NetApp came out with their latest generation of storage systems recently and they were good citizens and promptly published SPC-1 results for them.
When is clustering, clustering?
NetApp is running the latest Ontap 8.2 in cluster mode I suppose, though there is only a single pair of nodes in the tested cluster. I’ve never really considered this a real cluster, it’s more of a workgroup of systems. Volumes live on a controller (pair) and can be moved around if needed, they probably have some fancy global management thing for the “cluster” but it’s just a collection of storage systems that are only loosely integrated with each other. I like to compare the NetApp style of clustering to a cluster of VMware hosts (where the VMs would be the storage volumes).
This strategy has it’s benefits as well, the main one being less likelihood that the entire cluster could be taken down by a failure(normally I’d consider this failure to be triggered by a software fault). This is the same reason why 3PAR has elected to-date to not go beyond 8-nodes in their cluster, the risk/return is not worth it in their mind. In their latest generation of high end boxes 3PAR decided to double up the ASICs to give them more performance/capacity rather than add more controllers, though technically there is nothing stopping them from extending the cluster further(to my knowledge).
The downside to workgroup style clustering is that optimal performance is significantly harder to obtain.
3PAR clustering is vastly more sophisticated and integrated by comparison. To steal a quote from their architecture document –
The HP 3PAR Architecture was designed to provide cost-effective, single-system scalability through a cache-coherent, multi-node, clustered implementation. This architecture begins with a multi-function node design and, like a modular array, requires just two initial Controller Nodes for redundancy. However, unlike traditional modular arrays, an optimized interconnect is provided between the Controller Nodes to facilitate Mesh-Active processing. With Mesh-Active controllers, volumes are not only active on all controllers, but they are autonomically provisioned and seamlessly load-balanced across all systems resources to deliver high and predictable levels of performance. The interconnect is optimized to deliver low latency, high-bandwidth communication and data movement between Controller Nodes through dedicated, point-to-point links and a low overhead protocol which features rapid inter-node messaging and acknowledgement.
Sounds pretty fancy right? It’s not something that is for high end only. They have extended the same architecture down as low as a $25,000 entry level price point on the 3PAR 7200 (that price may be out of date, it’s from an old slide).
I had the opportunity to ask what seemed to be a NetApp expert on some of the finer details of clustering in Ontap 8.1 (latest version is 8.2) a couple of years ago and he provided some very informative responses.
Anyway on to the results, after reading up on them it was hard for me not to compare them with the now five year old 3PAR F400 results.
Also I want to point out that the 3PAR F400 is End of Life, and is no longer available to purchase as new as of November 2013 (support on existing systems continues for another couple of years).
| Metric | NetApp FAS8040 | 3PAR F400 |
|---|---|---|
| Date tested | 2/19/2014 | 4/27/2009 |
| Controller Count | 2 | 4 (hey, it's an actual cluster) |
| SPC-1 IOPS | 86,072 | 93,050 |
| SPC-1 Usable Capacity | 32,219 GB (RAID 6) | 27,046 GB (RAID 1) |
| Raw Capacity | 86,830 GB | 56,377 GB |
| SPC-1 Unused Storage Ratio (may not exceed 45%) | 41.79% | 0.03% |
| Tested storage configuration pricing | $495,652 | $548,432 |
| SPC-1 Cost per IOP | $5.76 | $5.89 |
| Disk size and number | 192 x 450GB 10k RPM | 384 x 146GB 15k RPM |
| Data Cache | 64GB data cache 1,024GB Flash cache | 24GB data cache |
I find the comparison fascinating myself at least. It is certainly hard to compare the pricing, given the 3PAR results are five years old, the 3PAR mid range pricing model has changed significantly with the introduction of the 7000 series in late 2012. I believe the pricing 3PAR provided SPC-1 was discounted(I can’t find indication either way, I just believe that based on my own 3PAR pricing I got back then) vs NetApp is list(says so in the document). But again, hard to compare pricing given the massive difference in elapsed time between tests.
Unused storage ratio
What is this number and why is there such a big difference? Well this is a SPC-1 metric and they say in the case of NetApp:
Total Unused Capacity (36,288.553 GB) divided by Physical Storage Capacity (86.830.090 GB) and may not exceed 45%.
A unused storage ratio of 42% is fairly typical for NetApp results.
In the case of 3PAR, you have to go to the bigger full disclosure document(72 pages), as the executive summary has evolved more over time and that specific quote is not in the 3PAR side of things.
So for 3PAR F400 SPC says:
The Physical Storage Capacity consisted of 56,377.243 GB distributed over 384 disk drives each with a formatted capacity of 146.816 GB. There was 0.00 GB (0.00%) of Unused Storage within the Physical Storage Capacity. Global Storage Overhead consisted of 199.071 GB (0.35%) of Physical Storage Capacity. There was 61.203 GB (0.11%) of Unused Storage within the Configured Storage Capacity. The Total ASU Capacity utilized 99.97% of the Addressable Storage Capacity resulting in 6.43 GB (0.03%) of Unused Storage within the Addressable Storage Capacity.
