Before I forget again..
Travel to HP Storage Tech Day/Nth Generation Symposium was paid for by HP; however, no monetary compensation is expected nor received for the content that is written in this blog.
So, HP hammered us with a good seven to eight hours of storage related stuff today, the bulk of the morning was devoted to 3PAR and the afternoon covered StoreVirtual, StoreOnce, StoreAll, converged management and some really technical bits from HP Labs.
This post is all about 3PAR. They covered other topics of course but this one took so long to write I had to call it a night, will touch on the other topics soon.
I won’t cover everything since I have covered a bunch of this in the past. I’ll try not to be too repetitive…
I tried to ask as many questions as I could, they answered most .. the rest I’ll likely get with another on site visit to 3PAR HQ after I sign another one of those Nate Disclosure Agreements (means I can’t tell you unless your name is Nate). I always feel guilty about asking questions directly to the big cheeses at 3PAR. I don’t want to take up any of their valuable time…
There wasn’t anything new announced today of course, so none of this information is new, though some of is new to this blog, anyway!
I suppose if there is one major take away for me for this SSD deep dive, is the continued insight into how complex storage really is, and how well 3PAR does at masking that complexity and extracting the most of everything out of the underlying hardware.
Back when I first started on 3PAR in late 2006, I really had no idea what real storage was. As far as I was concerned one dual controller system with 15K disks was the same as the next. Storage was never my focus in my early career (I did dabble in a tiny bit of EMC Clariion (CX6/700) operations work – though when I saw the spreadsheets and visios the main folks used to plan and manage I decided I didn’t want to get into storage), it was more servers, networking etc.
I learned a lot in the first few years of using 3PAR, and to a certain extent you could say I grew up on it. As far as I am concerned being able to wide stripe, or have mesh active controllers is all I’ve ever (really) known. Sure since then I have used a few other sorts of systems. When I see architectures and processes of doing things on other platforms I am often sort of dumbfounded why they do things that way. It’s sometimes not obvious to me that storage used to be really in the dark ages many years ago.
Case in point below, there’s a lot more to (efficient, reliable, scalable, predictable) SSDs than just tossing a bunch of SSDs into a system and throwing a workload at them..
