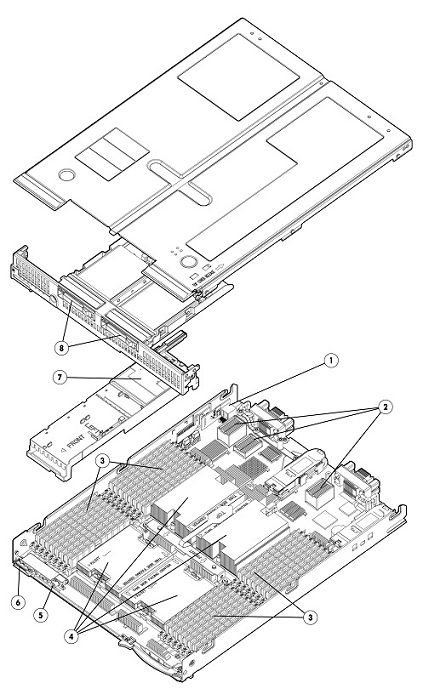
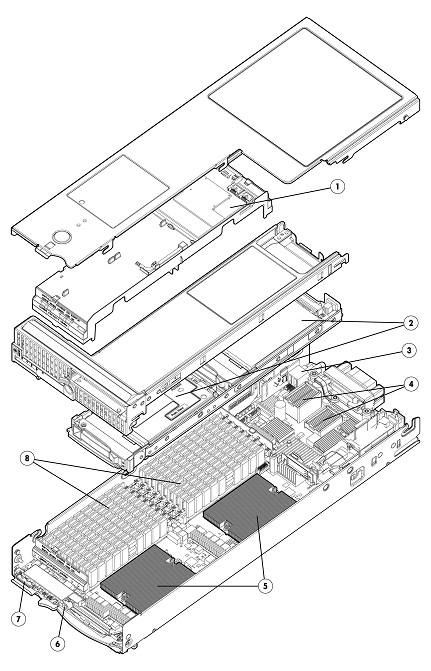
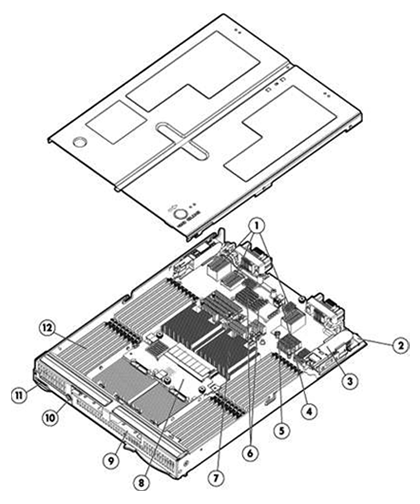
You know I’m a big fan of the AMD Opteron 6100 series processor, also a fan of the HP c class blade system, specifically the BL685c G7 which was released on June 21st. I was and am very excited about it.
It is interesting to think, it really wasn’t that long ago that blade systems still weren’t all that viable for virtualization primarily because they lacked the memory density, I mean so many of them offered a paltry 2 or maybe 4 DIMM sockets. That was my biggest complaint with them for the longest time. About a year or year and a half ago that really started shifting. We all know that Cisco bought some small startup a few years ago that had their memory extender ASIC but well you know I’m not a Cisco fan so won’t give them any more real estate in this blog entry, I have better places to spend my mad typing skills.
A little over a year ago HP released their Opteron G6 blades, at the time I was looking at the half height BL485c G6 (guessing here, too lazy to check). It had 16 DIMM sockets, that was just outstanding. I mean the company I was with at the time really liked Dell (you know I hate Dell by now I’m sure), I was poking around their site at the time and they had no answer to that(they have since introduced answers), the highest capacity half height blade they had at the time anyways was 8 DIMM sockets.
I had always assumed that due to the more advanced design in the HP blades that you ended up paying a huge premium, but wow I was surprised at the real world pricing, more so at the time because you needed of course significantly higher density memory modules in the Dell model to compete with the HP model.
Anyways fast forward to the BL685c G7 powered by the Opteron 6174 processor, a 12-core 2.2Ghz 80W processor.
Load a chassis up with eight of those:
- 384 CPU cores (860Ghz of compute)
- 4 TB of memory (512GB/server w/32x16GB each)
- 6,750 Watts @ 100% load (feel free to use HP dynamic power capping if you need it)
I’ve thought long and hard over the past 6 months on whether or not to go 8GB or 16GB, and all of my virtualization experience has taught me in every case I’m memory(capacity) bound, not CPU bound. I mean it wasn’t long ago we were building servers with only 32GB of memory on them!!!
There is indeed a massive premium associated with going with 16GB DIMMs but if your capacity utilization is anywhere near the industry average then it is well worth investing in those DIMMs for this system, your cost of going from 2TB to 4TB of memory using 8GB chips in this configuration makes you get a 2nd chassis and associated rack/power/cooling + hypervisor licensing. You can easily halve your costs by just taking the jump to 16GB chips and keeping it in one chassis(or at least 8 blades – maybe you want to split them between two chassis I’m not going to get into that level of detail here)
Low power memory chips aren’t available for the 16GB chips so the power usage jumps by 1.2kW/enclosure for 512GB/server vs 256GB/server. A small price to pay, really.