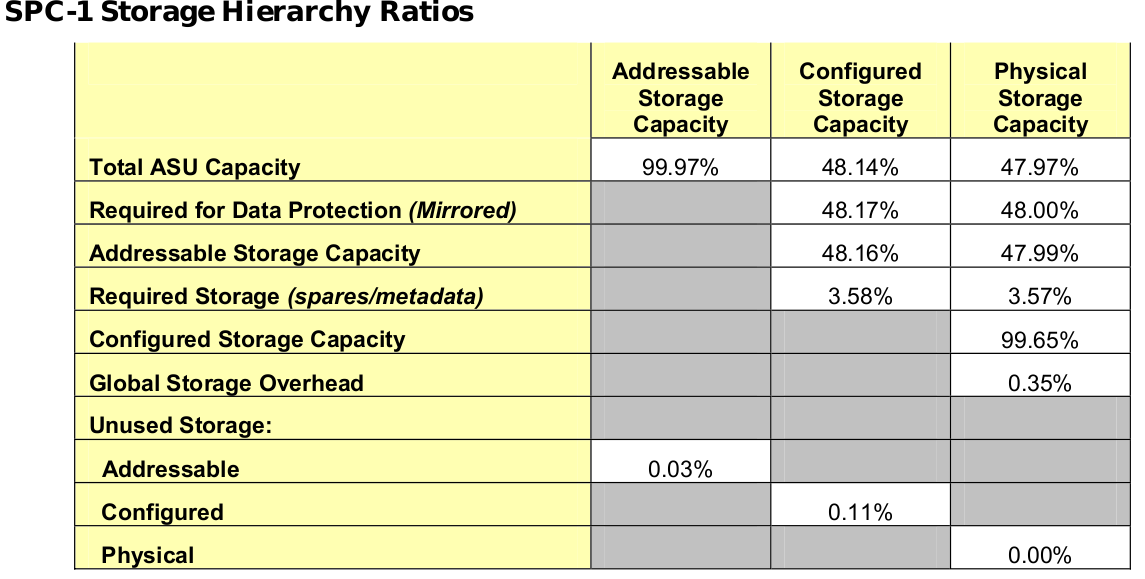
3PAR F400 Storage Hierarchy Ratios
The full disclosure document is not (yet) available for NetApp as of 2/21/2014. It most certainly will become available at some point.
The metrics above and beyond the headline numbers is one of the main reasons I like SPC-1.
With so much wasted space on the NetApp side it is confusing to me why they don’t just use RAID 1 (I think the answer is they don’t support it).
Benefits from cache
The NetApp system is able to leverage it’s terabyte of flash cache to accelerate what is otherwise a slower set of 10k RPM disks, which is nice for them.
They also certainly have much faster CPUs, and more than double the data cache (3PAR’s architecture isolates data cache from the operating system, so I am not sure how much memory on the NetApp side is actually used for data cache vs operating system/meta data etc). 3PAR by contrast has their proprietary ASIC which is responsible for most of the magic when it comes to data processing on their systems.
3PAR does not have any flash cache capabilities so they do require (in this comparison) double the spindle count to achieve the same performance results. Obviously in a newer system configuration 3PAR would likely configure a system with SSDs and sub LUN auto tiering to compensate for the lack of a flash based cache. This does not completely completely compensate however, and of course I have been hounding 3PAR and HP for at least four years now to develop some sort of cache technology that leverages flash. They announced SmartCache in December 2012 (host-based SSD caching for Gen8 servers) however 3PAR integration has yet to materialize.
However keep in mind the NetApp flash cache only accelerates reads. If you have a workload like mine which is 90%+ write the flash cache doesn’t help.
Conclusion
NetApp certainly makes good systems, they offer a lot of features, and have respectable performance. The systems are very very flexible and they have a very unified product line up (same software runs across the board).
For me personally after seeing results like this I feel continually reassured that the 3PAR architecture was the right choice for my systems vs NetApp (or other 3 letter storage companies). But not everyone’s priorities are the same. I give NetApp props for continuing to support SPC-1 and being public with their numbers. Maybe some day these flashy storage startups will submit SPC-1 results…….not holding my breath though.
Great observations Nate.
The F400 result from 2009 has an Unused Storage Ratio of 0.14% for the record.
The curiosity in me just cannot get beyond trying to understand why the NetApp cluster mode SPC-1 results have such poor capacity utilisation – the FAS6240 @ 44% and this FAS8040 @ 45%. This is in stark contrast to an older FAS3270A and FAS3170 results (non cluster mode Ontap) @ 70% which is quite respectable.
Don’t know whats going on in the cluster mode file system – but there is some attribute there preventing peak performance at anything above approx. 45% capacity utilisation – which means there is a terrible lot of spinning empty white space in that cluster.
Paul Haverfield [HP Storage]
Comment by Paul Haverfield [HP Storage] — February 21, 2014 @ 6:58 pm
Interesting observations.
Here is another: who is blowing 3PAR out of the water with market share?
Comment by Mike — February 22, 2014 @ 9:09 am
Mike, good point,
The best data to track this is IDC’s Worldwide Quarterly Disk Storage Systems tracker. The latest data from calender quarter 3 – 2013 ending Sep for the Mid Range FC SAN market shows HP gaining share – and moving into #2 position; NetApp moving into #4 position behind IBM at #3, and EMC in #1 position with decreasing share.
Paul.
Comment by Paul Haverfield [HP Storage] — February 22, 2014 @ 10:17 am
Hey Mike!
Thanks for the comment (and thanks to Paul too).
NetApp has long played what I consider to be dirty sales tactics to win deals. Other bigger companies do the same(HP may be doing it now too with 3PAR I am not sure). Cisco does it for sure etc etc..
3PAR did not, they would(and did) walk away from many deals while they were stand alone, to not take losses.
