My good friend Chuck over at EMC (ok we’ve never met but he seems like a nice guy, we could be friends) wrote an interesting article about Investing in IT vs Spending on IT. I thought it was a really good read, I hadn’t thought of things in that way, but it made me realize I am one who wants to Invest in IT infrastructure, even if it means paying more up front, the value add of some solutions are just difficult to put numbers on.
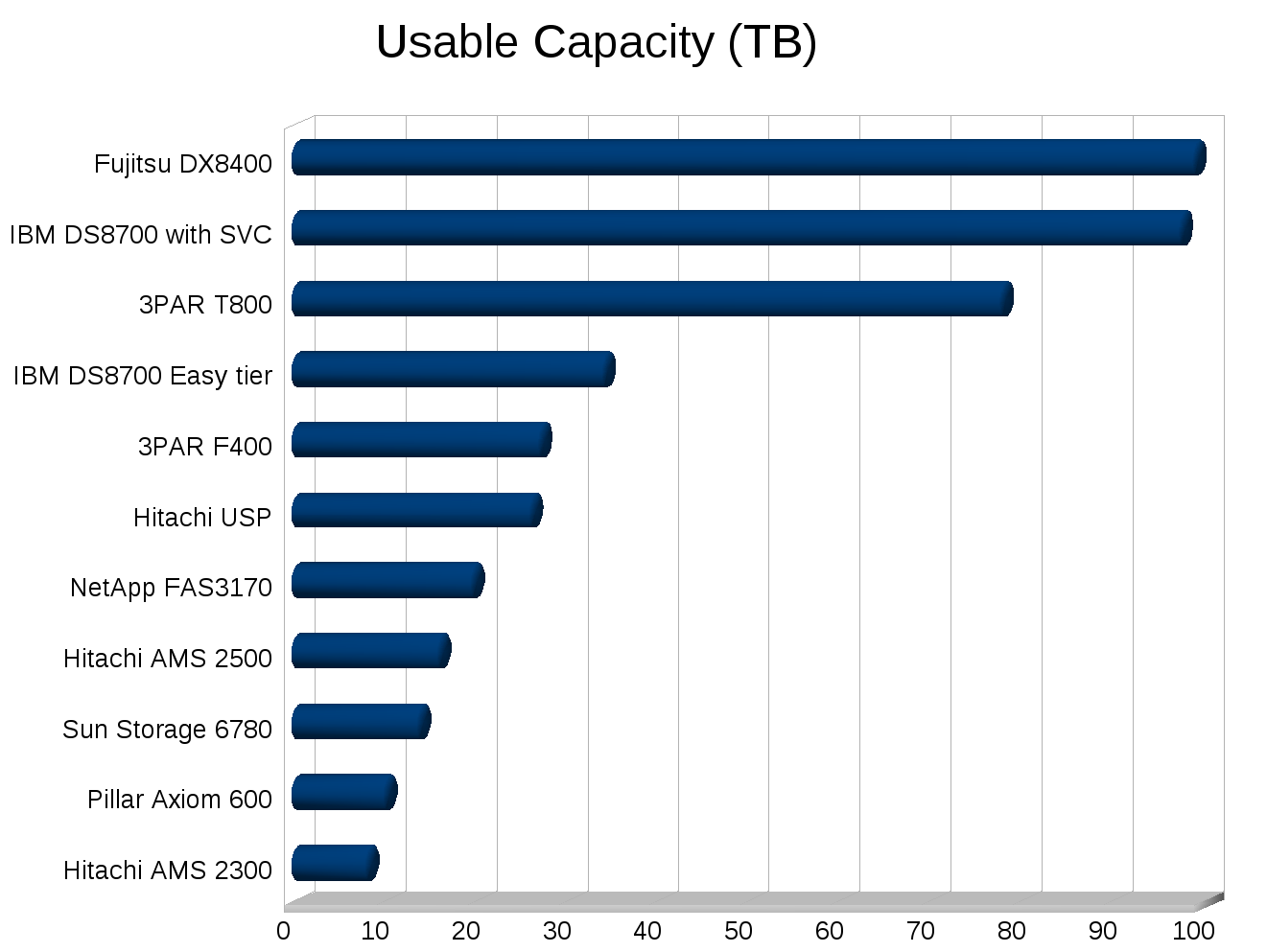
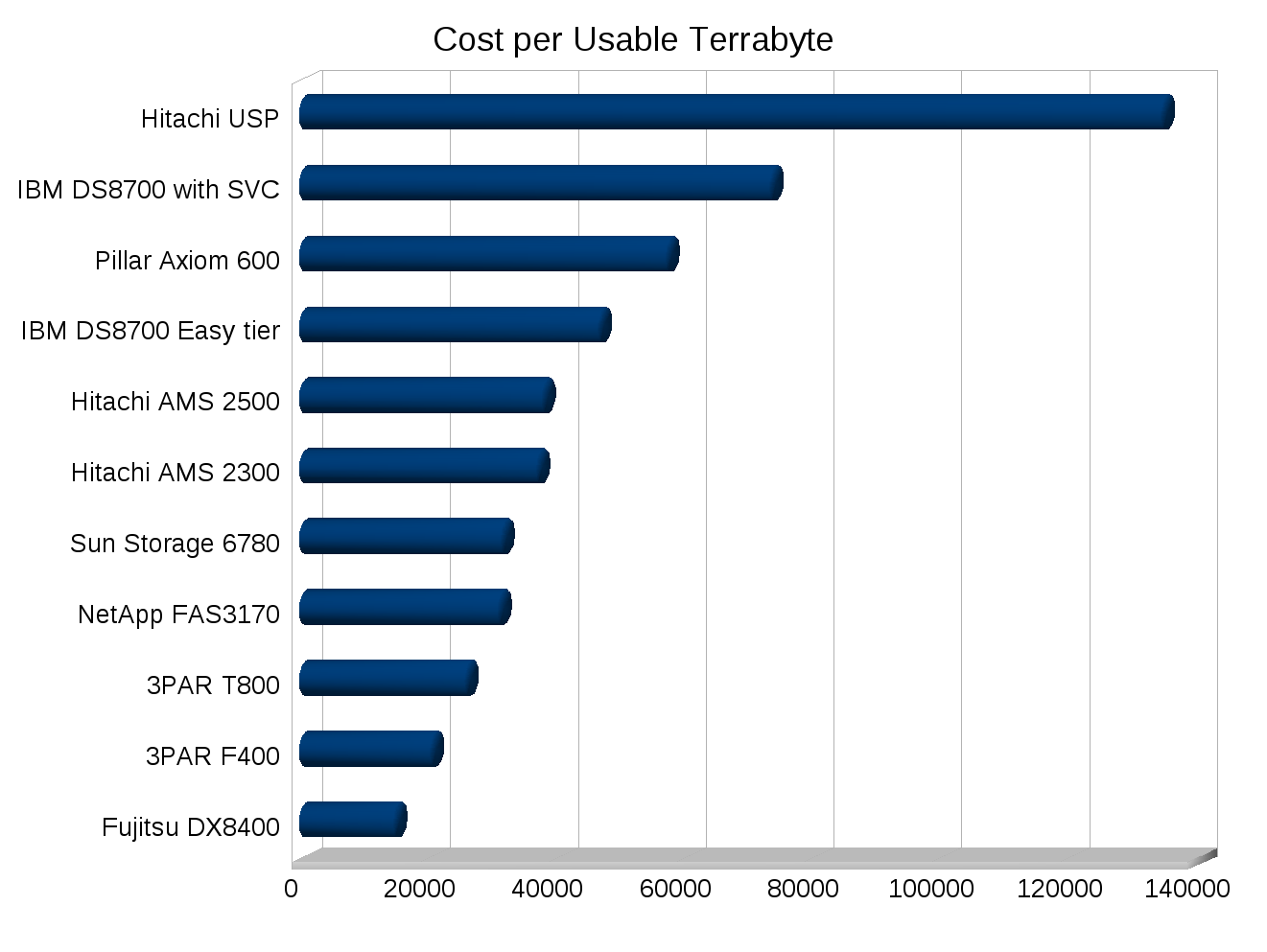
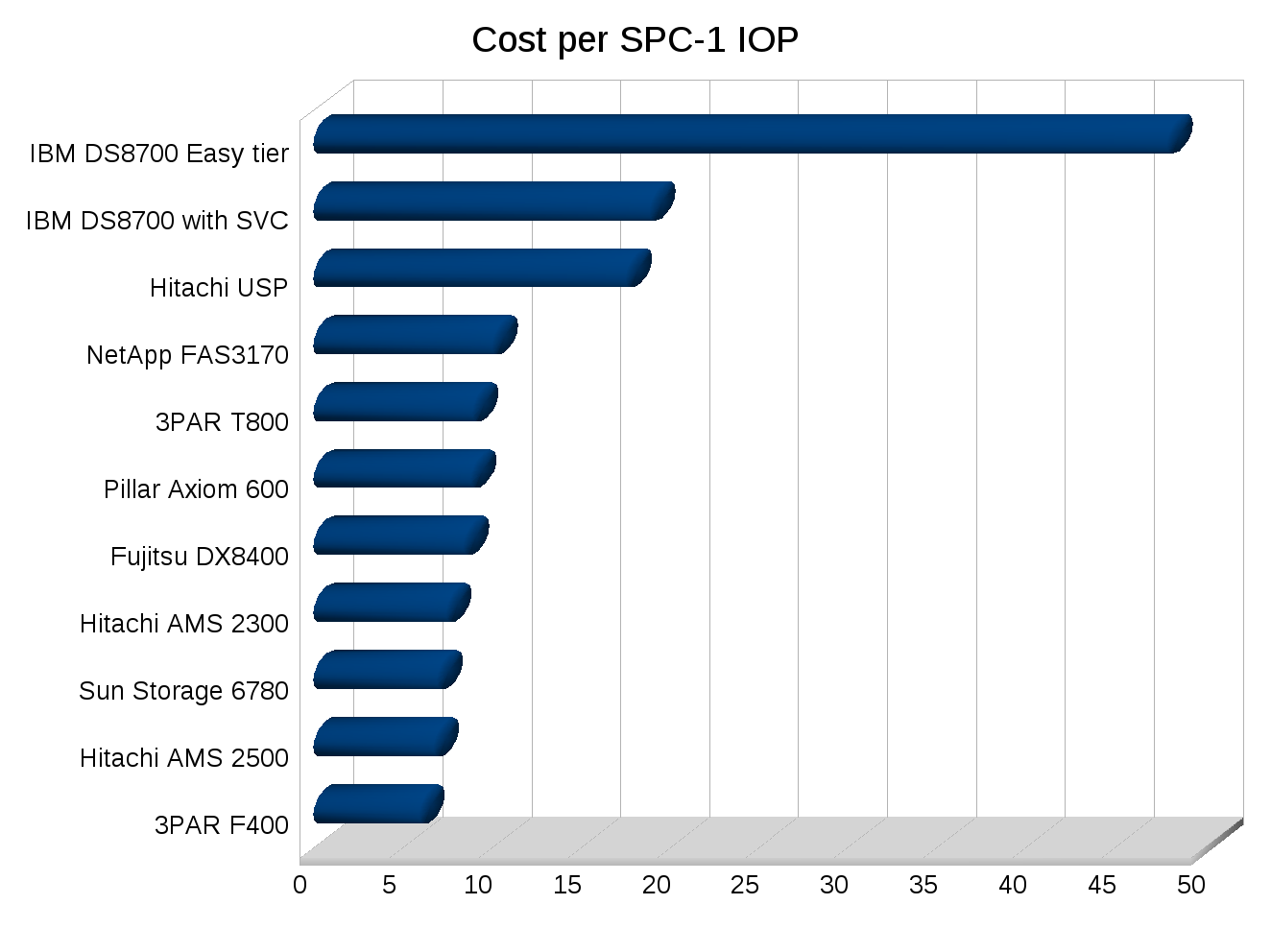
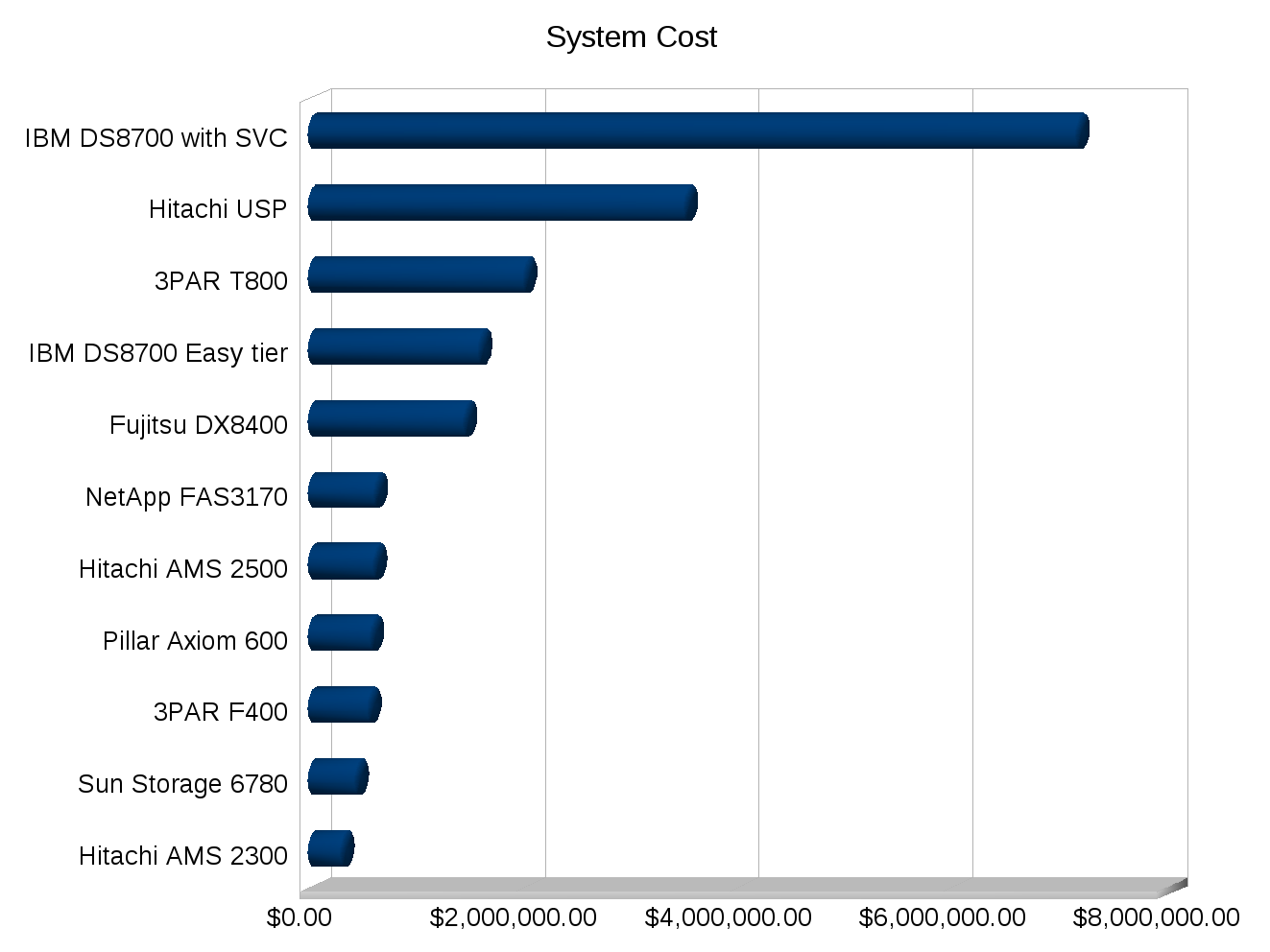
