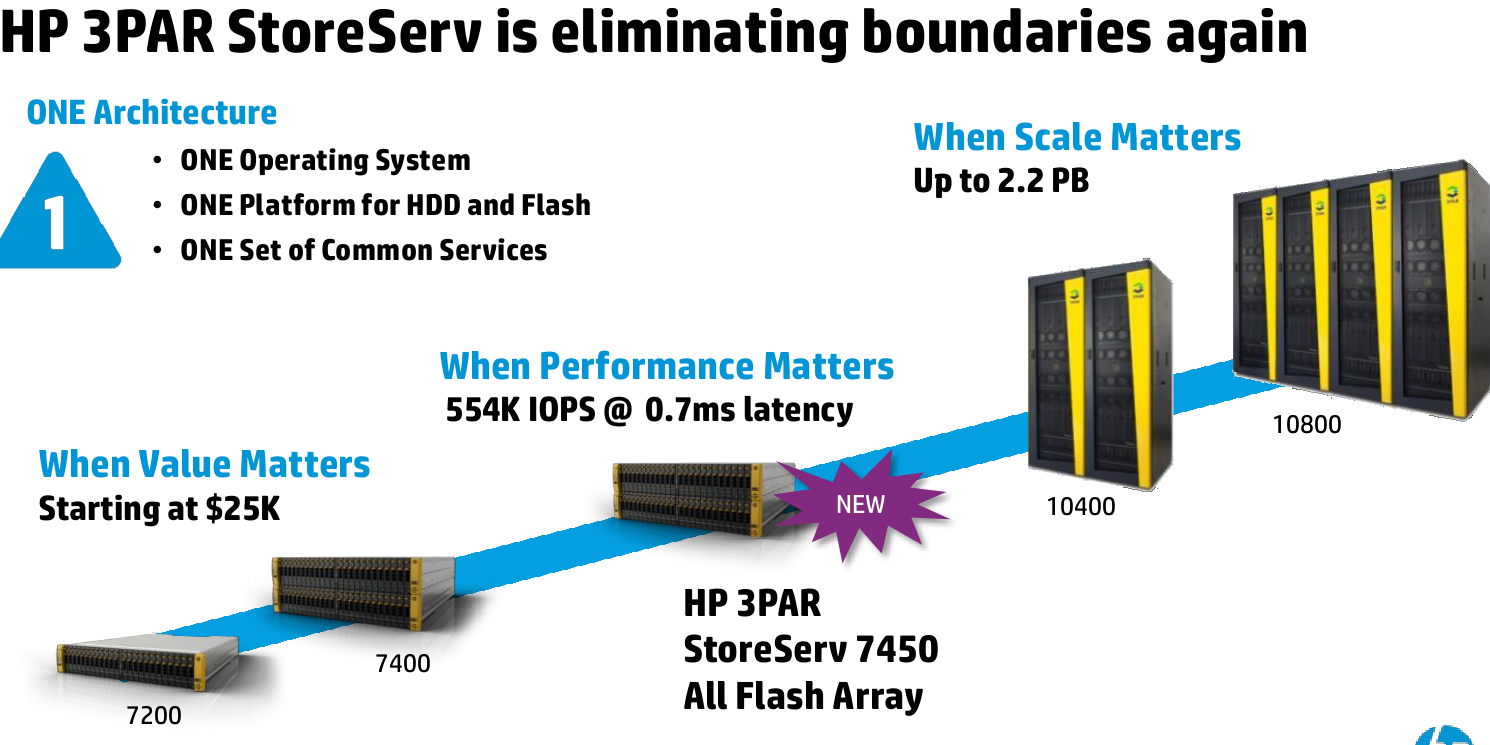
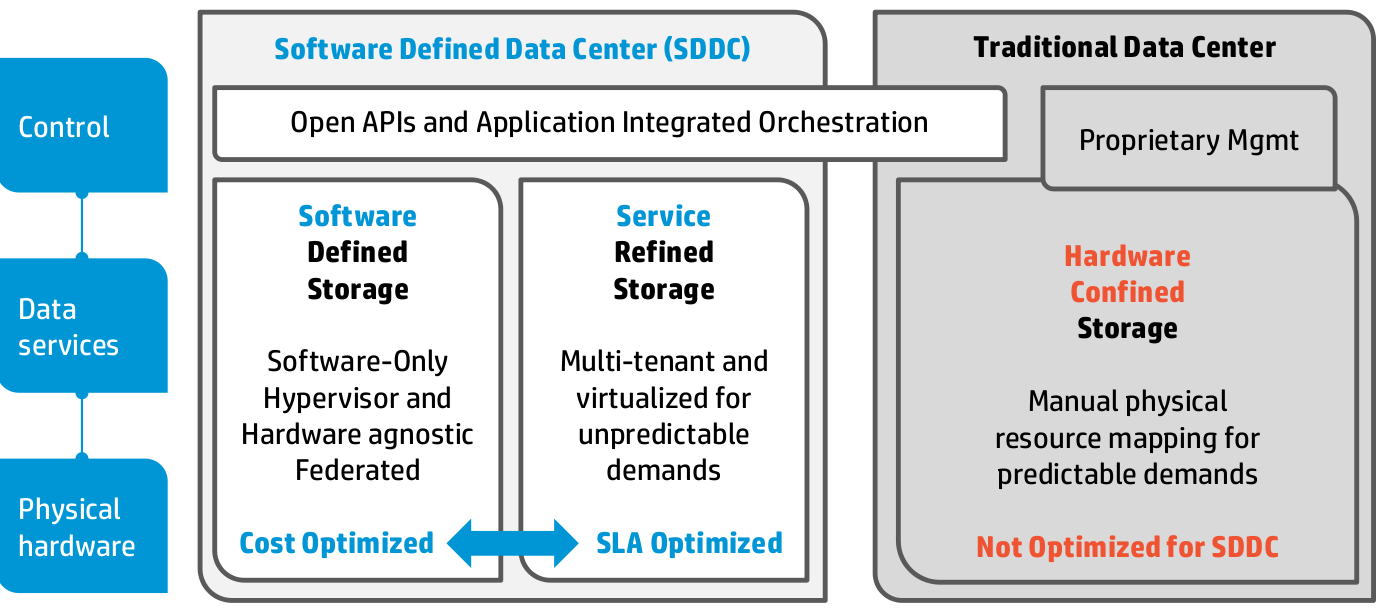
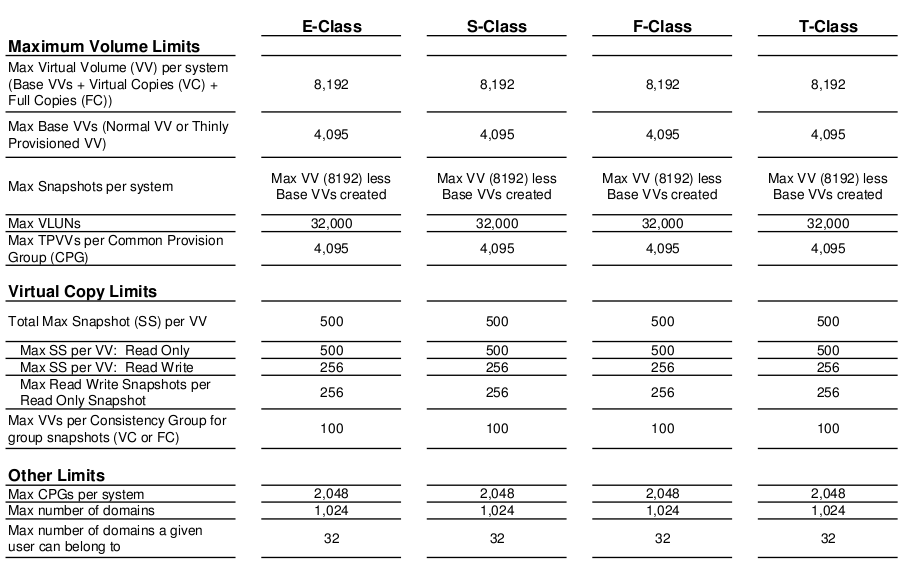
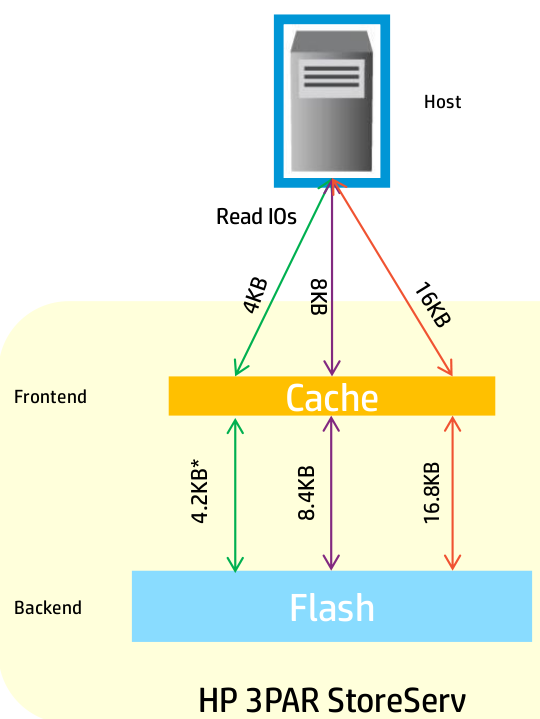
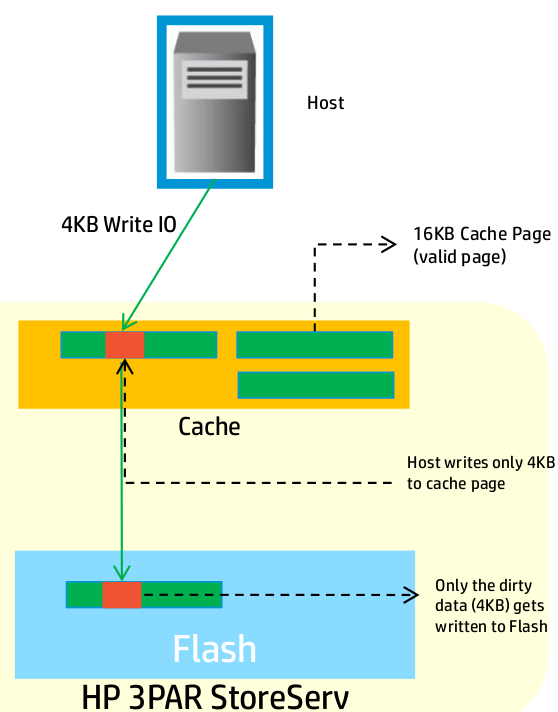
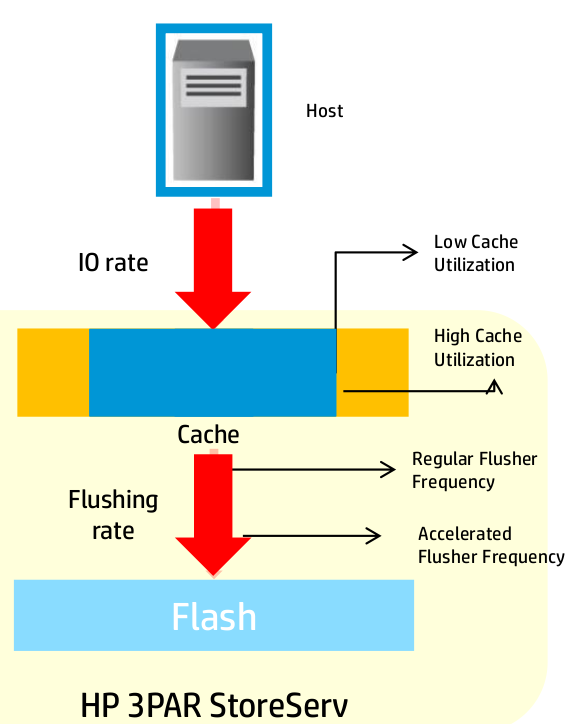
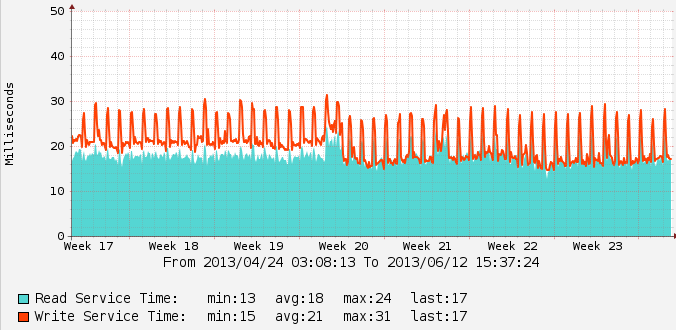
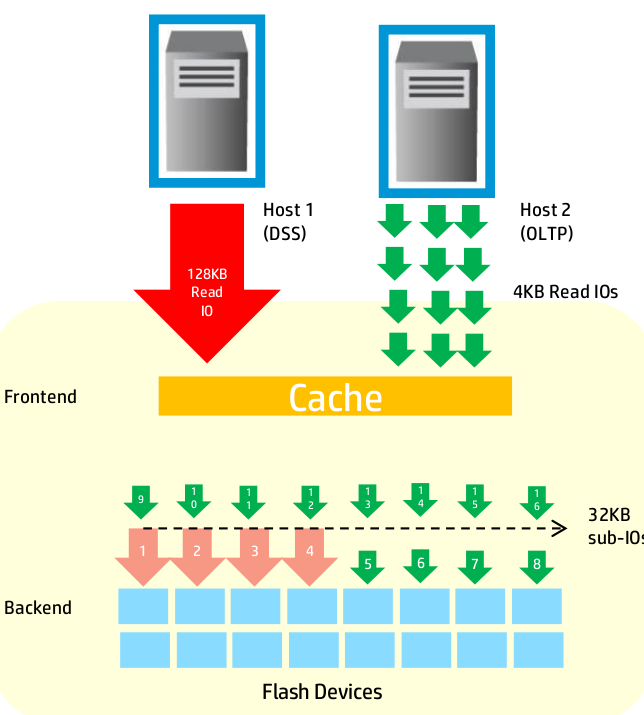
Travel to HP Storage Tech Day/Nth Generation Symposium was