So I share with you my first experience with NetApp and 3PAR back in 2006. I had not heard of 3PAR before, I did not have much storage experience at the time and was in the market for a small mid range storage box. A former rep from EMC that went to 3PAR cold called me one day and we started talking. My previous employer’s staff was all raging over NetApp they loved it (at least initially – they were the largest customer of NetApp gear in the northwest). Anyway so hearing good things from them I asked NetApp to come in and show their stuff too. We were a small company.
Both solutions at the time seemed fine, I think both would of done their job. I still have the quotes and looking at the NetApp side of things the model we quoted was a 3020 HA.
The time came to take things to the next step, I needed to demonstrate to my management that we needed this stuff, they were not very experienced and didn’t understand the need for a centralized storage array. So I went to 3PAR and I went to NetApp and said gimme an eval/demo unit so I can show my company what you can do.
3PAR was falling over themselves to give us an eval. They footed all the costs, set it up, configured, trained us everything.
NetApp said no. We don’t do evals, I can probably dig that email up too. The VAR we were dealing with said they had not done a NetApp eval in years.
I asked again and again they said No we won’t.
So we started playing with the 3PAR(and after having talked with 3PAR about how customers had put their demo arrays in production to assist things and ended up buying them as a result I made sure to NOT install the 3PAR in a location that would make that possible) for literally a couple of days a critical situation in production came up that we were able to leverage the 3PAR for (even though it was not at the same physical location as our data center). Basically we needed to make a table change to one of our production mysql servers(not a transactional server it was more of a backing store for a search engine at the time). The problem was our DAS system was full enough that we could not do that, MySQL is terrible about space management and it meant re-writing another several hundred gigs(forgot how much exactly) of so of data out to disk to make this change. Not enough space in production to do it. So what did we do? This is pretty crazy I know but it’s a fun story to tell. We put the MySQL server in read-only mode. We copied the data to a USB drive, brought the USB drive back to the office, copied the data onto the 3PAR, made the change. Copied the data back to the USB drive, took it back to the data center and copied it to the server.
That was purely coincidence, but it showed my management at the time the benefits of having a larger “pool” of storage, and some of the problems associated with “islands” of DAS.
So we decided to go with 3PAR.
But wait, where is the dirty sales tactics?
After I informed the NetApp team of our decision to buy 3PAR they came back with — you guessed it a last minute discount to try to win the deal. This really pissed me off. You haven’t won on the merits of your technology or your support so you cut the price to make it look good.
The quote I am reading here from 2/26/2007 has a list price of $177,051.43 and has a discount applied to it of $118,820.94 for a customer price of only $58,230.49. Digging up the 3PAR quote our pricing was $84,535, so NetApp was a full 32% less expensive vs 3PAR. I know a lot of management out there will stop right there and just sign it, and say screw the startup we got this good price from a big reputable company. Not taking into account anything other than purchase price.
Not being a NetApp expert myself I can only give you this quote from the VAR
Certainly percentage wise it was not a trivial discount given the size of the overall deal.
I handed that to my boss and said I don’t think we should buy this. He had the same mindset as me. NetApp screwed us on the eval they aren’t going to buy themselves into this deal. Basically it could of been $10 and my boss wouldn’t of taken it(over 3PAR).
Here is another interesting story again same northwest NetApp sales team (which I think may be now mostly fired/replaced at this point). The next company I went to we bought a 3PAR T400 along with an Exanet cluster to serve NFS traffic. Exanet obviously went out of business and so I looked at alternatives to Exanet. I settled on a NetApp V3000-series (I forgot which specifically). In part because it had *double* the SPECsfs scores vs Exanet at the time so I figured hey it will probably work fine. I left the company before they really put the NetApp into production.
The NetApp failed horribly, not as in downtime but as in performance was just terrible for their workload. So what is the dirty sales tactics again? I heard this through a 3rd party as I was not there but I was quite astonished. The company went to Netapp and said “hey look, we’re having all these issues with your system do you have any suggestions?” The sales team came back and said “Oh hey, yeah…..ummm we think we may not be supporting 3PAR in the future so your better off just buying replacement NetApp storage systems and just move everything onto there”.
I didn’t know the management at my former company that was dealing with NetApp at the time, they replaced the management I had after I left there.
The company’s response was awesome though I give them props for this. They basically said “screw you NetApp your stuff is outta here”, and they bought a 4-node HP NAS cluster (HP basically came in and said “we’ll own the problem”) without even testing it(seemed kinda scary). I haven’t heard any updates since, for all I know the HP stuff failed too. But the point was the sales folks at NetApp were not people I liked to deal with. Dirty folks .. I’m sure it doesn’t apply across the board but I have seen similar things with the likes of EMC, Cisco etc.. I get the sense that HP doesn’t play that game (as much), as I have heard of them walking away from 3PAR deals when the margin got too low, and I do remember specifically HP saying on the PC front anyway they were not playing a pricing war with Dell (who was dropping their pants on prices 1-2 quarters ago for servers anyway).
I remember a deal that Cisco did with AT&T many years ago. They were going up against several other players for some key AT&T infrastructure upgrades. Cisco had lost on every point. AT&T was going to go with someone else(despite at least at the time AT&T proclaimed themselves as the world’s largest Cisco reseller – I did buy a bit of Cisco from them at the time and was a AT&T data center customer at the time). Cisco came back with — you guessed it — but probably didn’t guess the magnitude — a 98% off list price to seal the deal away from the competition.