Take storage for example, since Chuck is a storage guy. There’s a lot more to storage than cost per TB, cost per IOP, cost per usable TB, and even more than cost of power+cooling for the solution. The smaller things really do add up over time, but how do you put numbers on them? Something as simple as granular monitoring, when I went through a storage refresh a while back the currently established vendor really had no way of measuring the performance of their own system to develop a plan for a suitable technology refresh. It wasn’t a small system either it was a big fairly expensive (for the time) one.
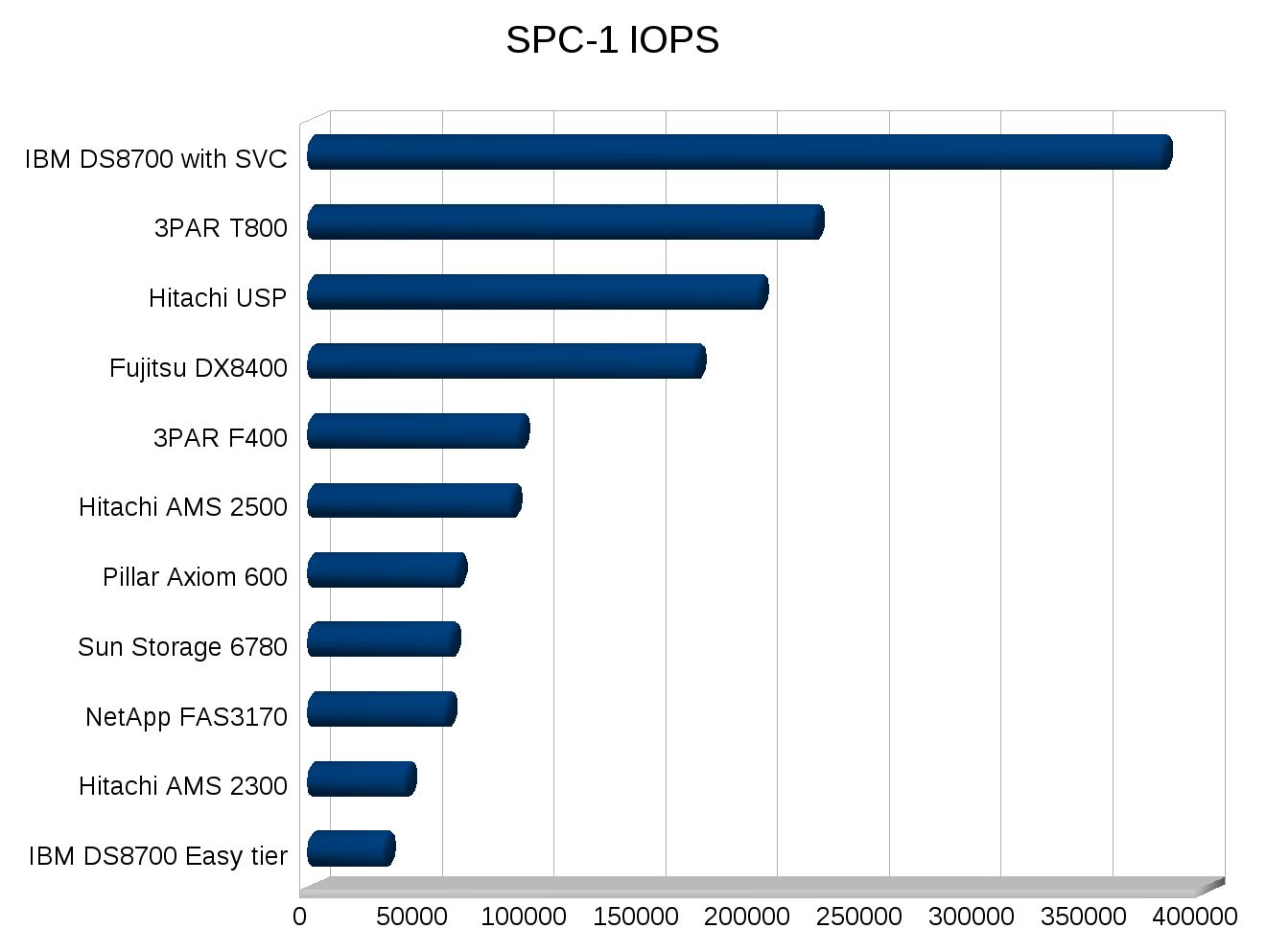
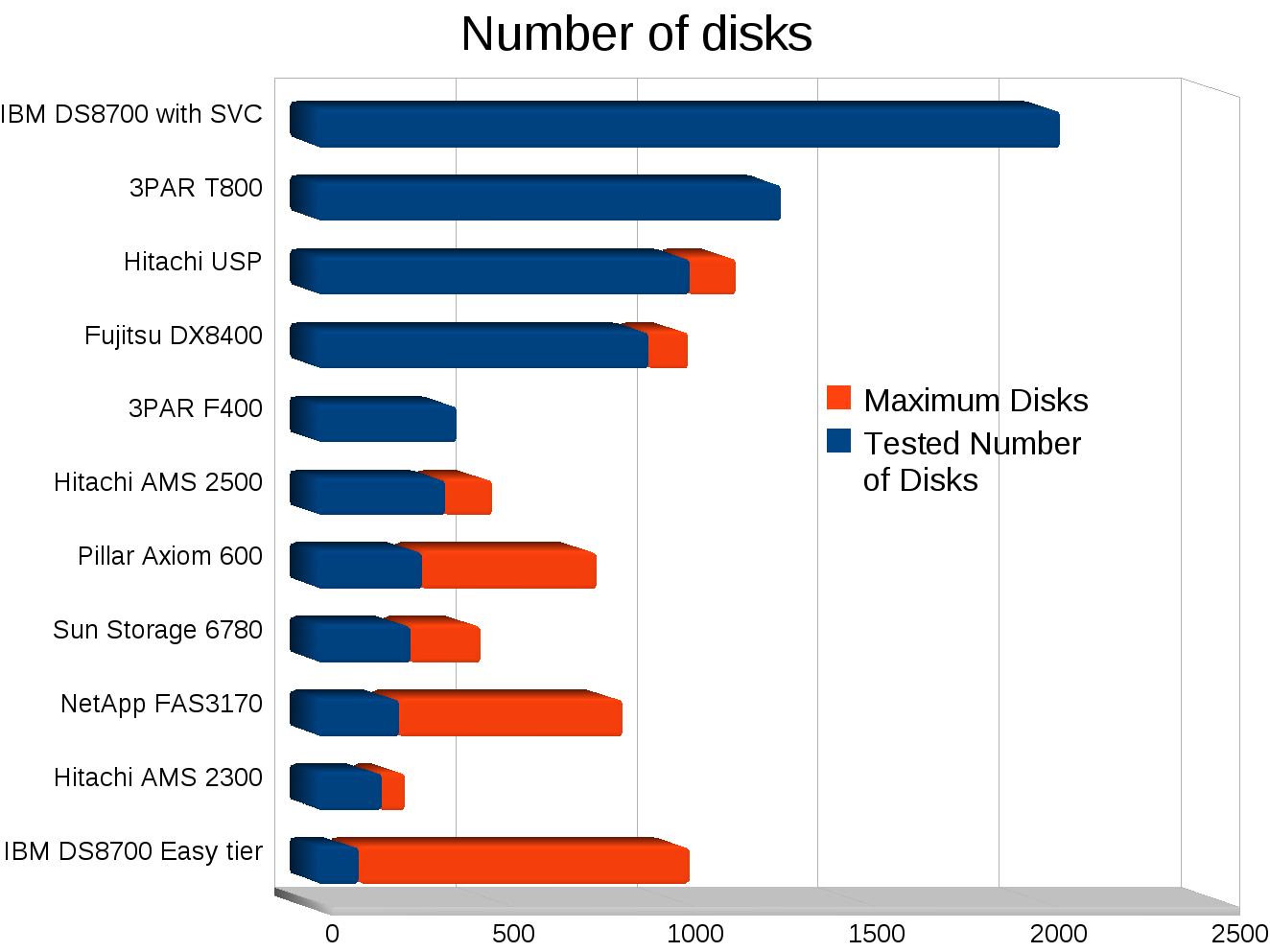
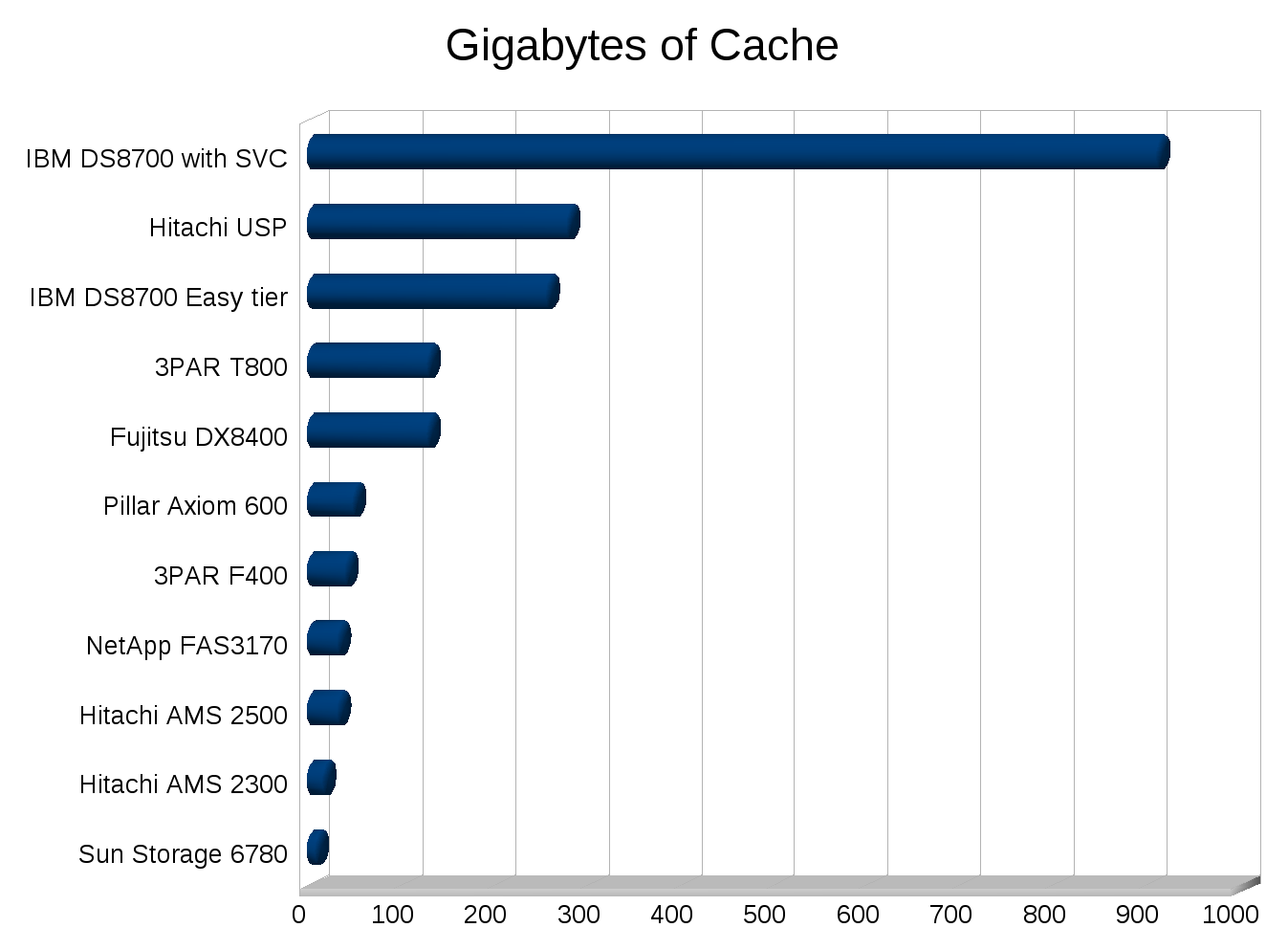
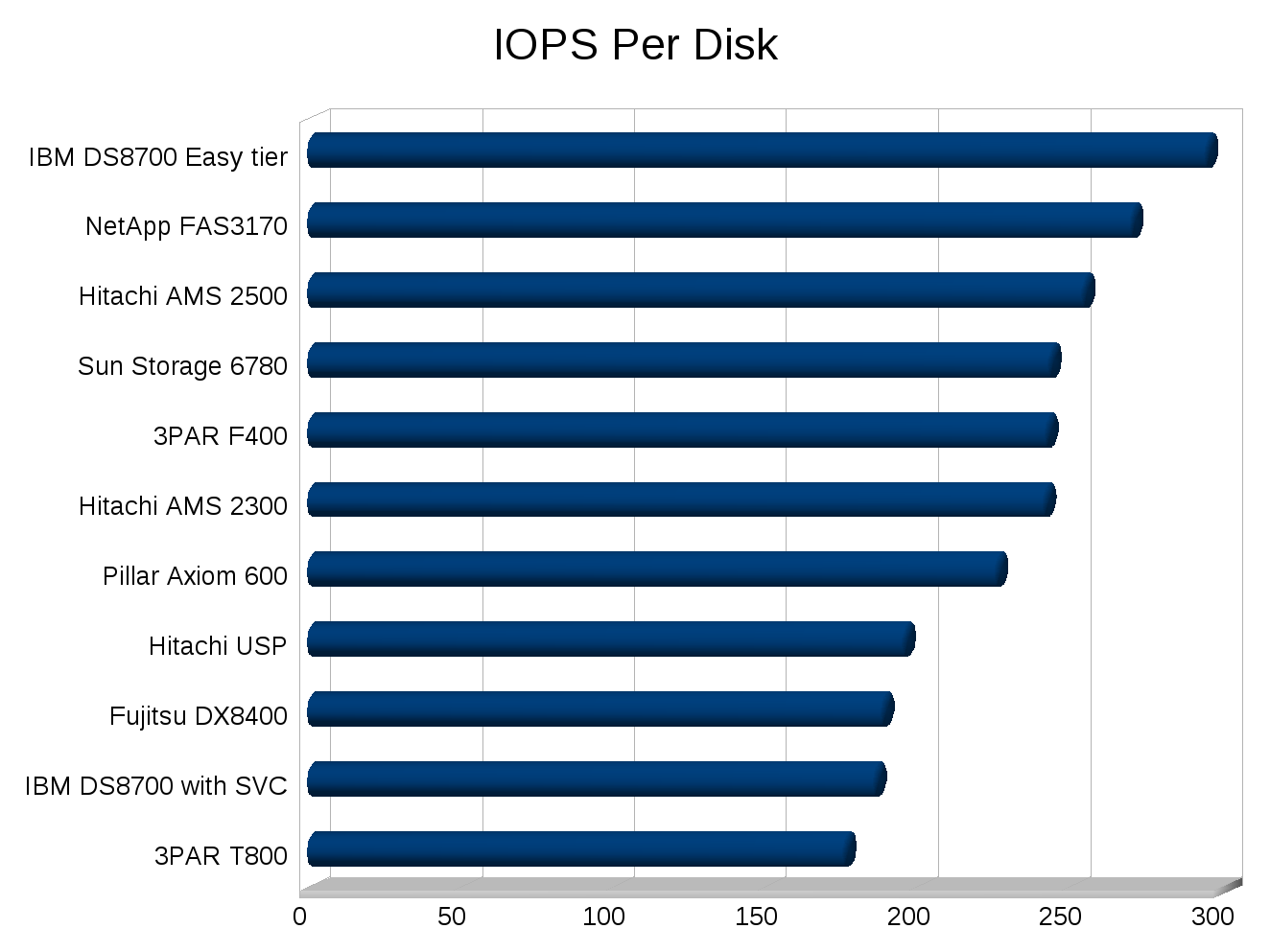