I’ve never tried to proclaim I am a storage expert here(or anywhere) though I do feel I am pretty adept at 3PAR stuff at least, which wasn’t a half bad platform to land on early on in the grand scheme of things. I had no idea where it would take me over the years since. Anyway, enough about the past….
New to 3PAR
Still the focus of the majority of HP storage related action these days, they had a lot to talk about. All of this initial stuff isn’t there yet(up until the 7450 stuff below), just what they are planning for at some point in the future(no time frames on anything that I recall hearing).
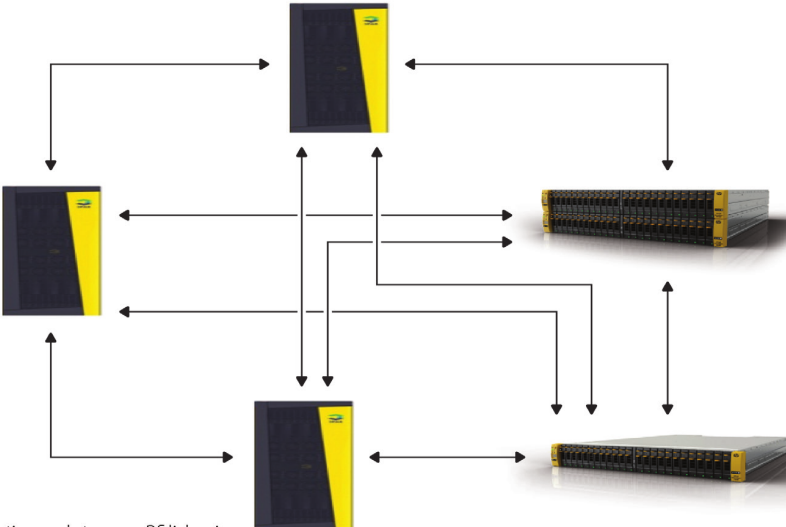
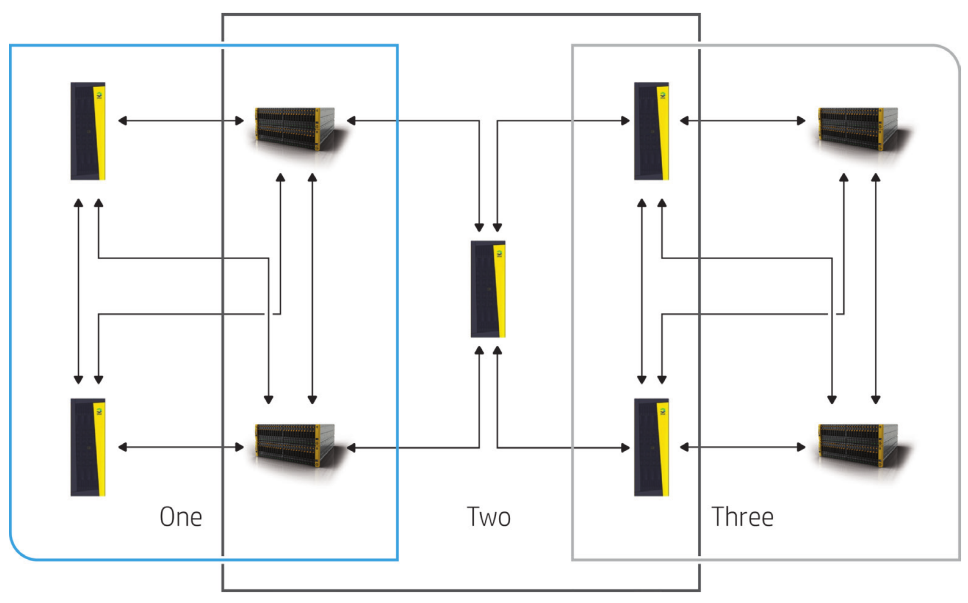
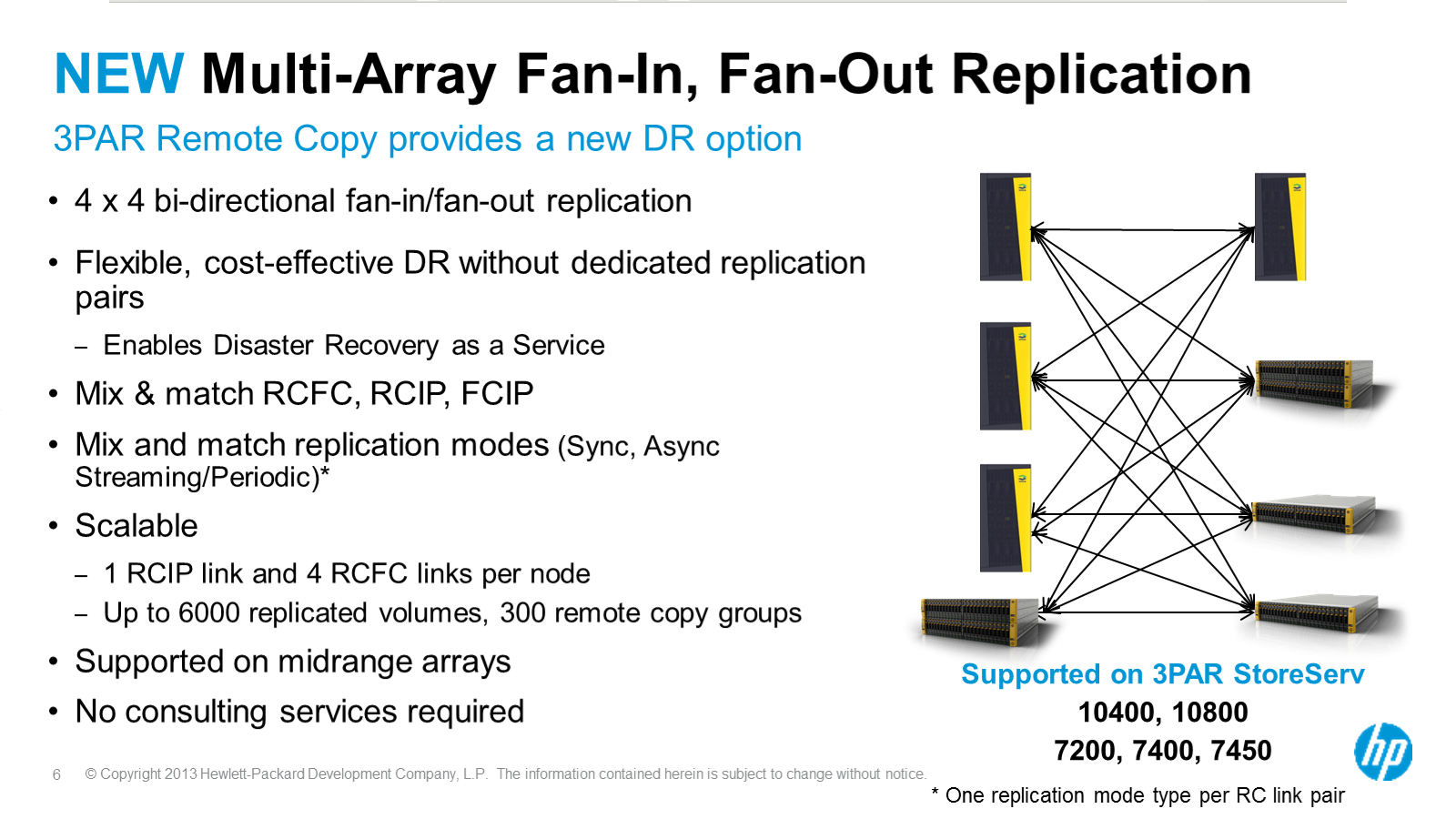
Asynchronous Streaming Replication
Just a passive mention of this on a slide, nothing in depth to report about, but I believe the basic concept is instead of having asynchronous replication running on snapshots that kick off every few minutes (perhaps every five minutes) the replication process would run much more frequently (but not synchronous still), perhaps as frequent as every 30 seconds or something.
I’ve never used 3PAR replication myself. Never needed array based replication really. I have built my systems in ways that don’t require array based replication. In part because I believe it makes life easier(I don’t build them specifically to avoid array replication it’s merely a side effect), and of course the license costs associated with 3PAR replication are not trivial in many circumstances(especially if your only needing to replicate a small percentage of the data on the system). The main place where I could see leveraging array based replication is if I was replicating a large number of files, doing this at the block layer is often times far more efficient(and much faster) than trying to determine changed bits from a file system perspective.
I wrote/built a distributed file transfer architecture/system for another company a few years ago that involved many off the shelf components(highly customized) that was responsible for replicating several TB of data a day between WAN sites, it was an interesting project and proved to be far more reliable and scalable than I could of hoped for initially.
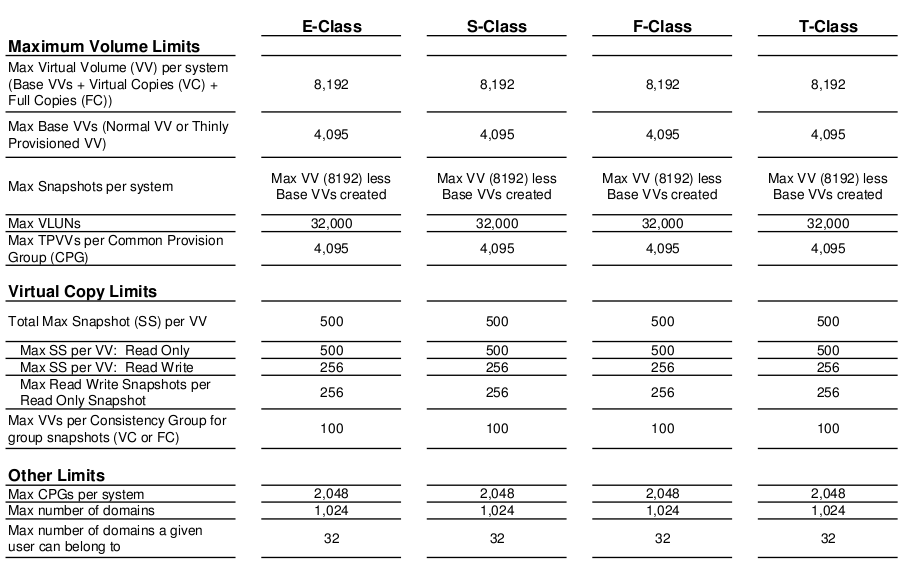
Increasing Maximum Limits
I think this is probably out of date, but it’s the most current info I could dig up on HP’s site. Though this dates back to 2010. These pending changes are all about massively increasing the various supported maximum limits of various things. They didn’t get into specifics. I think for most customers this won’t really matter since they don’t come close to the limits in any case(maybe someone from 3PAR will read this and send me more up to date info).