So there’s my story…..now I have had some bad experiences with 3PAR sales folks after I moved to the bay area but there wasn’t any dirty handed stuff there. I see similar behavior across the board for all vendors and VARs in the bay area. There is just so much business to be had people don’t care as much about their customers because if you lose one there’s always another. That and they are too greedy to hire more sales staff to improve the customer experience. The caveat here is the sales staff is great up until you buy, then they sort of wander off onto other customers. That just really never happened to me in Seattle that I can recall.
The particular 3PAR sales rep has since left HP and joined another storage startup(obviously a lot of the good 3PAR sales reps have long since left HP – this particular rep did do tons of big deals, he was not an under performer by any stretch at least from a $$ standpoint). The 3PAR sales and support staff I had for several years in Seattle area were just amazing, and they even came through for me on critical things after I moved knowing they would not get any credit for it due to territory crap that HP has. Fortunately the back end 3PAR staff, engineering etc continues to be awesome and I appreciate the time I can spend with them.
I’ll end this by saying about two and a half years ago I met a NetApp system engineer or architect or something in the bay area while we were at my current company evaluating whether to go NetApp or 3PAR. That guy was AWESOME. So honest and knowledgeable. I drilled him for an hour on deep topics and he had all the answers, no marketing crap.
I am fully aware I am biased towards 3PAR I never dispute that. In this case I tried to stay away from the deal making and let my boss deal with them. It appeared at one point that NetApp had won the deal, I was ok with that, I thought the solution would of worked(though in hindsight we probably would of needed an immediate I/O capacity increase to handle the write load which we were not aware of at the time as we were moving out of a crappy public cloud provider), even though obviously I prefer 3PAR.
Though in the end my boss at the time decided on 3PAR even though it was a bit more in part because he knew what my background was on the platform (he also really liked the 3PAR availability things such as cage level availability, rapid rebuild etc). The VAR we were using had their VP of tech come in and basically pitch NetApp for a couple of hours. It was an interesting pitch but both my boss and I agreed what he was pitching was not reality for our company (fancy multi site global network of storage systems with consolidated de-duped backups etc). And at the end of the day – if we got that big and really wanted to leverage NetApp stuff we could just get some V-series. I don’t see that happening, but your already that big the extra cost is not much and you get the benefits of the great 3PAR back end architecture, and if you need it the great NetApp software stack at the same time.
Whew that ended up being longer than I thought 🙂
thanks for reading and appreciate the post!
Comment by Nate — February 22, 2014 @ 12:40 pm
Hello all, Dimitris from NetApp here (recoverymonkey.org). I have plenty of SPC-1 analyses on my site. I’ll post something soon on the new ones…
First, to respond to Paul… no, there’s nothing about Clustered ONTAP causing problems over 45% capacity utilization, though I’m sure you’d like for that to be true 🙂
The “Application Utilization” is the far more interesting metric. RAID10 systems will always have this under 50% since, by definition, RAID10 loses half the capacity.
The Application Utilization in the recent NetApp 8040 benchmark was 37.11%, similar and even better than many other systems (for example, the HDS VSP had an Application Utilization of 29.25%. The F400 result had a very good Application Utilization of 47.97%, the 3Par V800 was 40.22% and the 3Par 7400 had an Application Utilization of only 35.23% – does that mean 3Par has a problem over 35% utilization, Paul? Seems like the Application Utilization of the 3Par boxes goes DOWN with more recent submissions.)
Why we don’t do RAID10?
Why should we? 🙂
RAID-DP/RAID6 have mathematically WAY better protection than RAID10.
The fact that we can perform so fast on a benchmark that’s 60% writes, where every other vendor needs RAID10 to play, says something about NetApp technology.
Thx
D
Comment by Dimitris Krekoukias — February 22, 2014 @ 6:27 pm
Thanks for the comment! Yes the numbers are pretty good, despite other folks like 3PAR using RAID 10 that space is at least being used — and in the sophisticated enterprise systems RAID 10 has an edge over RAID 5 or 6 in not only writes but reads as well as both sides of the mirror can be used for reads. Given the very high utilization of a typical 3PAR system they can frequently get more performance/space out of a given set of resources on 10 than competing vendors can on RAID 5 or 6(one example I can think of is IBM Storewize which last I heard performed RAID 5 calculations in software resulting in very very poor performance). So utilization plays a pretty important role.
So if your not going to use a large portion of the storage with a “lower space overhead” system like RAID 6 (vs 10) it seems to make sense to might as well just go with 10 and get the extra performance benefits(likely higher utilization as well). For me I use RAID 50, the level I use is (number of shelves – 1), so in the case of 6 shelves for example use 5+1 for optimal data layout. Or with 8 shelves I’d use 3+1 (* 2 sets of shelves). Better performance, faster recovery times and with sub disk RAID no wasted spindles.
But I like to give the customer that choice, if they want to use 10, fine, or 5, or 6, whatever is best for their workload. More props if you give them the ability to change the settings on the fly without application disruption or buying additional resources (e.g. last time I spoke with HDS their RAID conversion required blank spindles to convert onto, no in place conversions). More props still if you can run multiple levels of RAID on the same spindles for different application requirements.
A few years ago I wrote a post to help people think about the need of RAID 6 especially on a 3PAR system:
http://www.techopsguys.com/2010/08/13/do-you-really-need-raid-6/
Comment by Nate — February 22, 2014 @ 6:55 pm
Nate,
ONTAP doesn’t write like normal RAID 6. Therefore your arguments, while correct in general, don’t apply in this case.
Read:
https://communities.netapp.com/community/netapp-blogs/efficiency/blog/2011/02/08/flash-cache-doesnt-cache-writes–why
And BTW we CAN use more space.
