typical iLO out of band management interfaces. This is on top of the 4x10GbE and 2x4Gbps FC for storage. Lots of connectivity. When I was having issues with our Qlogic 10GbE NICs last year this came in handy.
Fault domains
This can be a minor issue – mainly an implementation one. Cisco apparently allows UCS to have a fault domain of up to 160 servers, vs HP is 16(one chassis). So you can, of course, lower your fault domain on UCS if you think about this aspect of things — how many customers realize this and actually do something about it? I don’t know.
HP Smart Update Manager
I found this segment quite interesting. HP touts their end to end updates mechanism which includes:
- Patch sequencing
- Driver + Firmware management
- Unified service pack (1 per quarter)
HP claims Cisco has none of these, they cannot sequence patches, their management system does not manage drivers (it does manage firmware), and the service packs are not unified.
At this point the HP person pointed out a situation a customer faced recently where they used the UCS firmware update system to update the firmware on their platform. They then rebooted their ESX systems(I guess for the firmware to take effect), and the systems could no longer see the storage. It took the customer on the line with Cisco, VMware, and the storage company 20 hours until they figured out the problem was the drivers were out of sync with the firmware which was the reason for the downtime.
I recall a few years ago another ~20 hour outage on a Cisco UCS platform at a sizable company in Seattle for similar reasons, I don’t know why in both cases it took so long to resolve, in the Seattle case there was a firmware bug (known bug) that was causing link flapping and as a result massive outage because I believe storage was not very forgiving to that. Fortunately Cisco had a patch but it took em ~20 hours of hard downtime to figure out the problem.
I’m sure there are similar stories for the HP end of things too… I have heard of some nasty issues with flex fabric and virtual connect. There is one feature I like about flexfabric and virtual connect, that is the chassis-based MAC/WWN assignments. Everything else they can keep. I don’t care about converged ethernet, I don’t care about reducing my cable count(having a few extra fibre cables for storage per chassis really is nothing)…
Myself the only outages I have had that have lasted that long have been because of application stack failures, I think the longest infrastructure related outage I’ve been involved with in the past 15 years was roughly six, maybe eight hours. I have had outages where it took longer than 20 hours to recover fully from – but the bulk of that time the system was running we just had recovery steps to perform. Never had a 20 hour outage where 15 hours into the thing nobody has any idea what is the problem or how to fix it.
Longest outage ever though was probably ~48-72 hours – and that was entirely application stack failure. That was the time we got all the senior software developers and architects in a room and asked them How do we fix this? and they gave us blank stares and said We don’t know, it’s not supposed to do this. Not a good situation to be in!
Anyway, back on topic.
HP says since December 2011 they have released 9 critical updates, and Cisco have released 38 critical updates.
The case for intelligent compute
I learned quite a bit from this segment as well. Back in 2003 the company I was at was using HP and Compaq gear, it ran well though obviously was pretty expensive. Everything was DL360s, some DL380s, some DL580s. When it came time to do a big data center refresh we wanted to use SATA disks to cut some costs, so we ended up going with a white box company instead of HP (this was before HP had the DL100 series). I learned a lot from that experience, and was very happy to return to HP as a customer at my next company(though I certainly realize given the right workload HP’s premium may not be worth it – but for highly consolidated virtualized stuff I really don’t want to use anything else). The biggest issue I had with white box stuff was bad ram. It seemed to be everywhere. Not long after we started deployment I started using the Cerberus Test Suite to burn in our systems which caught a lot of it. Cerberus is awesome if you haven’t tried it. I even used it on our HP gear mainly to drive CPU and memory to 100% usage to burn them in (no issues found).
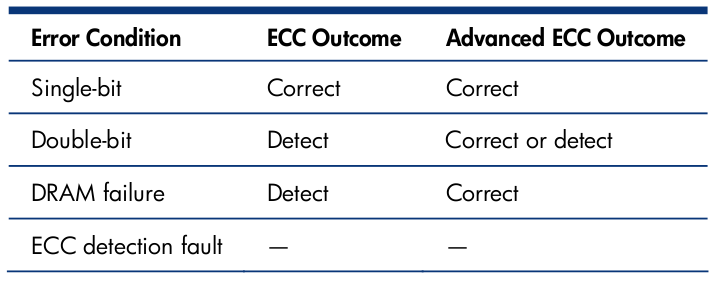
HP Advanced ECC Outcomes
HP has a technology called Advanced ECC, which they’ve had since I believe 1996, and is standard on at least all 300-series servers and up. 10 years ago when our servers rarely had more than 2GB of memory in them(I don’t think we went 64-bit until at least 2005), Advanced ECC wasn’t a huge deal, 2GB of memory is not much. Today, with my servers having 384GB ..I really refuse to run any high memory configuration without something like that. IBM has ChipKill, which is similar. Dell has nothing in this space. Not sure about Cisco(betting they don’t, more on that in a moment).