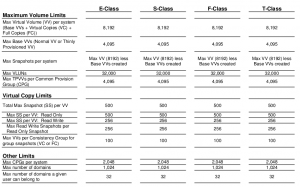
3PAR OS 2.3.1 supported limits(2010)
The PDF says updated May 2013, though the change log says last update is December. HP has put out a few revisions to the document(which is the Compatibility Matrix) which specifically address hardware/software compatibility, but the most recent Maximum Limits that I see are for what is now considered quite old – 2.3.1 release – this was before their migration to a 64-bit OS (3.1.1).
Compression / De-dupe
They didn’t talk about it, other than mention it on a slide, but this is the first time I’ve seen HP 3PAR publicly mention the terms. Specifically they mention in-line de-dupe for file and block, as well as compression support. Again, no details.
Personally I am far more interested in compression than I am de-dupe. De-dupe sounds great for very limited workloads like VDI(or backups, which StoreOnce has covered already). Compression sounds like a much more general benefit to improving utilization.
Myself I already get some level of “de duplication” by using snapshots. My main 3PAR array runs roughly 30 MySQL databases entirely from read-write snapshots, part of the reason for this is to reduce duplicate data, another part of the reason is to reduce the time it takes to produce that duplicate data for a database(fraction of a second as opposed to several hours to perform a full data copy).
File + Object services directly on 3PAR controllers
No details here other than just mentioning having native file/object services onto the existing block services. They did mention they believe this would fit well in the low end segment, they don’t believe it would work well at the high end since things can scale in different ways there. Obviously HP has file/object services in the IBRIX product (though HP did not get into specifics what technology would be used other than taking tech from several areas inside HP), and a 3PAR controller runs Linux after all, so it’s not too far fetched.
I recall several years ago back when Exanet went bust, I was trying to encourage 3PAR to buy their assets as I thought it would of been a good fit. Exanet folks mentioned to me that 3PAR engineering was very protective of their stuff and were very paranoid about running anything other than the core services on the controllers, it is sensitive real estate after all. With more recent changes such as supporting the ability to run their reporting software(System Reporter) directly on the controller nodes I’m not sure if this is something engineering volunteered to do themselves or not. Both approaches have their strengths and weaknesses obviously.
Where are 3PAR’s SPC-2 results?
This is a question I asked them (again). 3PAR has never published SPC-2 results. They love to tout their SPC-1, but SPC-2 is not there……. I got a positive answer though: Stay tuned. So I have to assume something is coming.. at some point. They aren’t outright disregarding the validity of the test.
In the past 3PAR systems have been somewhat bandwidth constrained due to their use of PCI-X. Though the latest generation of stuff (7xxx/10xxx) all leverage PCIe.
The 7450 tops out at 5.2 Gigabytes/second of throughput, a number which they say takes into account overhead of a distributed volume system (it otherwise might be advertised as 6.4 GB/sec as a 2-node system does 3.2GB/sec). Given they admit the overhead to a distributed system now, I wonder how, or if, that throws off their previous throughput metrics of their past arrays.
I have a slide here from a few years ago that shows a 8-controller T800 supporting up to 6.4GB/sec of throughput, and a T400 having 3.2GB/sec (both of these systems were released in Q3 of 2008). Obviously the newer 10400 and 10800 go higher(don’t recall off the top of my head how much higher).
This compares to published SPC-2 numbers from IBM XIV at more than 7GB/sec, as well as HP P9500/HDS VSP at just over 13GB/sec.
3PAR 7450
Announced more than a month ago now, the 7450 is of course the purpose built flash platform which is, at the moment all SSD.
Can it run with spinning rust?
One of the questions I had, was I noticed that the 7450 is currently only available in a SSD-only configuration. No spinning rust is supported. I asked why this was and the answer was pretty much what I expected. Basically they were getting a lot of flak for not having something that was purpose built. So at least in the short term, the decision not to support spinning rust is purely a marketing one. The hardware and software is the same(other than being more beefy in CPU & RAM) than the other 3PAR platforms. The software is identical as well. They just didn’t want to give people more excuses to label the 3PAR architecture as something that wasn’t fully flash ready.
It is unfortunate that the market has compelled HP to do this, as other workloads would still stand to gain a lot especially with the doubling up of data cache on the platform.
Still CPU constrained
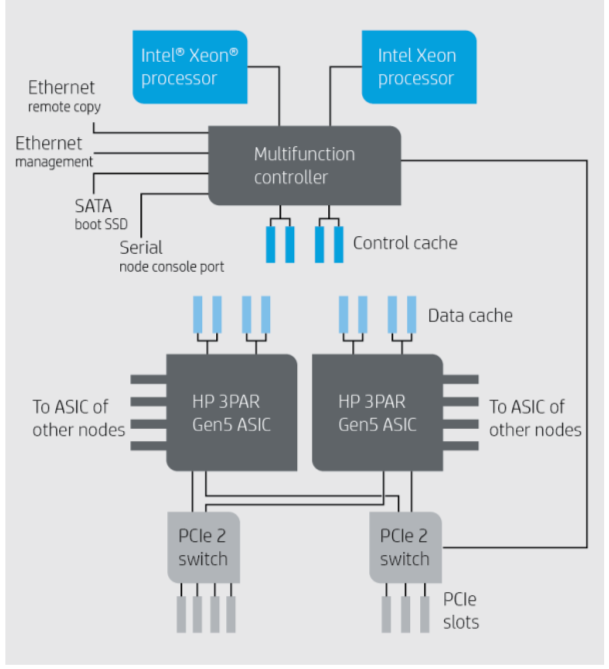
One of the questions asked by someone was about whether or not the ASIC is the bottleneck in the 7450 I/O results. The answer was a resounding NO – the CPU is still the bottleneck even at max throughput. So I followed up with why did HP choose to go with 8 core CPUs instead of 10-core which Intel of course has had for some time. You know how I like more cores! The answer was two fold to this. The primary reason was cooling(the enclosure as is has two sockets, two ASICs, two PCIe slots, 24 SSDs, 64GB of cache and a pair of PSUs in 2U). The second answer was the system is technically Ivy-bridge capable but they didn’t want to wait around for those chips to launch before releasing the system.