Read this one on an older submission:
http://recoverymonkey.org/2010/11/09/176/
Older, slower system, older ONTAP, etc.
So – to re-iterate: no point using single parity RAID or RAID 10 on an ONTAP system.
And, mathematically, RAID 50 is kinda risky, JFYI.
Yes, chunklets make it quicker to recover, but the loss of the wrong two drives could still be an issue, or do I have this wrong?
Thx
D
Comment by Dimitris Krekoukias — February 22, 2014 @ 10:32 pm
thanks! yes I know about WAFL I have spoken to Netapp on it in depth on more than one occasion.
Losing the “wrong two” drives in RAID 5/50 is just as bad as losing the “wrong three drives” in
RAID 6/60.
All comes down to the math – how fast does the system recover from the fault, and when does the next read error/drive failure occur.
The post above notes evidence from a ZFS user who suffered triple disk failure in part because their system took a week or more to (try) to rebuild. To add insult to injury the vendor(Sun/Oracle) could find no fault with the hardware.
ZFS introduced triple parity raid several years ago to try to address that, it’s just a race, relying on ever increasing numbers of redundant parity disks is not a good solution to the problem at hand. Large object stores have for the most part done away with RAID altogether and take a similar approach to 3PAR’s chunklets – replicate the objects, not the disks.
https://blogs.oracle.com/ahl/entry/triple_parity_raid_z
I mention that because I’m not aware myself of any other systems that support triple parity raid (though I haven’t looked too hard either).
thanks for the links!
Comment by Nate — February 22, 2014 @ 11:09 pm
Well – statistically, the probability of losing a single drive and, while rebuilding that drive from parity, encountering a URE (Unrecoverable Read Error) is far higher than the probability of losing two drives in rapid succession; or three.
This is the reason we went with dual parity on all pooled systems before any other vendor. We sell systems to ExaByte-class customers. It’s very interesting, the kind of data one collects at such scale.
It’s not just how long it takes to rebuild the drive. Though it helps to have less exposure.
Then there’s stuff like comprehensive lost write protection (which previous few systems offer); plus drive prefailing and other mechanisms.
It takes a lot more than RAID to protect data.
The problem is most people are unaware, and we at NetApp have been doing these things for so long we take them for granted and forget to educate.
Overall, our systems offer a great balance of price, reliability, features and performance.
Are there faster systems? Some. More reliable? Maybe for edge cases. More feature-rich? Probably none. But this balance we offer, I haven’t seen any other vendor come close to.
It’s about solving business problems. The tech is an enabler but it is important to not become slave to the tech and let it dictate how you do things.
It’s funny how many customers I meet that have to massage their business processes around their gear instead of the other way around.
Anyway I’m going on a tangent… Probably best to save this for an actual post on my site 😉
Night
D
Comment by Dimitris Krekoukias — February 23, 2014 @ 1:29 am
Yes I agree, most systems do those things as well, 3PAR has added in end-to-end T10 data integrity protection as well in their latest ASIC(2011 I think).
Just a couple of nights ago for example I had a disk fairly suddenly fail in one of my arrays and I noticed that the system had migrated the data off of the disk in anticipation of failure(which took about two hours), then flagged the disk as bad(I got the alert at that point at 8PM on the dot). There is another disk in the system that has two bad chunklets (the system flags the disk as bad once 4 or 5 chunklets are failed).I remember checking the system recently to see the status of the disk that had two failed chunklets(if it had detected any more), and there was no change in status, so this particular disk that failed had no failed chunklets as of a few days ago anyway, so much more sudden, but not a failure like disk just decides to stop respond or something(have seen that with drives with manufacturing defects).
(I know NetApp does something very similar of course, though I do remember some funky requirement on NetApp’s side in the drive configuration that was required to make it possible, I don’t recall the details off hand though).
I hadn’t really spent much time looking at the raw logs but I found it interesting in this case, to see how the failed chunklets built up over a short period of time, and seeing the progression of the errors being detected/recovered from then the system evacuating the disk, and then later that night support replacing the disk.
(times are EST vs I am in PST)
2014/02/22 06:26:57 removed_obj sw_pd:0 Physical Disk 0 removed
2014/02/22 06:26:57 removed_obj sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 removed
2014/02/22 03:24:16 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Failed (Vacated, Missing, Invalid Media, Multiple Chunklets Media Bad, Servicing)
2014/02/22 03:24:16 disk_state_change sw_pd:0 pd 0 wwn 5000CCA01E0B4778 changed state from valid to missing because disk gone event was received for this disk.
2014/02/22 03:24:16 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Failed (Vacated, Missing A Port, Missing B Port, Invalid Media, Multiple Chunklets Media Bad, Servicing)
2014/02/22 03:23:45 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Failed (Vacated, Missing A Port, Invalid Media, Multiple Chunklets Media Bad, Servicing)
2014/02/22 03:23:02 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Failed (Vacated, Invalid Media, Multiple Chunklets Media Bad, Servicing)
2014/02/21 23:00:31 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Failed (Vacated, Invalid Media, Multiple Chunklets Media Bad)
2014/02/21 21:09:58 dskfail sw_pd:0 pd 0 failure: drive has multiple media failed chunklets- All used chunklets on this disk will be relocated.