So onto the point of my post – testing the limits of virtualization. When your running 32, 64, 128 or even 256GB of memory on a VM server that’s great, you really don’t have much to worry about. But step it up to 512GB of memory and you might just find yourself maxing out the capabilities of the hypervisor. At least in vSphere 4.1 for example you are limited to only 512 vCPUs per server or only 320 powered on virtual machines. So it really depends on your memory requirements, If your able to achieve massive amounts of memory de duplication(myself I have not had much luck here with linux it doesn’t de-dupe well, windows seems to dedupe a lot though), you may find yourself unable to fully use the memory on the system, because you run out of the ability to fire up more VMs ! I’m not going to cover other hypervisor technologies, they aren’t worth my time at this point but like I mentioned I do have my eye on KVM for future use.
Keep in mind 320 VMs is only 6.6VMs per CPU core on a 48-core server. That to me is not a whole lot for workloads I have personally deployed in the past. Now of course everybody is different.
But it got me thinking, I mean The Register has been touting off and on for the past several months every time a new Xeon 7500-based system launches ooh they can get 1TB of ram in the box. Or in the case of the big new bad ass HP 8-way system you can get 2TB of ram. Setting aside the fact that vSphere doesn’t go above 1TB, even if you go to 1TB I bet in most cases you will run out of virtual CPUs before you run out of memory.
It was interesting to see, in the “early” years the hypervisor technology really exploiting hardware very well, and now we see the real possibility of hitting a scalability wall at least as far as a single system is concerned. I have no doubt that VMware will address these scalability issues it’s only a matter of time.
Are you concerned about running your servers with 512GB of ram? After all that is a lot of “eggs” in one basket(as one expert VMware consultant I know & respect put it). For me at smaller scales I am really not too concerned. I have been using HP hardware for a long time and on the enterprise end it really is pretty robust. I have the most concerns about memory failure, or memory errors. Fortunately HP has had Advanced ECC for a long time now(I think I remember even seeing it in the DL360 G2 back in ’03).

HP’s Advanced ECC spreads the error correcting over four different ECC chips, and it really does provide quite robust memory protection. When I was dealing with cheap crap white box servers the #1 problem BY FAR was memory, I can’t tell you how many memory sticks I had to replace it was sick. The systems just couldn’t handle errors (yes all the memory was ECC!).
By contrast, honestly I can’t even think of a time a enterprise HP server failed (e.g crashed) due to a memory problem. I recall many times the little amber status light come on and I log into the iLO and say, oh, memory errors on stick #2, so I go replace it. But no crash! There was a firmware bug in the HP DL585G1s I used to use that would cause them to crash if too many errors were encountered, but that was a bug that was fixed years ago, not a fault with the system design. I’m sure there have been other such bugs here and there, nothing is perfect.
Dell introduced their version of Advanced ECC about a year ago, but it doesn’t (or at least didn’t maybe it does now) hold a candle to the HP stuff. The biggest issue with the Dell version of Advanced ECC was if you enabled it, it disabled a bunch of your memory sockets! I could not get an answer out of Dell support at the time at least why it did that. So I left it disabled because I needed the memory capacity.
So combine Advanced ECC with ultra dense blades with 48 cores and 512GB/memory a piece and you got yourself a serious compute resource pool.
Power/cooling issues aside(maybe if your lucky you can get in to SuperNap down in Vegas) you can get up to 1,500 CPU cores and 16TB of memory in a single cabinet. That’s just nuts! WAY beyond what you expect to be able to support in a single VMware cluster(being that your limited to 3,000 powered on VMs per cluster – the density would be only 2 VMs/core and 5GB/VM!)
And if you manage to get a 47U rack, well you can get one of those c3000 chassis in the rack on top of the four c7000 and get another 2TB of memory and 192 cores. We’re talking power kicking up into the 27kW range in a single rack! Like I said you need SuperNap or the like!
Think about that for a minute, 1,500 CPU cores and 16TB of memory in a single rack. Multiply that by say 10 racks. 15,000 CPU cores and 160TB of memory. How many tens of thousands of physical servers could be consolidated into that? A conservative number may be 7 VMs/core, your talking 105,000 physical servers consolidated into ten racks. Well excluding storage of course. Think about that! Insane! I mean that’s consolidating multiple data centers into a high density closet! That’s taking tens to hundreds of megawatts of power off the grid and consolidating it into a measly 250 kW.
I built out, what was to me some pretty beefy server infrastructure back in 2005, around a $7 million project. Part of it included roughly 300 servers in roughly 28 racks. There was 336kW of power provisioned for those servers.
Think about that for a minute. And re-read the previous paragraph.
I have thought for quite a while because of this trend, the traditional network guy or server guy is well, there won’t be as many of them around going forward. When you can consolidate that much crap in that small of a space, it’s just astonishing.
One reason I really do like the Opteron 6100 is the cpu cores, just raw cores. And they are pretty fast cores too. The more cores you have the more things the hypervisor can do at the same time, and there is no possibilities of contention like there are with hyperthreading. CPU processing capacity has gotten to a point I believe where raw cpu performance matters much less than getting more cores on the boxes. More cores means more consolidation. After all industry utilization rates for CPUs are typically sub 30%. Though in my experience it’s typically sub 10%, and a lot of times sub 5%. My own server sits at less than 1% cpu usage.
Now fast raw speed is still important in some applications of course. I’m not one to promote the usage of a 100 core CPU with each core running at 100Mhz(10Ghz), there is a balance that has to be achieved, and I really do believe the Opteron 6100 has achieved that balance, I look forward to the 6200(socket compatible 16 core). Ask anyone that has known me this decade I have not been AMD’s strongest supporter for a very long period of time. But I see the light now.