They covered a bit about the competition being CPU limited as well especially with data services, and the amount of I/O per CPU cycle is much lower on competing systems vs 3PAR and the ASIC. The argument is an interesting one though at the end of the day the easy way to address that problem is throw more CPUs at it, they are fairly cheap after all. The 7000-series is really dense so I can understand the lack of ability to support a pair of dual socket systems within a 2U enclosure along with everything else. The 10400/10800 are dual socket(though older generation of processors).
TANGENT TIME
I really have not much cared for Intel’s code names for their recent generation of chips. I don’t follow CPU stuff all that closely these days(haven’t for a while), but I have to say it’s mighty easy to confuse code name A from B, which is newer? I have to look it up. every. single. time.
I believe in the AMD world (AMD seems to have given up on the high end, sadly), while they have code names, they have numbers as well. I know 6200 is newer than 6100 ..6300 is newer than 6200..it’s pretty clear and obvious. I believe this goes back to Intel and them not being able to trademark the 486.
On the same note, I hate Intel continuing to re-use the code word i7 in laptops. I have an Core i7 laptop from 3 years ago, and guess what the top end today still seems to be? I think it’s i7 still. Confusing. again.
</ END TANGENT >
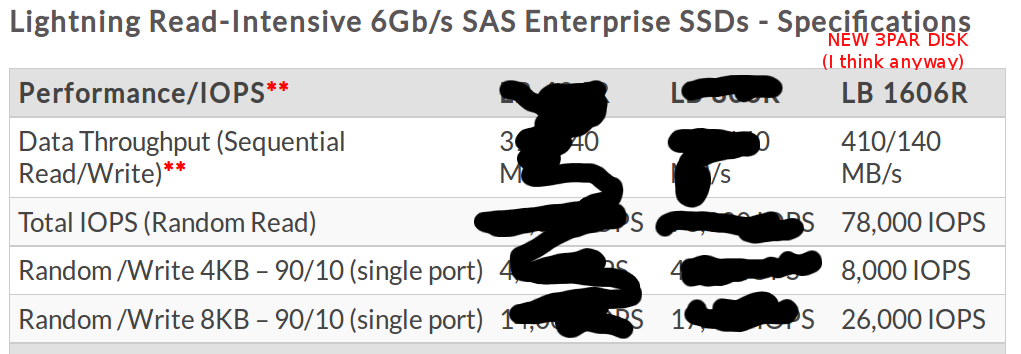
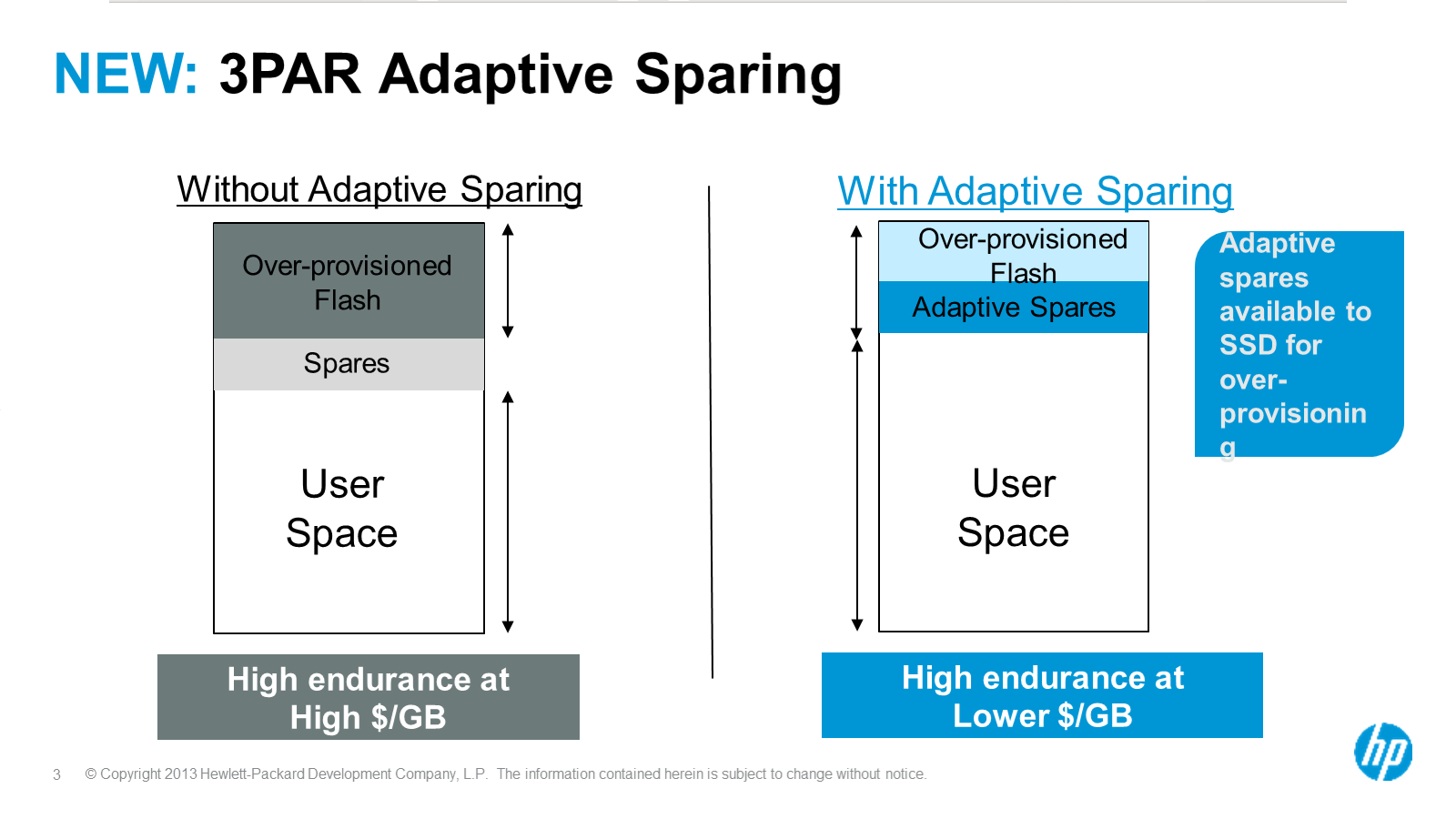
Effortless SSD management of each SSD with proactive alerts
I wanted to get this in before going deeper into the cache optimizations since that is a huge topic. But the basic gist of this is they have good monitoring of the wear of the SSDs in the platform(something I think that was available on Lefthand a year or two ago), in addition to that the service processor (dedicated on site appliance that monitors the array) will alert the customer when the SSD is 90% worn out. When the SSD gets to 95% then the system pro-actively fails the drive and migrates data off of it(I believe). They raised a statistic that was brought up at Discover that something along the lines of 95% of all deployed SSDs in 3PAR were still in the field – very few have worn out. I don’t recall anyone mentioning the # of SSDs that have been deployed on 3PAR but it’s not an insignificant number.