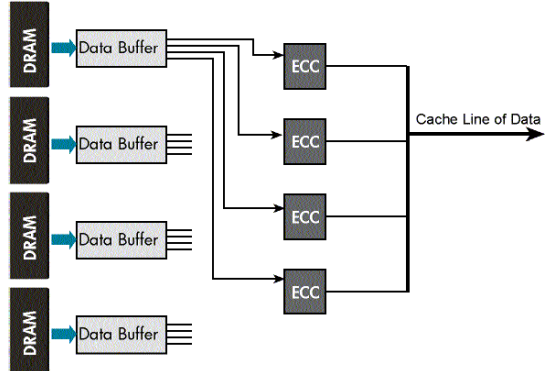
HP Advanced ECC
HP talked about their massive numbers of sensors with some systems(I imagine the big ones!) having up to 1,600 sensors in them. (Here is a neat video on Sea of Sensors from one of the engineers who built them – one thing I learned is the C7000 chassis has 104 different fan speeds for maximum efficiency) HP introduced pre failure alerting in 1995, and has had pre failure warranties for a long time (perhaps back to 1995 as well). They obviously have complete hypervisor integration (one thing I wasn’t sure of myself until recently, while upgrading our servers one of the new sticks went bad and an alert popped up in vCenter and I was able to evacuate the host and get the stick replaced without any impact — this failure wasn’t caught by burn-in, just regular processing, I didn’t have enough spare capacity to take out too many systems to dedicate to burn-in at that point).
What does Cisco have? According to HP not much. Cisco doesn’t treat the server with much respect apparently, they treat it as something that can fail and you just get it replaced or repaired at that point.
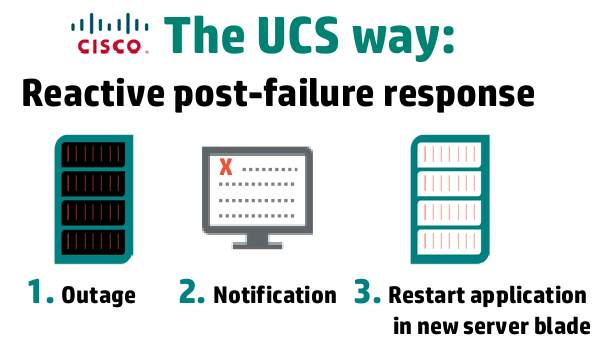
UCS: Post failure response
That model reminds me of what I call built to fail which is the model that public clouds like Amazon and stuff run on. It’s pretty bad. Though at least in Cisco’s case the storage is shared and the application can be restarted on another system easily enough, public cloud you have to build a new system and configure it from scratch.
The point here is obviously, HP works hard to prevent the outage in the first place, Cisco doesn’t seem to care.
Simplicity Matters
I’ll just put the full slide here there’s not a whole lot to cover. HP’s point here is the Cisco way is more complicated and seems angled to drive more revenue for the network. HP is less network oriented, and they show you can directly connect the blade chassis to a 3PAR storage system(s). I think HP’s diagram is even a bit too complicated for all but the largest setups you could easily eliminate the distribution layer.
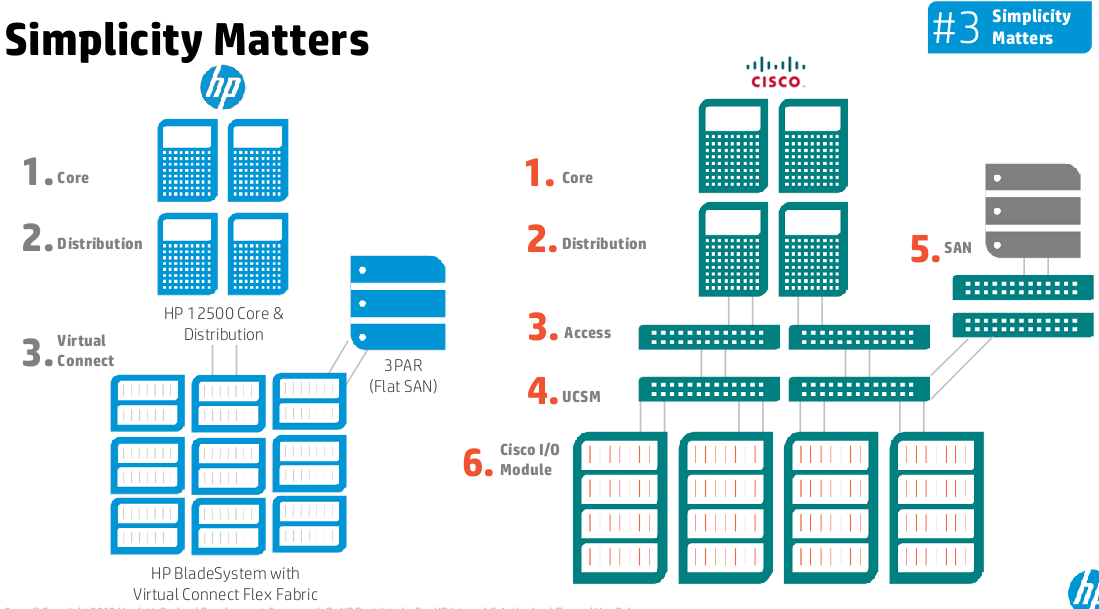
BladeSystem vs UCS: Simplicity matters
The cost of the 17th server
I found this interesting as well, Cisco goes around telling folks that their systems are cheaper, but they don’t do an apples to apples comparison, they use a Smart Play Bundle, not a system that is built to scale.