2014/02/21 21:09:58 comp_state_change sw_cage_sled:0:0:0,sw_pd:0 Magazine 0:0:0, Physical Disk 0 Degraded (Invalid Media, Multiple Chunklets Media Bad)
2014/02/21 21:09:58 notify_comp sw_pd:0 (sysmgr : 12882) Drive wwn 5000CCA01E0B4778 is marked as failed since it has 6 failed chunklets, and the disk failure threshold number is 6
2014/02/21 21:09:58 mederr sw_pd:0,sw_ch:54 pd 0 ch 54 got media error
2014/02/21 18:38:37 mederr sw_pd:0,sw_ch:32 pd 0 ch 32 got media error
2014/02/21 18:24:43 mederr sw_pd:0,sw_ch:31 pd 0 ch 31 got media error
2014/02/21 17:19:46 mederr sw_pd:0,sw_ch:24 pd 0 ch 24 got media error
2014/02/21 17:00:54 mederr sw_pd:0,sw_ch:23 pd 0 ch 23 got media error
2014/02/21 14:34:10 mederr sw_pd:0,sw_ch:2 pd 0 ch 2 got media error
(removed a few other log lines that were just really verbose and hard to read in this format)
Another nice thing on the chunklet RAID though – no dedicated hot spares so I get the I/O from all the spindles but not only that, I don’t have to worry as much when disks do fail and would otherwise eat into a hot spare pool(thus limiting the ability to suffer further failures). I don’t remember what NetApp’s standards are for hot spare counts(my last in depth discussion with them was about two years ago – at which point the system size we were looking the impact was non trivial), but I do remember when talking with Compellent their “best practice” was to have one hot spare of each drive type of a given disk enclosure in each enclosure (wasn’t required but it was a best practice).
Something else I thought of just now while all this was going on is on a whole-disk RAID system, a media error impacts the entire disk(entire RAID group). vs on a sub disk RAID system it impacts only a small portion of the data(in my system with 256MB chunklets that would mean a media error would have to occur in the “right” other ~768MB of data on the system to be a double failure as an example). Newer 3PAR systems ship with 1GB chunklets (in part allows them to better scale the system to larger drives – my little baby system here has 21,628 RAID arrays on it, my T400 a few years back had over 100,000 towards the end of my time at that company). I’m sure their bigger boxes can go well over a million arrays.
I’ll certainly give the features flag to NetApp though you guys do have a lot of features, but with all of them in software scalability is more limited with so many potential things running simultaneously on top of the underlying I/O.
Comment by Nate — February 23, 2014 @ 10:14 am
Dimitris, Dimitris,
This is like Ground Hog day!
RE: “Application utilisation” – the last 4 3PAR SPC-1 results have 48%, 41%, 40%, 35%.
The last 4 NetApp FAS results have 60%, 61%, 37%, 37%.
If you want to discuss this metric – what the hell happened between (60 & 61) AND (37 & 37) ?? Why the big decrease? This big decrease obviously corresponds to the big increase in unused storage and the cluster mode Ontap 8.x submissions…
Simply answer this for me (us !) Dimitris – Why do Netapp suggest buying 86,830GB of storage and only use 50,542GB of it?? Why not buy less physical storage – decrease the cost – and make the $/SPC-1 IOPS much better?? Why leave 36,289GB of expensive spinning storage doing diddly squat nothing if there is no problem or inefficiency in higher more efficient utilisation rates ?
I know one thing I would bet on – if your SPC-1 performance engineers could use all that storage for ASU space and get the same number they would – so there must be a reason why they are not.
regards,
Paul.
Comment by Paul Haverfield [HP Storage] — February 23, 2014 @ 10:39 am
Hi Paul – what’s there to answer?
3Par’s current result is 35% application utilization.
I don’t think it means anything, I just mention it because you guys called out our number (which is still a bit higher).
By definition, you’re using RAID 10 which means half the capacity is wasted without ANY possibility of using more.
We at least have the ability to load more data onto the system if needed. You’ve lost the ability to do so with RAID 10.
Maybe answer me why 3Par doesn’t do RAID 6 SPC-1 submissions…
Given that SPC-1 is a write-intensive workload, the performance would tank.
Right? 😉
Comment by Dimitris Krekoukias — February 23, 2014 @ 12:03 pm
Don’t really agree there.. the usage of RAID 10 allows 3PAR (and others too I suppose) to leverage more of the provisioned capacity then otherwise would be possible and maintain high levels of performance with a large active data set. If your sitting there with RAID 5 or RAID 6 and half of your file systems are empty because the system can’t scale performance wise for more active data then…
I go into this specifically in some depth comparing 3PAR vs Pillar a few years ago(in that case both systems were RAID 10):
http://www.techopsguys.com/2010/10/09/capacity-utilization-storage/
Now if all of your workloads on the system are not active then you could have some workloads in RAID 10, some in 50, some in 60(on the same spindles) Get the best perf for the most important workloads and the most space for the low usage stuff. Or if one/more workloads only gets active during certain parts of the year (perhaps Q4 is really hot or something) then change them from 50 to 10 during that part of the year and change them back later. If RAID 5 is not enough data protection then go to RAID 60 or 10, if that is not enough you can go to triple or quadruple mirroring (on a per volume basis so very granular controls) for those workload(s) while letting other workloads leverage the same resources at measurably lower availability levels.
Or you could have a fairly static configuration that is likely to be significantly less efficient and when it comes time to get more performance or space or whatever you have little choice other than adding disks and arrays.
I like the flexibility myself, especially given I have worked for organizations who have never had the ability to accurately predict capacity or performance requirements (I figure this is fairly common in multi tenant situations especially for service providers and stuff).