paid for by HP; however, no monetary compensation is expected nor received for the content that is written in this blog.
For my last post on HP Storage tech day, the remaining topics that were only briefly covered at the event.
HP Converged Storage Management
There wasn’t much here other than a promise to build YASMT (Yet another storage management tool), this time it will be really good though. HP sniped at EMC on several occasions for the vapor-ness of ViPR. Though at least that is an announced product with a name. HP has a vision, no finalized name, no product(I’m sure they have something internally) and no dates.
I suppose if your in the Software defined storage camp which is for the separation of data and control plane, this may be HP’s answer to that.
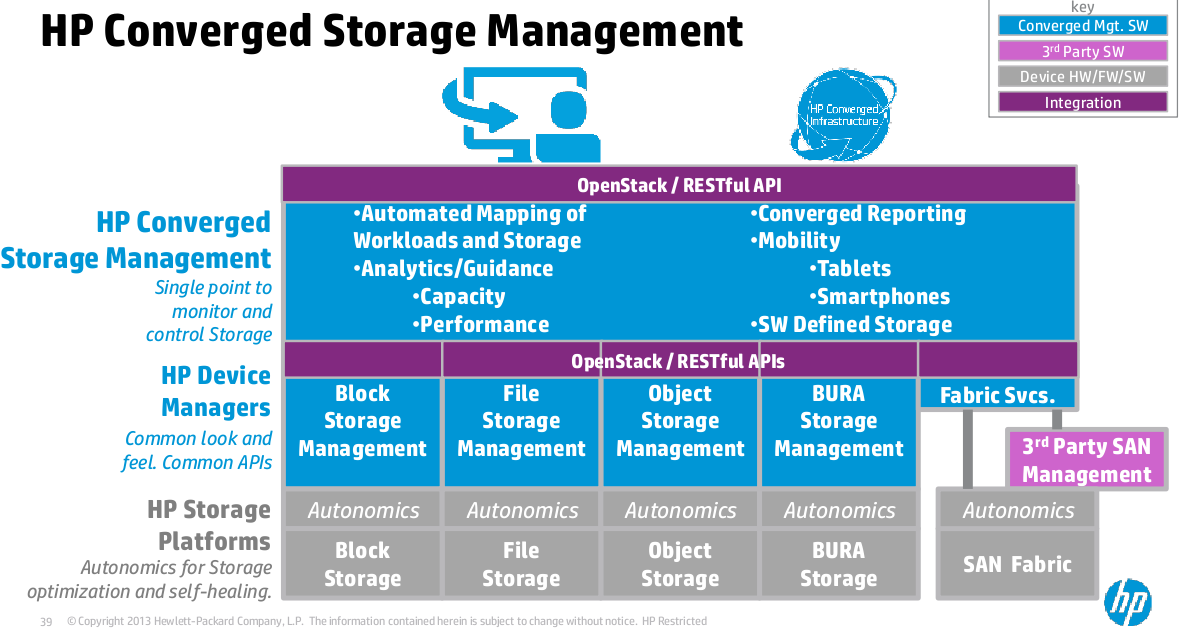
HP Converged Storage Management Strategy
The vision sounds good as always, time will tell if they can pull it off. The track record for products like this is not good. More often than not the tools lower the bar on what is supported to some really basic set of things, and are not able to exploit the more advanced features of the platform under management.
