I noticed a few days ago that IBM posted some new SPC-1 results based on their SVC system, this time using different back end storage- their Storwize product (something I had not heard of before but I don’t pay too close of attention to what IBM does they have so many things it’s hard to keep track).
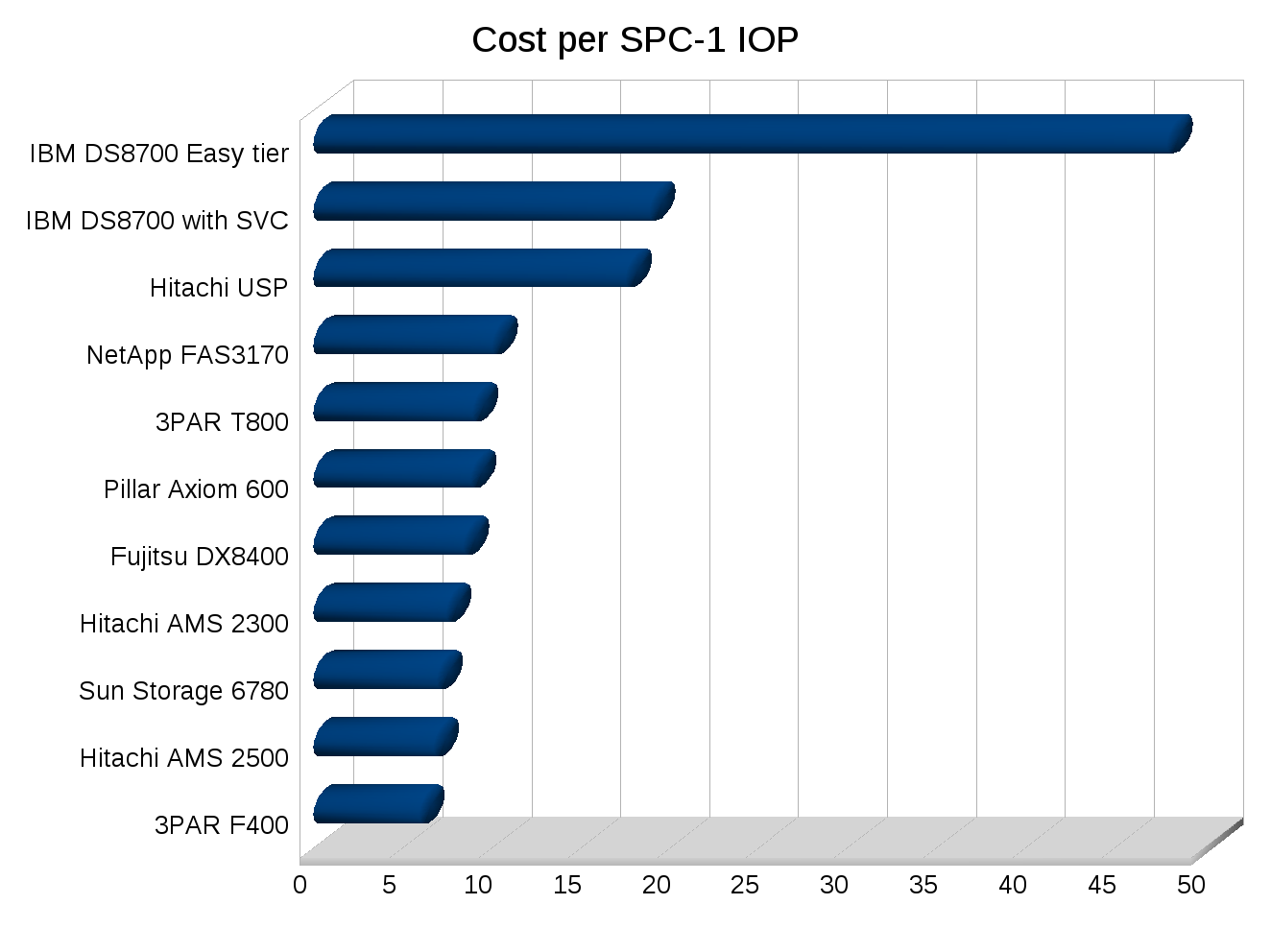
The performance results are certainly very impressive, coming in at over 520,000 IOPSÂ at a price of $6.92 per IOP. This is the sort of results I was kind of expecting from the Hitachi VSP a while back. IBM tested with 1,920 drives the same number as the 3PAR V800. They bested the 3PAR performance by a good 70,000 IOPS with half the latency on the same number of disks and less data cache.
The capacity numbers were, and still are, sort of difficult to interpret they seem to give conflicting information. IBM is using ~138TB of disk space to protect ~99TB of disk space. While 3PAR is using ~263TB of disk space to protect ~263TB of disk space. Both results say there is 30TB+ of “unused storage” in that protection scheme.
Bottom line is the IBM box is presented with roughly 280TB of storage, and of that, 100TB is usable, or about 35%. That brings their cost per usable TB number to $36,881/TB vs the 3PAR V800 which is roughly $12,872. The V800 I/O cost was $6.59, which IBM comes real close to.
IBM has apparently gone the same route as HDS in the only 3.5″ drives they support on their Storwize systems are 3TB SATA disks. They hamper their own cost structure by not supporting larger 3.5″ 15k RPM SAS disks, which just doesn’t make sense to me. There are 300GB 15k SAS drives out and Storwize doesn’t support those either(yet at least).
It took about five pages of scripting to configure the system from the looks of the full disclosure report.
Certainly looks like a halfway decent system. I mean if you compare it to the VSP for example it has the same array virtualization abilities with the SVC, it is sporting almost double the amount of disk drives, almost double the raw performance, configuration at least appears to be less complicated. It uses those power efficient 2.5″ disks just like the VSP. It also costs quite a bit less than the VSP both on per-IOP and per-TB basis. It also appears to have mainframe support for those that need that. From the looks of Seagate 15k RPM disks at least the 2.5″ drives have an average of 15% less latency for random reads and writes than their 3.5″ counterparts. I thought the difference might be bigger than that given how much less distance the disk heads have to travel.
If I was in the market for such a big system, these results wouldn’t lead me away from 3PAR, at least based on the pricing disclosed of each system (and level of complexity to configure). I was interviewing a candidate a few weeks ago and this guy had a strong storage background. Having worked for Symantec I think for a while he was doing some sort of consulting at various companies for storage. I asked him how he provisioned storage, what his strategies were. His response was quite surprising. He said usually the vendors come out, deploy their systems and provision everything up front, all he does is carve out LUNs and present them to users. He had never been involved in the architecture planning or deployment of a storage system. He acted as if what he was doing was the standard practice (maybe it is at large companies I’ve never worked at such an organization), and that it was perfectly normal.
But it certainly seems like a good system when put up against at least the VSP, and probably the V-MAX too.
I’ve always been interested in the SVC by itself, certainly seems like a cool concept, I’ve never used one of course but having the ability to cluster at that intermediate level(in this case a 8-node cluster which may be the max I’m not sure) and then scale out storage behind it. Clearly they’ve shown with this you can pump one hell of a lot of I/O through the thing. They also seem to have SSD tiering support built into it which is nice as well.
Hopefully HP can come up with something similar at some point, as much as they talk smack about the likes of SVC today.
{kind=link}