Comment by Nate — February 23, 2014 @ 1:52 pm
Dimitris,
3PAR provides customers options for RAID levels and the ability to non-disruptively migrate between them within a few clicks. SPC-1 is all about performance; and the configurations built to obtain said performance. So – Yes – RAID10 gives us the best performance results for SPC-1 – which is why we use it. RAID60 would be something less than RAID10 – no secret there.
However, me thinks you are using the RAID level and application utilisation as a distracter from the real issue here… You say:
>>> Hi Paul – what’s there to answer?
Whats to answer is why the Ontap 8.x SPC-1 results leave such a significant amount of unused but purchased storage capacity. The results are only just legal as you well know at 43% and 42% – they cannot be > 45% per SPC-1 rules.
To me i’d speculate that Ontap 8.x performance cannot scale to use all available capacity efficiently. Full Stop. it is as simple as that.
Regards,
Paul.
Comment by Paul Haverfield [HP Storage] — February 23, 2014 @ 9:33 pm
Since NetApp is pushing its Cluster-mode so much lately, I was puzzled why NetApp only tested 2-controllers in its SPC-1 benchmark result. But then I remembered NetApp’s SPEC-sfs benchmark results using Cluster-mode where the per-node performance really tanked going from 2-nodes to 4-nodes. The NetApp 2-node 6420 SPEC-sfs result was 190,675 which would lead one to assume that a 4-node result would be around 380,000 IOPS. Instead it was 260,388. So, the first pair of controllers got 190,000 IOPS and the second pair only got 70,000.
Comment by Jim Haberkorn — February 24, 2014 @ 2:38 am
Jim – you’re comparing NAS 7-mode (not scale-out-capable) results to NAS cDOT (scale-out) worst-case results.
Your argument is therefore invalid. The 2 modes are different.
http://recoverymonkey.org/2011/11/01/netapp-posts-world-record-spec-sfs2008-nfs-benchmark-result/
We showed exactly linear scaling with cDOT.
The SPC-1 result we just posted was cDOT, as was the 6-node one with the 6240 before that.
Comment by Dimitris Krekoukias — February 24, 2014 @ 6:20 am
Dimitris – I think you missed the point. It makes no difference which version of ONTAP was used in the 2-node 6240 configuration. Regardless of which version of ONTAP is used, the SPEC-sfs benchmark clearly shows that NetApp’s Cluster-mode is highly inefficient when compared to a 2-node system. What the SPEC-sfs shows is that for performance reasons a customer would be far better off buying 2 x 7-mode FAS 6240s than a single 4-node system running Cluster-mode. With 2 x 7-mode 6240s the customer would get 380,000 SPEC-sfs IOPS. With a 4-node 6240 config in Cluster-mode it only gets 260,000. Clearly, Cluster-mode is highly inefficient.
Comment by Jim Haberkorn — February 24, 2014 @ 8:21 am
Excerpt from my article (http://recoverymonkey.org/2011/11/01/netapp-posts-world-record-spec-sfs2008-nfs-benchmark-result/):
“Lest we be accused of tuning this config or manually making sure client accesses were load-balanced and going to the optimal nodes, please understand this: 23 out of 24 client accesses were not going to the nodes owning the data and were instead happening over the cluster interconnect (which, for any scale-out architecture, is worst-case-scenario performance). Look under the “Uniform Access Rules Compliance†in the full disclosure details of the result in the SPEC website here. This means that, compared to the 2-node ONTAP 7-mode results, there is a degradation due to the cluster operating (intentionally) through non-optimal paths.”
With direct IO we would be accused of rigging the benchmark, with intentional indirect IO we are accused of being slower.
We chose to portray worst-case.
In addition – you’re confusing SPEC and SPC-1. Very different benchmarks, but then again 3Par doesn’t play in the former since it can’t do NAS, so I guess it’s understandable.
We play in both benchmarks with the exact same gear.
Oh – and FC access uses direct paths automatically.
Hopefully this was educational.
Thx
D
Comment by Dimitris Krekoukias — February 25, 2014 @ 12:03 pm
Thanks for the extra info Dimitris, However – can I bring your interest back to the core theme of Nates original blog topic – Capacity inefficiency within the OnTap 8.x SPC-1 results…
You said:
>>> Hi Paul – what’s there to answer?
Whats to answer is why the Ontap 8.x SPC-1 results leave such a significant amount of unused but purchased storage capacity. The results are only just legal as you well know at 43% and 42% – they cannot be > 45% per SPC-1 rules.
From a customer perspective – a 42% Unused Storage Ratio on the FAS8040 result represents $207,133 of capital investment they will not realise any performance benefit / scaling from. Another view – 36.2TB of capacity they cannot realise peak performance from…
regards,
Paul.
Comment by Paul Haverfield [HP Storage] — February 25, 2014 @ 1:38 pm
Dmitris: I read carefully through your response, and if I throw out the abrupt change of subjects, the red herrings, and the playful digs, I find that we didn’t really have a disagreement after all! Thank you for confirming that, indeed, a 4-node NetApp cluster gets significantly less performance than 2 x 2-node clusters of the same model.
The reason why this is an important issue is that existing NetApp 7-mode customers are being strongly encouraged by NetApp to move to Cluster-mode for a variety of reasons, most of which reasons aren’t valid. Performance is one of them. A NetApp customer should never even consider moving to Cluster-mode because of performance. Thank you for acknowledging that.