One question I did ask is whether or not they were going to re-write their tools to leverage these new common APIs, and the answer was sort of what I expected – they aren’t. At least short term the tools will use a combination of these new APIs as well as whatever methods they use today. So this implies that only a subset of functionality will be available via the APIs.
In contrast I recall reading something, perhaps a blog post, about how NetApp’s tools use all of their common APIs(I believe end to end API stuff for them is fairly recent). HP may take a couple of years to get to something like that.
HP Openstack Integration
HP is all about the Openstack. They seem to be living and breathing it. This is pretty neat, I think Openstack is a good movement, though the platform still seems some significant work to mature.
I have concerns, short term concerns about HP’s marketing around Openstack and how easy it is to integrate into customer environments. Specifically Openstack is a fast moving target, lacks maturity and at least as recently as earlier this year lacked a decent community of IT users (most of it was centered on developers – probably still is). HP’s response is they are participating deeply within the community (which is good long term), and are being open about everything (also good).
I specifically asked if HP was working with Red Hat to make sure the latest HP contributions (such as 3PAR support, Fibre Channel support) were included in the RH Open Stack. They said no, they are working with the community, and not partners. This is of course good and bad. Good that they are being open, bad in that it may result in some users not getting things for 12-24 months because the distribution of Openstack they chose is too old to support it.
I just hope that Openstack matures enough that it gets a stable set of interfaces. Unlike say the Linux kernel driver interfaces which just annoy the hell out of me(have written about that before). Compatibility people!!!
Openstack Fibre Channel support based on 3PAR
HP wanted to point out that the Fibre Channel support in Openstack was based on 3PAR. It is a generic interface and there are plugins for a few different array types. 3PAR also has iSCSI support for Openstack as of a recent 3PAR software release as well.
StoreVirtual was first Openstack storage platform
Another interesting tidbit is that Storevirtual was the first(?) storage platform to support Openstack. Rackspace used it(maybe still does, not sure), and contributed some stuff to make it better. HP also uses it in their own public cloud(not sure if they mentioned this or not but I heard from a friend who used to work in that group).
HP Storage with Openstack
Today HP integrates with Openstack at the block level on both the StoreVirtual and 3PAR platforms. Work is in progress for StoreAll which will provide file and object storage. Fibre channel support is available on the 3PAR platform only as far as HP goes. StoreVirtual supports Fibre Channel but not with Openstack(yet anyway, I assume support is coming).
This contrasts with the competition, most of whom have no Openstack support and haven’t announced anything to be released anytime soon. HP certainly has a decent lead here, which is nice.
HP Openstack iSCSI/FC driver functionality
All of HP’s storage work with Openstack is based on the Grizzly release which came out around April 2013.