Would you of expected to replace one storage system with another that had less than half the number of disks, and roughly 75% less raw IOPS (on paper)? Would you of expected the new system to not only outperform and out scale the old but continue to eat a significant amount of growth over the following year before needing an upgrade? If your a normal person I would expect you to not expect that. But that’s what happened.
In my experience, my approach is to establish a track record at an organization, this may take a few months, or may take a year(may be much longer if it’s a big company). Once you have established X number of successful projects, a higher degree of trust is put in you to have more lateral control and influence on how things work. Less hand holding, less minute justifications are required to get your point across, and you can get more things done.
Maybe that thinking is too logical, I don’t know. It’s how I think though, myself I put more faith in people the more I see how good they are at their jobs, I trust them more, if they turn out to provide good solutions or even good angles of thought I believe I can rely more on them to do that line of work than to work over their shoulder double checking everything. I think it’s how you can scale. Of course not all employees measure up, I would say especially in larger organizations most do not(government is especially bad I hear).
No one person can run it all, as much as they’d like. I’ve tried, and well the results while not horrible weren’t as good as having more people doing the work. I learned the hard way to delegate more work, whether it’s to co-workers, or to contractors, or even to vendors. People take vendors for granted, there is a lot of experience and knowledge they can bring to the table, not all vendor teams are created equal of course.
If you just want to spend on IT, don’t hire someone like me, I don’t want to work for you. If you want to invest in IT, to give your organization more leadership in new technologies that can improve efficiencies and lower costs, then you may want someone like me. Which is why I gravitate towards smaller higher technological organizations. They usually don’t have the economies of scale to do things as well as the big guns out there, so it’s up to people like me to develop innovative solutions to compete differently. If you read the blog you’ll see I don’t subscribe to any one vendor stack. I like many different products from many different vendors depending on what the requirements are.
From a vendor perspective (since it’s been 5 years since I worked with a contractor of sorts) I do like to have a good relationship with the vendor, they can be a valuable source of information. Vendors either love me or hate me, it really depends on their products, as folks that have worked with me can attest. It also depends on how technical the vendor can get with me. I like to go deep into the technical realm. And I believe I do challenge the System Engineers at my vendors with tough questions. Those that don’t measure up don’t last long. I have high expectations of myself, and I have high expectations of those around me, frequently too high. I don’t like to play political games where you try to screw them over because you know they’ll screw you back the first chance you get. Having a good relationship is one of those things it’s hard to put a number on. To me it’s worth a decent amount.