SSD Caching Improvements in 3PAR OS 3.1.2
There have been a number of non trivial caching optimizations in the 3PAR OS to maximize performance as well as life span of SSDs. Some of these optimizations also benefit spinning rust configurations as well – I have personally seen a noticeable drop in latency in back end disk response time since I upgraded to 3.1.2 back in May(it was originally released in December), along with I believe better response times under heavy load on the front end.
Bad version numbers
I really dislike 3PAR’s version numbering, they have their reasons for doing what they do, but I still think it is a really bad customer experience. For example going from 2.2.4 to 2.3.1 back in what was it 2009 or 2010. The version number implies minor update, but this was a MASSIVE upgrade. Going from 2.3.x to 3.1.1 was a pretty major upgrade too (as the version implied). 3.1.1 to 3.1.2 was also a pretty major upgrade. On the same note the 3.1.2 MU2 (patch level!) upgrade that was released last month was also a major upgrade.
I’m hoping they can fix this in the future, I don’t think enough effort is made to communicate major vs minor releases. The version numbers too often imply minor upgrades when in fact they are major releases. For something as critical as a storage system I think this point is really important.
Adaptive Read Caching
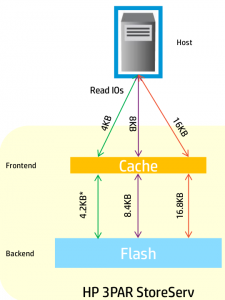
3PAR Adaptive Read Caching for SSD (the extra bits being read there from the back end are to support the T10 Data Integrity Feature- available standard on all Gen4 ASIC 3PAR systems, and a capability 3PAR believes is unique in the all flash space for them)
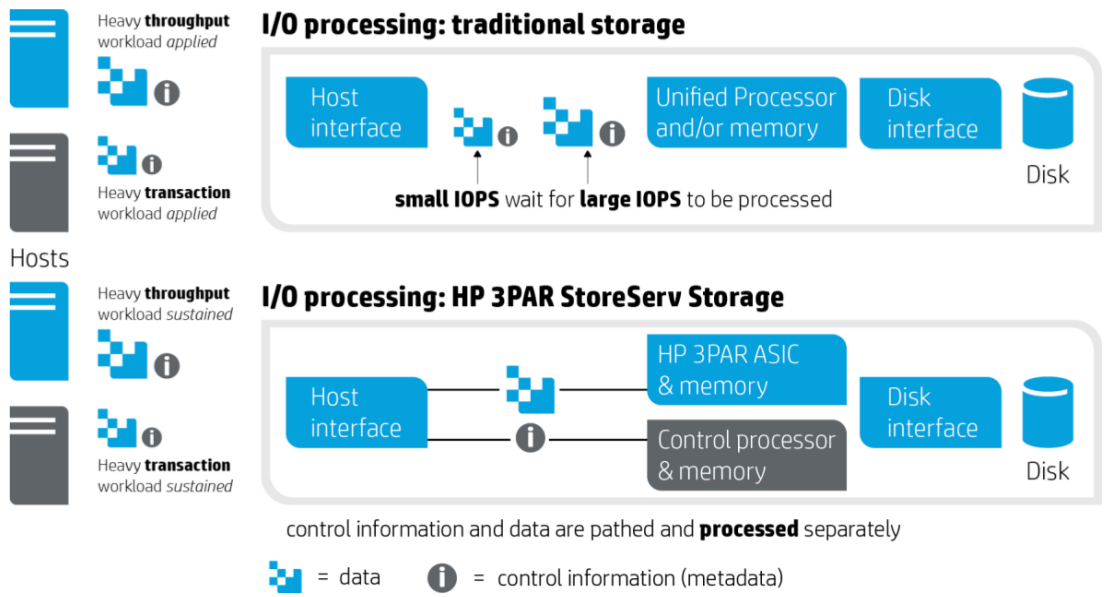
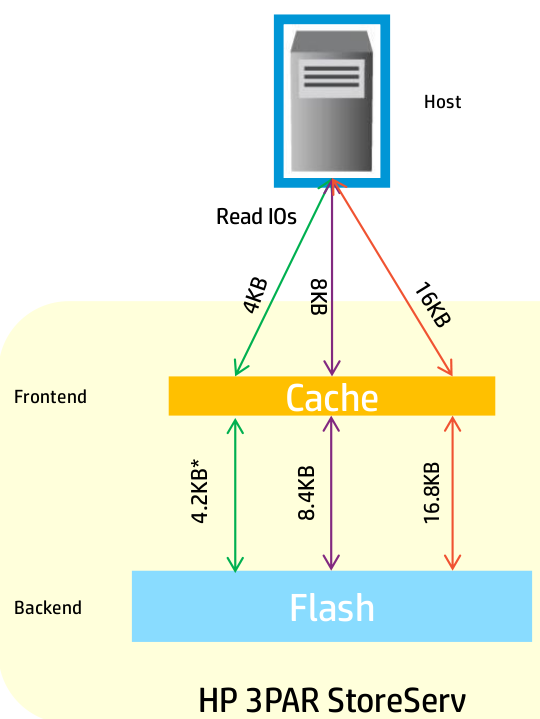
One of the things they covered with regards to caching with SSD is the read cache is really not as effective(vs with spinning rust), because the back end media is so fast, there is significantly less need for caching reads. So in general, significantly more cache is used with writes.