But one more point: in its SPEC-sfs benchmark result under discussion, NetApp didn’t really set up their array to get ‘worse case’ results as you stated multiple times. Nor did 23 out of 24 accesses go to the wrong node – remember, we are talking here about a 4-node cluster not a 24-node cluster. No vendor in the history of performance benchmarking would ever set up their array to get the worse possible results. In the case of a cluster, worse case would be every IO going to the wrong node. What NetApp did was simply to run the benchmark – not any different than what most other vendors do when running the SPECsfs. But I suspect you knew that already.
Comment by Jim Haberkorn — February 26, 2014 @ 3:15 am
(Sigh)
Jim, unsure how you think I proved that in general 4-way is slower than a 2-way.
The 23 out of 24 indirect access number was for the 24-node cluster. The 4-node had 3 out of 4.
Again, this is regarding the NFS benchmark and would not apply to FC anyway, so you using the results of that NFS benchmark to derive generic conclusions is misguided at best. Clustered ONTAP is here, it’s cool and solves a wider variety of business problems than any other storage system.
But it’s ok. I don’t respond to make you happy – but rather to clear any confusion for potential customers reading this stuff. They can draw their own conclusions and can always chat with their local NetApp team and ask for my input.
Thx
D
Comment by Dimitris Krekoukias — February 27, 2014 @ 7:55 am
Just to summarize.
1. Buy 4 controllers with NetApp Cluster-mode, get 260,388 IOPS. Buy 4 controllers with NetApp 7-mode and you get 380,675 IOPS – a full 120,000 IOPS more.
4. Conclusion: NetApp Cluster-mode is very inefficient.
Comment by Jim Haberkorn — March 3, 2014 @ 3:05 am
Just to summarize.
1. Buy 4 controllers with NetApp Cluster-mode, get 260,388 IOPS. Buy 4 controllers with NetApp 7-mode and you get 380,675 IOPS – a full 120,000 IOPS more.
2. Conclusion: NetApp Cluster-mode is very inefficient.
Comment by Jim Haberkorn — March 3, 2014 @ 3:10 am
If you have 90% writes, you should be using Flashpools not flashcache. This allows you to accelerate all of your writes and reads at the same time. It should be helpful for your systems, and all you would need is one shelf of these Flashpools, which is essentially just a shelf of SSD’s that actually caches all your writes immediately and slowly migrates it to your SAS or SATA drives when the system is not busy.
Comment by Evan — March 20, 2014 @ 2:40 pm
I’ll keep this short…
The Haberkorn Fallacy (yes, it’s now a thing, Jim) is that since the SPEC SFS (NAS) results show one thing, this must also hold true for all Clustered ONTAP vs 7-mode performance, including SAN.
Things don’t work the way you think they do in this case.
But to understand that you need the knowledge of how multipathing for SAN is done in ONTAP, and does that change between 7-mode and cDOT.
You also need to understand the reason for the delta between the NAS results (which is a test that has NOTHING to do with SAN workloads). I explained it and it’s even shown in the full disclosure, but you chose to ignore it.
Again – I’m merely responding here so that people looking at the comments don’t get confused by The Haberkorn Fallacy 🙂
Thx
D
Comment by Dimitris Krekoukias — March 21, 2014 @ 11:55 am
I know this is an SPC-1 discussion, but Jim H’s SPEC SFS NAS numbers are correct. On the surface, it appears like the NetApp 6240 cDot 4-node benchmark is 120K IOPS less efficient than extrapolating the 6240 7-mode (by definition two nodes) benchmark numbers up to four nodes. But by using my poor public school math skills and Little’s Law, the reason for this the cDot config has a higher ORT 1.53ms vs 7-mode 1.17ms. Each individual 6240 controller, whether running cDot or 7-mode, is doing the same amount of work (actually a bit more on the cDot controllers).
The cDot benchmark was designed to highlight scale-out performance in an NFS3 environment, taking advantage of the cDot Global NameSpace, and thus 3/4ths of the IO going across the cluster fabric. Notice how the benchmark numbers scale up linearly from 4 nodes to 24 nodes – clearly cDOT is very very efficient. NetApp could have setup the NFS3 mounts in the cDot benchmark just like the 7-mode benchmark, or used pNFS, and been in the 380K IOP ballpark like 7-mode. All scale-out storage cluster fabrics introduce latency regardless of the vendor.
The goals for the cluster fabric are to get the latency as low as possible and use it as little as possible for data traffic. cDOT does this very well, primarily relying on the cluster fabric for non-data serving functions such as rich manageability features and non-stop operations.
Bringing this back to the original SAN SPC-1 discussion, with NetApp in the FC-SAN space, ALUA + MPIO avoids the cluster interconnect just like pNFS. I think this is where much of the confusion comes from.
Comment by paulb — March 21, 2014 @ 12:34 pm
Dimitris,
Regarding the capacity utilisation at which CDOT would seem to achieve peak performance at (approx. 40% utilisation) – I found this quote in NetApp TR-4078 “Best Practices for NetApp Infinite Volume in Data ONTAP 8.1.x Operating in Cluster-Mode” – page 12 –
5.2 Capacity Management – Best Practises:
“To avoid hot spots, NetApp recommends adding storage space when the data constituent capacity approaches 60%.”
Is this why with CDOT it would appear you cannot achieve both real-world utilisation levels (like > 70% capacity usage) AND good performance at the same time ?? …I sniff a smoking gun – however – for some reason that document is no longer available at the NetApp media library – but it is still published here:
http://www.globbtv.com/microsite/18/Adjuntos/_TR-4078_INFINITEVOLUME_BPG.PDF
Regards,
Paul.
Comment by Paul Haverfield [HP Storage] — March 26, 2014 @ 5:44 pm