(Cue Star Trek: The Next Generation theme music)
[Side note: I think this is one of my most popular post ever with nearly 3,000 hits to it so far (excluding my own IPs). Thanks for reading!]
[I get the feeling I will get lots of people linking to this since I suspect what is below will be the most complete guide as to what was released – for those of you that haven’t been here before I am in no way associated with HP or 3PAR – or compensated by them in any way of course! Just been using it for a long time and it’s one of the very few technologies that I am passionate about – I have written a ton about 3PAR over past three years]
HP felt their new storage announcements were so ground breaking that they decided to have a special event a day before HP Discover is supposed to start. They say it’s the biggest announcement for storage from HP in more than a decade.
I first got wind of what was coming last Fall, though there wasn’t much information available at the time other than a picture and some thoughts as to what might happen. Stuff wasn’t nailed down yet. I was fortunate enough to finally visit 3PAR HQ a couple of months ago and get a much more in depth briefing as to what was coming, and I’ll tell you what it’s been damn hard to contain my excitement.
HP announced a 75% year over year increase in 3PAR sales, along with more than 1,200 new customers in 2012 alone. Along with that HP said that their StoreOnce growth is 45% year over year.
By contrast HP did not reveal any growth numbers for either their Lefthand StoreVirtual platform nor their IBRIX StoreAll platforms.
David Scott, former CEO of 3PAR tried to set the tone as a general storage product launch, they have enhancements to primary storage, to file/object scale-out storage as well as backup/archive storage.
You know I’m biased, I don’t try to hide that. But it was obvious to me at the end of the presentation this announcement was all about one thing: David’s baby – 3PAR.
Based on the web site, I believe the T-class of 3PAR systems is finally retired now. Replaced last year by the V-Class (aka P10000 or 10400 and 10800)
Biggest changes to 3PAR in at least six years
The products that are coming out today are in my opinion, the largest set of product (AND policy) enhancements/changes/etc from 3PAR in at least the past six years that I’ve been a customer.
First – a blast from the past.
The first mid range 3PAR system – the E200
Hello 2006!
There is some re-hashing of old concepts, specifically the concept of mid range. 3PAR introduced their first mid range system back in 2006, which was the system I was able to deploy – the E200. The E200 was a dual node system that went up to 4GB data cache per controller and up to 128 drives or 96TB of usable capacity whichever came first. It was powered by the same software and same second generation ASIC (code named Eagle if I remember right) that was in the high end S-class at the time.
The E200 was replaced by the F200, and the product line extended to include the first quad controller mid range system the F400 in 2009. The F-class, along with the T-class (which replaced the S-class) had the third generation ASIC in it (code named Osprey if I remember right?? maybe I have those reversed). The V-class which was released last year, along with what came out today has the 4th generation ASIC (code named Harrier).
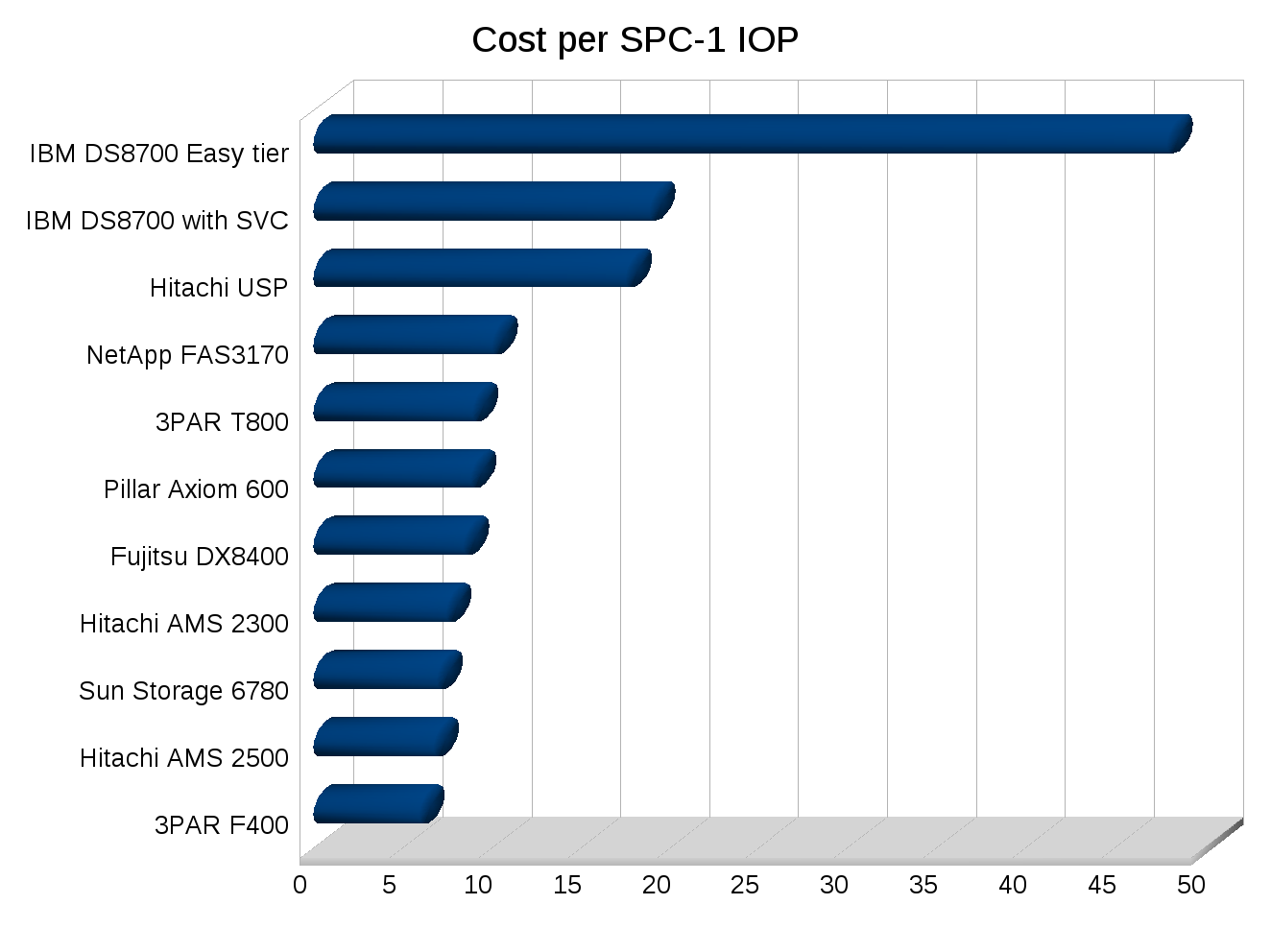
To-date – as far as I know the F400 is still the most efficient SPC-1 result out there, with greater than 99% storage utilization – no other platforms (3PAR included) before or since have come close.
These systems, while coined mid range in the 3PAR world were still fairly costly. The main reason behind this was the 3PAR architecture itself. It is a high end architecture. Where other vendors like EMC and HDS chose radically different designs for their high end vs. their mid range, 3PAR aimed a shrink ray at their system and kept the design the same. NetApp on the other hand was an exception – they too have a single architecture that scales from the bottom on up. Though as you might expect – NetApp and 3PAR architectures aren’t remotely comparable.
Here is a diagram of the V-series controller architecture, which is very similar to the 7200 and 7400, just at a much larger scale:

3PAR V-Series ASIC/CPU/PCI/Memory Architecture
Here is a diagram of the inter-node communications on an 8-node P10800, or T800 before it, again similar to the new 7000-series just larger scale:

3PAR Cluster Architecture with low cost high speed passive backplane with point to point connections totalling 96 Gigabytes/second of throughput
Another reason for the higher costs was the capacity based licensing (& associated support). Some things were licensed per controller pair, some things based on raw capacity, some things licensed per system, etc. 3PAR licensing was not very friendly to the newbie.
Renamed Products
There was some basic name changes for 3PAR product lines:
- The HP 3PAR InServ is now the HP 3PAR StorServ
- The HP 3PAR V800 is now the HP 3PAR 10800
- The HP 3PAR V400 is now the HP 3PAR 10400
The 3PAR 7000-series – mid range done right
The 3PAR 7000-series leverages all of the same tier one technology that is in the high end platform and puts it in a very affordable package, starting at roughly $25,000 for a two-node 7200 system, and $32,000 for an entry level two-node 7400 system(which can later be expanded to four nodes, non disruptively).
I’ve seen the base 7200 model (2 controllers, no disks, 3 year 24×7 4-hour on site support “parts only”) online for as low as $10,000.
HP says this puts 3PAR in a new $11 Billion market that it was previously unable to compete.
This represents roughly a 55-65% discount over the previous F-class mid range 3PAR solution. More on this later.
Note that it is not possible to upgrade in place a 7200 to a 7400. So you still have to be sure if you want a 4-node capable system to choose the 7400 up front (you can, of course purchase a two-node 7400 and add the other two nodes later).
Dual vs quad controller
The controller configurations are different between the two and the 7400 has extra cluster cross connects to unify the cluster across enclosures. The 7400 is the first 3PAR system that is not leveraging a passive backplane for all inter-node communications. I don’t know what technology 3PAR is using to provide this interconnect over a physical cable – it may be entirely proprietary. They use their own custom light weight protocols on the connection, so from a software standpoint it is their own stuff. Hardware – I don’t have that information yet.
A unique and key selling point for having a 4-node 3PAR system is persistent cache, which keeps the cache in write back mode during planned or unplanned controller maintenance.