HP put a couple of charts up showing the difference in cost between the two solutions.
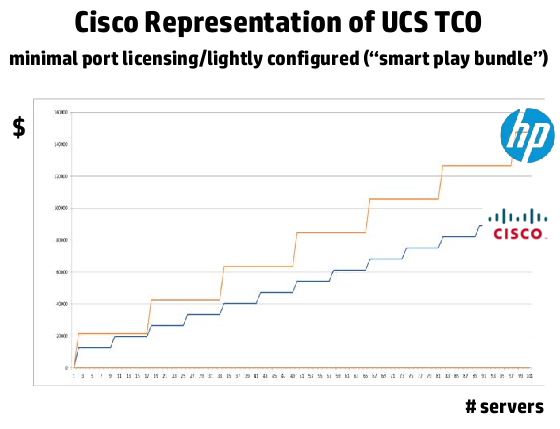
BladeSystem vs UCS TCO: UCS Smart Play bundle
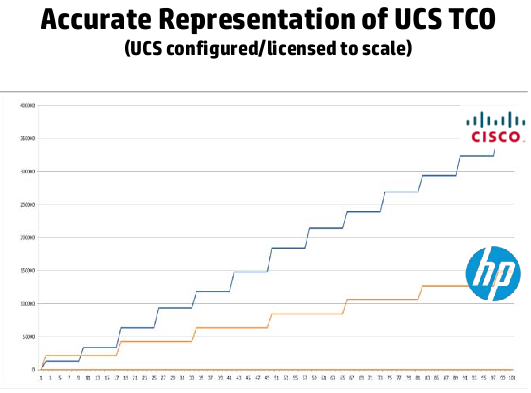
BladeSystem vs UCS TCO: UCS Built to scale
Portfolio Matters
Lastly HP went into some depth on comparing the different product portfolios and showed how Cisco was lacking in pretty much every area whether it was server coverage, storage coverage, blade networking options, software suites and the integration between them.
They talked about how Cisco has one way to connect networking to UCS, HP has many whether it is converged ethernet(similar to Cisco), or regular ethernet, native Fibre channel, Infiniband, and even SAS to external disk enclosures. The list goes on and on for the other topics but I’m sure you get the point. HP offers more options so you can build a more optimal configuration for your application.
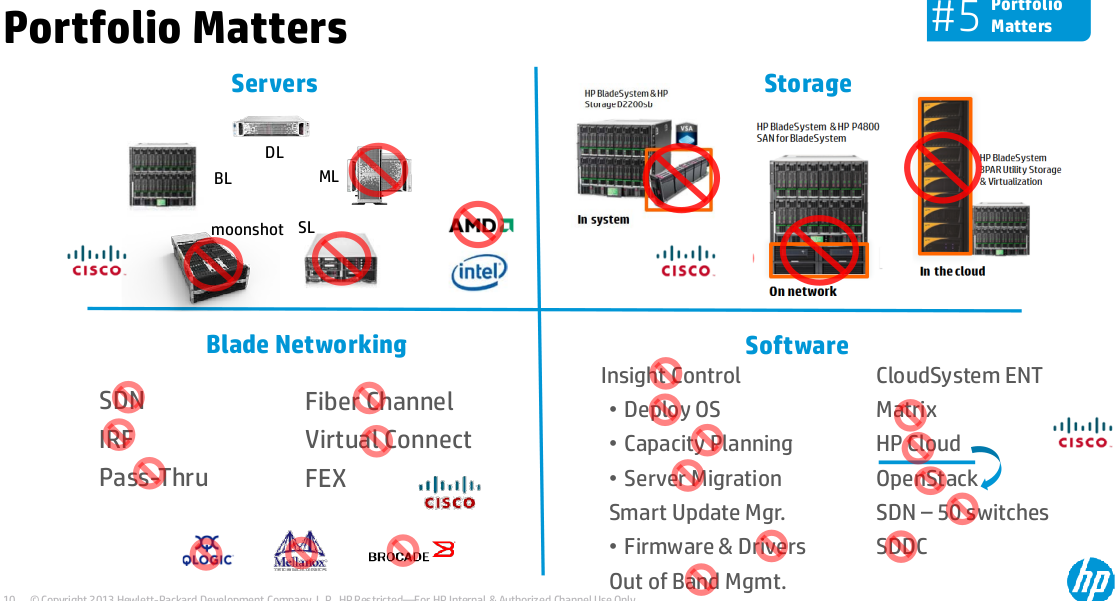
BladeSystem vs UCS: Portfolio matters
Then they went into analyst stuff and I took a nap.
In reviewing the slide deck they do mention Dell once.. in the slide, not by the speaker –

HP vs Dell in drivers/firmware management
By attending this I didn’t learn anything that would affect my purchasing in the future, as I mentioned I won’t buy Cisco for any reason already. But it was still interesting to hear about.