- Create / Delete / Attach / Detach volumes
- Create / Delete Snapshots
- Create volume from snapshot
- Create cloned volumes
- Copy image to volume / Copy volume to image (3PAR iSCSI only)
New things coming in Havana release of Openstack from HP Storage
- Better session management within the HP 3PAR StoreServ Block Storage Drivers
- Re-use of existing HP 3PAR Host entries
- Support multiple 3PAR Target ports in HP 3PAR StoreServ Block Storage iSCSI Driver
- Support Copy Volume To Image & Copy Image To Volume with Fibre Channel Drivers (Brick)
- Support Quality of Service (QoS) setting in the HP 3PAR StoreServ Block Storage Drivers
- Support Volume Sets with predefined QoS settings
- Update the hp3parclient that is part of the Python Standard Library
Fibre channel enhancements for Havana and beyond
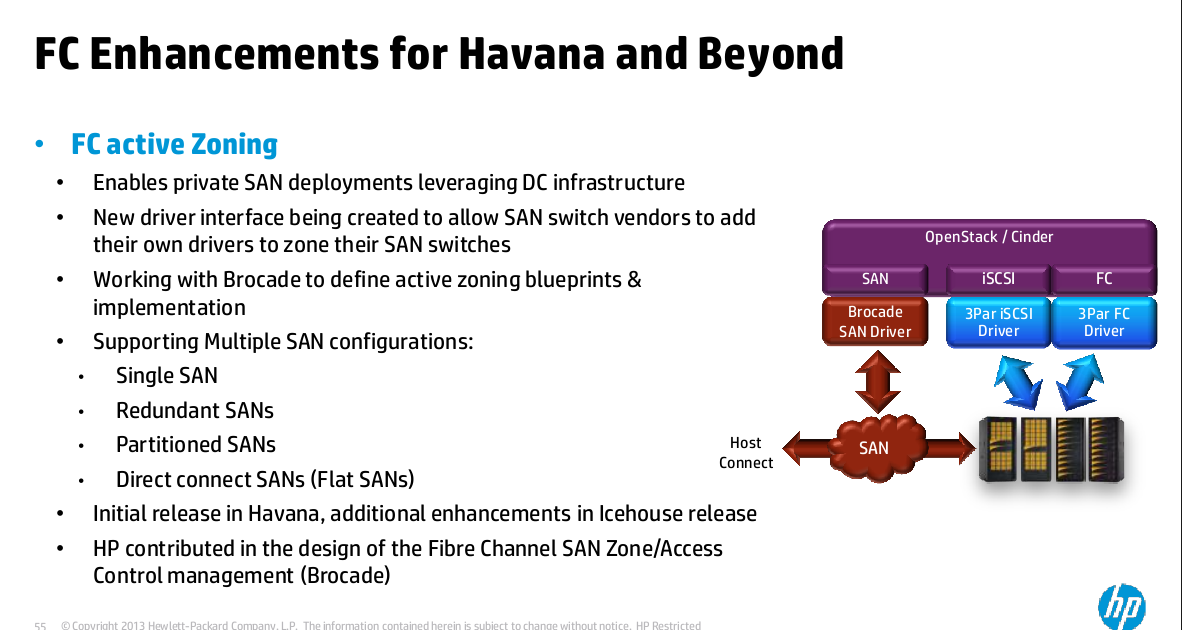
Fibre Channel enhancements for Openstack Havana and beyond
Openstack portability
This was not at the Storage Tech Day – but I was at a break out session that talked about HP and Openstack at the conference and one of the key points they hit on was the portable nature of the platform, run it in house, run it in cloud system, run it at service providers and move your workloads between them with the same APIs.
Setting aside a moment the fact that the concept of cloud bursting is a fantasy for 99% of organizations out there(your applications have to be able to cope with it, your not likely going to be able to scale your web farm and burst into a public cloud when those web servers have to hit databases that reside over a WAN connection the latency hit will make for a terrible experience).
Anyway setting that concept aside – you still have a serious problem- short term of compatibility across different Openstack implementations because different vendors are choosing different points to base their systems off of. This is obviously due to the fast moving nature of the platform and when the vendor decides to launch their project.
This should stabilize over time, but I felt the marketing message on this was a nice vision, it just didn’t represent any reality I am aware of today.
HP contrasted this to being locked in to say the vCloud API. I think there are more clouds public and private using vCloud than Openstack at this point. But in any case I believe use cases for the common IT organization to be able to transparently leverage these APIs to burst on any platform- VMware, Openstack, whatever – is still years away from reality.