For spinning rust 3PAR reads a full 16kB of data from the back end disk regardless of the size of the read on the front end (e.g. 4kB). This is because the operation to go to disk is so expensive already and there is no added penalty to grab the other 12kB while your grabbing the 4kB you need. The next I/O request might request part of that 12kB and you can save yourself a second trip to the disk when doing this.
With flash things are different. Because the media is so fast, you are much more likely to become bandwidth constrained rather than IOPS constrained. So if for example you have that 500,000 4k read IOPS on the front end, and your performing those same 16kB read IOPS on the back end, that is, well 4x more bandwidth that is required to perform those operations. Again because the flash is so fast, there is significantly less penalty to go back to SSD again and again to retrieve those smaller blocks. It also improves latency of the system.
So in short, read more from disks because you can and there is no penalty, read only what you need from SSDs because you should and there is (almost) no penalty.
Adaptive Write Caching
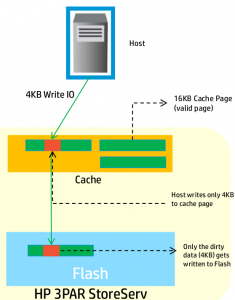
Adaptive Write Caching
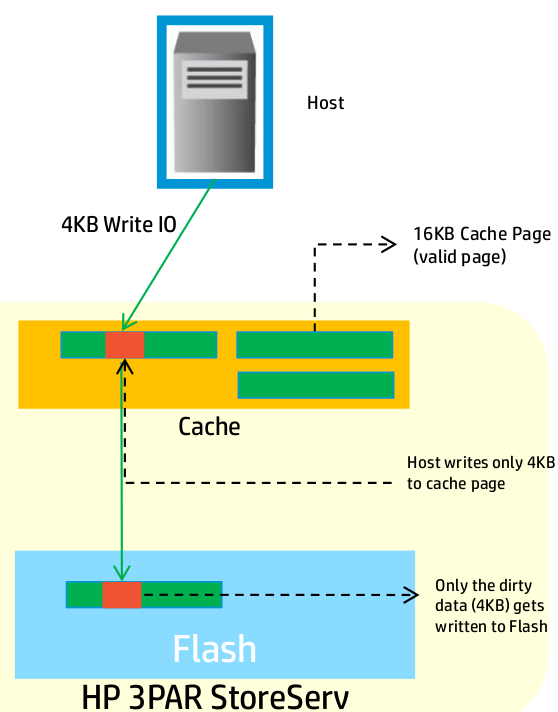
With writes the situation is similar to reads, to maximize SSD life span, and minimize latency you want to minimize the number of write operations to the SSD whenever possible.
With spinning rust again 3PAR works with 16kB pages, if a 4kB write comes in then the full 16kB is written to disk, again because there is no additional penalty for writing the 16kB vs writing 4kB. Unlike SSDs your not likely bandwidth constrained when it comes to disks.
With SSDs, the optimizations they perform, again to maximize performance and reduce wear, is if a 4kB write comes in, a 16kB write occurs to the cache, but only the 4kB of changed data is committed to the back end.
If I recall right they mentioned this operation benefits RAID 1 (anything RAID 1 in 3PAR is RAID 10, same for RAID 5 – it’s RAID 50) significantly more than it benefits RAID 5/6, but it still benefits RAID 5/6.
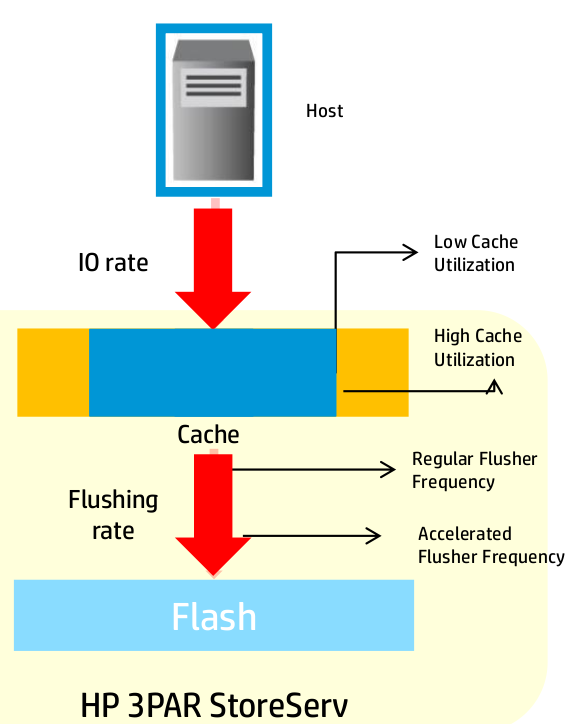
Autonomic Cache offload
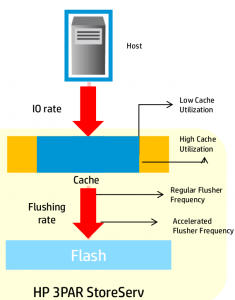
Autonomic Cache Offload
Here the system changes the frequency at which it flushes cache to back end media based on utilization. I think this plays a lot into the next optimization.