Jake, another person on this blog(hi Jake!) is similar, though he’s a lot more loyal than me, which again can be a good thing as well. Changing technology paths every 15 minutes is not a good idea, having a dozen different server vendors in your racks because different ones provided 5-10% better pricing at that particular time of day is not a good idea either.
Speaking of Jake, I remember when I first started at my previous company and they were doing negotiations with Oracle on licensing. They were out of compliance on licensing(they paid for Oracle SE One but were using Oracle EE) and were facing hefty fines. I tried to propose an alternative solution (going to Oracle Standard Edition which is significantly different from SE One), which would of saved significant amounts of money with really no loss in functionality(for our apps at the time). I was a new(literally a few weeks) employee and Jake dismissed my opinion, which I could understand at the time I was new and had no track record, nobody knew if I knew what I was talking about. It was OK though, so they paid their fines, and licensed some new Oracle stuff as part of the settlement.
The next year rolled around and Oracle came back again to do an audit, and once again found massive numbers of violations and the company was once again facing large amounts of penalties to get back in compliance. Apparently the previous process wasn’t as transparent as they expected, either the Oracle rep was misleading the company or was generally incompetent, I don’t know since I wasn’t involved in those talks.
Once again I strongly urged the company to migrate to Standard Edition to slash licensing costs, this time they listened to me. It took a few weeks to get all of the environments migrated over, including a full weekend of my time migrating production doing all sorts of unsupported things to get it done(value adds for you) to minimize downtime (while you can go from Oracle SE to EE without downtime typically you can’t do it the other way around). Went the extra mile to establish a standby DB server with log replication and consistent database backups(because you can’t run RMAN against a standby DB at least you couldn’t on 10GR2 at the time), all of it worked great, and we (as expected) slashed our Oracle licensing fees.
Of course I didn’t have to do that, I could of sat by and watched them pay up in fees again(several hundred thousand dollars in total). But I did do it, I did go to them and say I’m willing to work my ass off for several weeks to do this to save you money. Many people I’ve come across I don’t think have the dedication to volunteer for such an effort, they’ll of course do it if asked, but frequently won’t push hard so they can work more. What did I get out of it? I suppose more than anything a sense of accomplishment and pride. I certainly didn’t get any monetary rewards from the company. I didn’t get to re-allocate that portion of the budget towards things we were in very desperate need for.
The only frustrating part of the whole situation was when we licensed Oracle EE originally the optimal CPU configuration at the time was the fastest dual core CPUs you could get. So we ordered a HP DL 380G5 I think it was with dual proc dual core CPUs. Given the system was marked as compatible with 4 core systems I figured it would be an easy switch when or if we went to Standard edition (which charges per socket not per core, a fact I had to correct Oracle’s own reps on more than one occasion). But when the time came it turned out that we had to replace the motherboard on the HP system because the particular part number we had was not compatible with quad core. It took lots of support calls and HP reps insisting that our system was compatible before someone dug further into the details and found out it was not. But we got the board and CPUs replaced and still of course came out way ahead.
When I come up with solutions it’s not half assed. You may have a problem and ask me and I may have an immediate solution for your problem, but it’s not because I just read about it on slashdot that morning. My solutions are heavily thought out over a period of months or years (usually years), and it’s not obvious to people that I work with (or for, often enough) how much thought actually went into a particular solution regardless of the amount of time that elapsed since you posed the question to me. I love technology and I am always on the hunt for what I consider best of breed in whatever industry that the product is in. I’m not afraid to get my hands dirty, I’m not afraid to stand by my decisions in the event I make a mistake, and I really like to operate in an environment of trust.
Would it surprise you that I led an effort to launch an e-commerce site on top of VMware GSX back in early 2004 so my company’s customer would be satisfied? How many of you were running production facing VMware servers back then? Were they doing credit card transactions? I only did it because the company’s software failed to install properly during a system upgrade, and in order to keep the customer happy we decided to build them their own stand alone cluster, went from 0 to fully functional and tested in about 96 hours, most of that time was NOT sleeping.
And before you ask, NO I am not one of those people who is going to go suggest an open source solution for every problem on the planet just because it’s free. I use open source where I believe it adds value regardless of the cost, and use commercial, closed platforms (whether it’s VMware or even Oracle) where I believe they can add value. Don’t equate creative solutions with using free software across the board. That’s just as stupid as using a closed source ecosystem for all of your IT infrastructure.You won’t catch me trying to replace your active directory server with a Samba+LDAP system. You could catch me trying to do that – 10 years ago -. I’m long passed all that.
I can only speak for myself, but let me do my job and you won’t be disappointed. I’m not afraid to say I am one of those people who can do some pretty amazing things given the right resources, if your on linkedin you can check the recommendations on my profile for some examples.
So, round about, thanks Chuck that was a good read. Getting all of this written down really makes me feel a bit better too.