If you use Openstack’s API, you’re locked into their API anyway. I don’t leverage APIs myself(directly) I am not a developer – so I am not sure how easy it is to move between them. I think the APIs are likely much less of a barrier than the feature set of the underlying cloud in question. Who cares if the API can do X and Y, if the provider’s underlying infrastructure doesn’t yet support that capability.
One use case that could be done today, that HP cited, is running development in a public cloud then pulling that back in house via the APIs. Still that one is not useful either. The amount of work involved in rebuilding such an environment internally should be fairly trivial anyway(the bulk of the work should be in the system configuration area, if your using cloud you should also be using some sort of system management tool, whether it is something like CFEngine, Puppet, Chef, or something similar). That and – this is important in my experience – development environments tend to not be resource intensive. Which makes it great to consolidate them on internal resources (even ones that share with production – I have been doing this since for six years already).
My view on Openstack
At least one person at HP I spoke with believes most stuff will be there by the end of this year but I don’t buy that for a second. I look at things like Red Hat’s own Openstack distribution taking seemingly forever to come out(I believe it’s a few months behind already and I have not seen recent updates on it), and Rackspace abandoning their promise to support 3rd party Open stack clouds earlier this year.
All of what I say is based on what I read — I have no personal experience with Openstack (nor do I plan to get immediate experience, the lack of maturity of the product is keeping me away for now). Based on what I have read, conferences(was at a local Red Hat conference last December where they covered Openstack – that’s when reality really hit me and I learned a good deal about it and honestly lost some enthusiasm in the project) and some folks I have chatted/emailed with Openstack is still a VERY much work in progress, evolving quickly. There’s really no formal support community in place for a stable product, developers are wanting to stay at the leading edge and that’s what they are willing to support. Red Hat is off in one corner trying to stabilize the Folsum release from last year to make a product out of it, HP is in another corner contributing code to the latest versions of Openstack that may or may not be backwards compatible with Red Hat or other implementations.
It’s a mess.. it’s a young project still so it’s sort of to be expected. Though there are a lot of folks making noise about it. The sense I get is if you are serious about running an Open Stack cloud today, as in right now, you best have some decent developers in house to help manage and maintain it. When Red Hat comes out with their product, it may solve a bunch of those issues, but still it’ll be a “1.0”, and there’s always some not insignificant risk to investing in that without a very solid support structure inside your organization (Red Hat will of course provide support but I believe that won’t be enough for most).
That being said it sounds like Openstack has a decent future ahead of it – with such large numbers of industry players adopting support for it, it’s really only a matter of time before it matures and becomes a solid platform for the common IT organization to be able to deploy.
How much time? I’m not sure. My best guesstimate is I hope it can reach that goal within five years. Red Hat, and others should be on versions 3 and perhaps 4 by then. I could see someone such as myself starting to seriously dabble in it in the next 12-16 months.
Understand that I’m setting the bar pretty high here.
Last thoughts on HP Storage Tech Day
I had a good time, and thought it was a great experience. They had very high caliber speakers, were well organized and the venue was awesome as well. I was able to drill them pretty good, the other bloggers seemed to really appreciate that I was able to drive some of the technical conversations. I’m sure some of my questions they would of rather not of answered since the answers weren’t always “yes we’ve been doing that forever..!”, but they were honest and up front about everything. When they could not be, they said so(“can’t talk about that here we need a Nate Disclosure Agreement”).
I haven’t dealt much at all with the other internal groups at HP, but I can say the folks I have dealt with on the storage side have all been AWESOME. Regardless of what I think about whatever storage product they are involved with they are all wonderful people both personally and professionally.
These past few posts have been entirely about what happened on Monday. There are more bits that happened at the main conference on Tues-Thur, and once I get the slides for those slide decks I’ll be writing more about that, there were some pretty cool speakers. I normally steer far clear of such events, this one was pretty amazing though. I’ll save the details for the next posts.
I want to thank the team at HP, and Ivy Worldwide for organizing/sponsoring this event – it was a day of nothing but storage (and we literally ran out of time at the end, one or two topics had to be skipped). It was pretty cool. This is the first event I’ve ever traveled for, and the only event where there was some level of sponsorship (as mentioned HP covered travel, lodging and food costs).