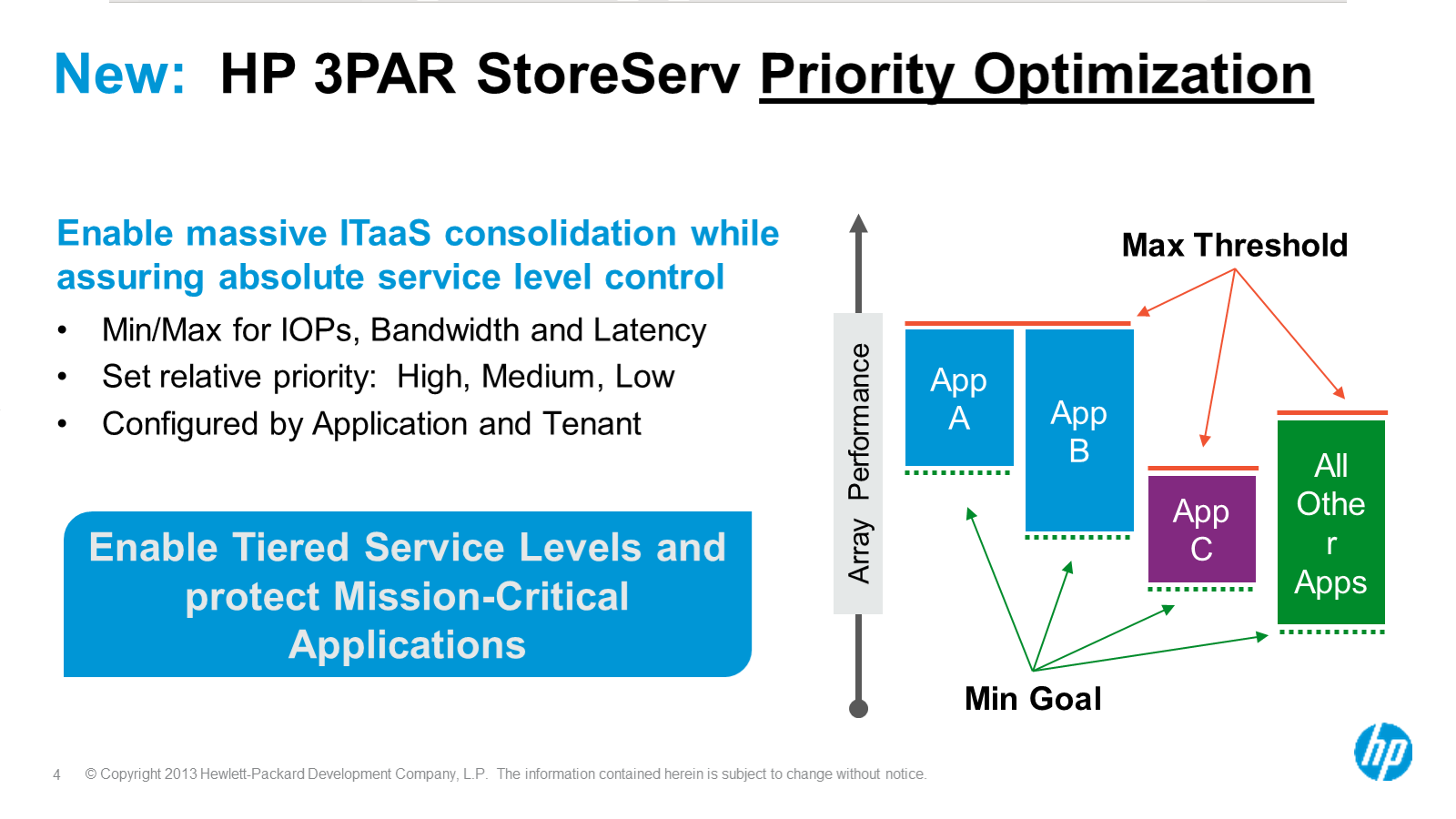
Multi Tenant I/O Processing
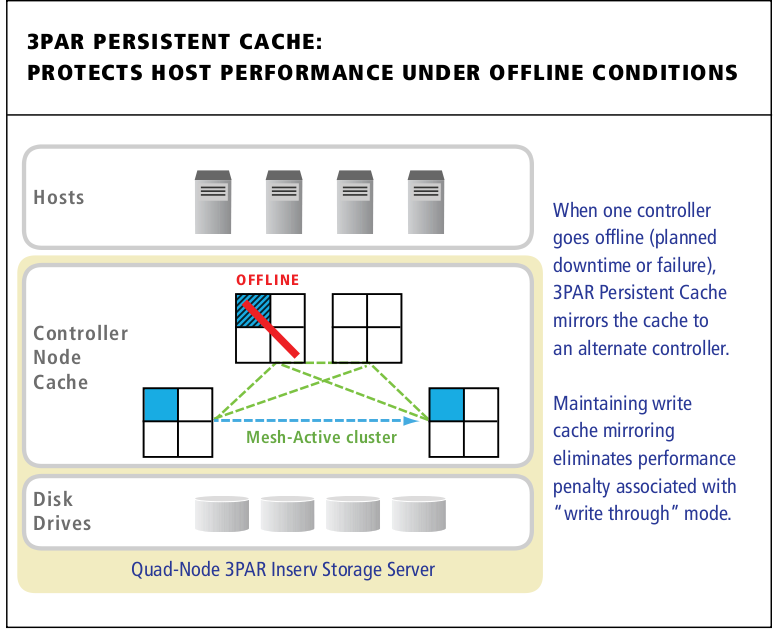
3PAR has long been about multi tenancy of their systems. The architecture lends itself well to running in this mode though it wasn’t perfect, I believe for the most part the addition of Priority Optimization that was announced late last year and finally released last month fills the majority of the remainder of that hole. I have run “multi tenant” 3PAR systems since the beginning. Now to be totally honest the tenants were all me, just different competing workloads, whether it is disparate production workloads or a mixture of production and non production(and yes in all cases they ran on the same spindles). It wasn’t nearly as unpredictable as say a service provider with many clients running totally different things, that would sort of scare me on any platform. But there was still many times where rogue things (especially horrible SQL queries) overran the system (especially write cache). 3PAR handles it as well, if not better than anyone else but every system has it’s limits.
Front end operations
The caching flushing process to back end media is now multi threaded. This benefits both SSD as well as existing spinning rust configurations. Significantly less(no?) locking involved when flushing cache to disk.
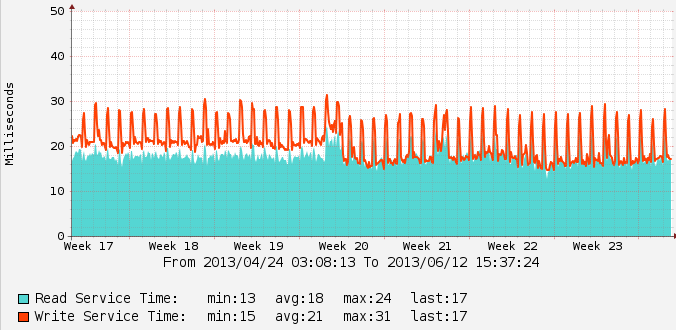
Here is a graph from my main 3PAR array, you can see the obvious latency drop from the back end spindles once 3.1.2 was installed back in May (again the point of this change was not to impact back end disk latency as much as it was to improve front end latency, but there is a significant positive behavior change post upgrade):
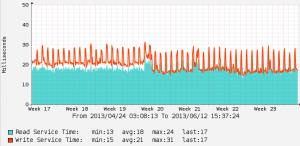
- Latency Change on back end spinning rust with 3.1.2
There was a brief time when latency actually went UP on the back end disks. I was concerned at first but later determined this was the disk defragmentation processes running(again with improved algorithms), before the upgrade they took FAR too long, post upgrade they completed a big backlog in a few days and latency returned to low levels.
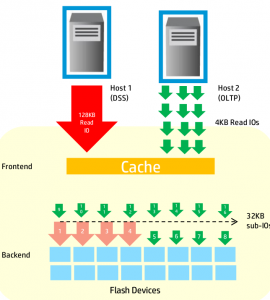
Multi Tenant Caching
Back end operations
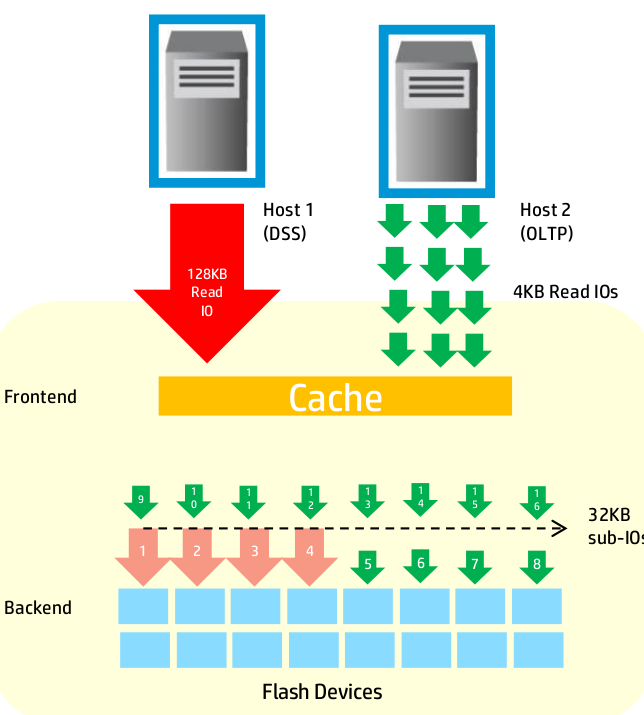
On the topic of multi tenant with SSDs an interesting point was raised which I had never heard of before. They even called it out as being a problem specific to SSDs, and does not exist with spinning rust. Basically the issue is if you have two workloads going to the same set of SSDs, one of them issuing large I/O requests(e.g. sequential workload), and the other issuing small I/O requests(e.g. 4kB random read), the smaller I/O requests will often get stuck behind the larger ones causing increases in latency to the app using smaller I/O requests.
To address this, the 128kB I/Os are divided up into four 32kB I/O requests and sent in parallel to the other workload. I suppose I can get clarification but I assume for a sequential read operation with 128kB I/O request there must not be any additional penalty for grabbing the 32kB, vs splitting it up even further into even more smaller I/Os.
Maintaining performance during media failures
3PAR has always done wide striping, and sub disk distributed RAID so the rebuild times are faster, the latency is lower and all around things run better(no idle hot spares) that way vs the legacy designs of the competition. The system again takes additional steps now to maximize SSD life span by optimizing the data reads and writes under a failure condition.
HP points out that SSDs are poor at large sequential writes, so as mentioned above they divide the 128kB writes that would be issued during a rebuild operation (since that is largely a sequential operation) into 32kB I/Os again to protect those smaller I/Os from getting stuck behind big I/Os.
They also mentioned that during one of the SPC-1 tests (not sure if it was 7400 or 7450) one of the SSDs failed and the system rebuilt itself. They said there was no significant performance hit(as one might expect given experience with the system) as the test ran. I’m sure there was SOME kind of hit especially if you drive the system to 100% of capacity and suffer a failure. But they were pleased with the results regardless. The competition would be lucky to have something similar.
What 3PAR is not doing
When it comes to SSDs and caching something 3PAR is not doing, is leveraging SSDs to optimize back end I/Os to other media as sequential operations. Some storage startups are doing this to gain further performance out of spinning rust while retaining high random performance using SSD. 3PAR doesn’t do this and I haven’t heard of any plans to go this route.
Conclusion
I continue to be quite excited about the future of 3PAR, even more so pre acquisition. HP has been able to execute wonderfully on the technology side of things. Sales from all accounts at least on the 7000 series are still quite brisk. Time will tell if things hold up after EVA is completely off the map, but I think they are doing many of the right things. I know even more of course but can’t talk about it here(yet)!!!
That’s it for tonight, at ~4,000 (that number keeps going up, I should goto bed) words this took three hours or more to write+proof read, it’s also past 2AM. There is more to cover, the 3PAR stuff was obviously what I was most interested in. I have a few notes from the other sessions but they will pale in comparison to this.
Today I had a pretty good idea on how HP could improve it’s messaging around whether to choose 3PAR or StoreVirtual for a particular workload. The messaging to-date to me has been very confusing and conflicting (HP tried to drive home a point about single platforms and reducing complexity, something this dual message seems to conflict with). I have been communicating with HP off and on for the past few months, and today out of the blue I came up with this idea which I think will help clear the air. I’ll touch on this soon when I cover the other areas that were talked about today.
Tomorrow seems to be a busy day, apparently we have front row seats, and the only folks with power feeds. I won’t be “live blogging”(as some folks tend to love to do), I’ll leave that to others. I work better at spending some time to gather thoughts and writing something significantly longer.
If you are new to this site you may want to check out a couple of these other articles I have written about 3PAR(among the dozens…)
Thanks for reading!