3PAR Persistent Cache mirrors cache from a degraded controller pair to another pair in the cluster automatically.
The 3PAR 7000 series is based on what I believe is the Xyratex OneStor SP-2224 enclosure, the same one IBM uses for their V7000 StorWize system (again, speculation). Speaking of the V7000 I learned tonight that this IBM system implemented RAID 5 in software resulting in terrible performance. 3PAR RAID 5 is well – you really can’t get any faster than 3PAR RAID, that’s another topic though.

3PAR 7000 Series StorServs
3PAR has managed to keep it’s yellow color, and not go to the HP beige/grey. Somewhat surprising though I’m told it’s because it helps the systems stand out in the data center.
The 7000 series comes in two flavors – a two node 7200, and a two or four node 7400. Both will be available starting December 14.
2.5″ or 3.5″ (or both)
There is also a 3.5″ drive enclosure for large capacity SAS (up to 3TB today). There are also 3.5″ SSDs but their capacities are unchanged from the 2.5″ variety – I suspect they are just 2.5″ drives in a caddy. This is based, I believe on the Xyratex OneStor SP-2424.

Xyratex OneStor SP-2424
This is a 4U, 24-drive enclosure for disks only(controllers go in the 2U chassis). 3PAR kept their system flexible by continuing to allow customers to use large capacity disks, however do keep in mind that for the best availability you do need to maintain at least two (RAID 10), three (RAID 5), or six (RAID 6) drive enclosures. You can forgo cage level availability if you want, but I wouldn’t recommend it – that provides an extra layer of protection from hardware faults, at basically no cost of complexity on the software side (no manual layouts of volumes etc).
HP has never supported the high density 3.5″ disk chassis on the mid range systems I believe primarily for cost, as they are custom designed. By contrast the high end systems only support the high density enclosures at this time.

3PAR High Density 3.5" Disk Chassis - not available on mid range systems
The high end chassis is designed for high availability. The disks are not directly accessible with this design. In order to replace disks the typical process is to run a software task on the array which then migrates all of the data from the disks in that particular drive sled (pack of four drives), to other disks on the system(any disks of the same RPM), once the drive sled is evacuated it can be safely removed. Another method is you can just pull the sled, the system will go into logging mode for writes for those disks(sending the writes elsewhere), and you have roughly seven minutes to do what you need to do and re-insert the sled before the system marks those drives as failed and begins the rebuild process.
The one thing that HP does not allow on SP-2424-based 3.5″ drive chassis is high performance (10 or 15K RPM) drives. So you will not be able to build a 7000-series with the same 650GB 15k RPM drives that are available on the high end 10000-series. However they do have a nice 900GB 10k RPM option in a 2.5″ form factor which I think is a good compromise. Or you could go with a 300GB 15k RPM 2.5″. I don’t think there is a technical reason behind this, so I imagine if enough customers really want this sort of setup and yell about it, then HP will cave and start supporting it. Probably won’t be enough demand though.
Basic array specifications
| Array Model | Max Cont. Nodes | Max Raw Capacity | Max Drives | Max Ports | Max Data Cache |
|---|---|---|---|---|---|
| 7200 | 2 | 250TB | 144 | Up to 12x8Gbps FC OR 4x8Gbps FC AND 4x10Gbps iSCSI | 24GB |
| 7400 | 4 | 864TB | 480 | Up to 24x8Gbps FC OR 8x8Gbps FC AND 8x10Gbps iSCSI | 64GB |
| 10400 | 4 | 800TB | 960 | Up to 96x8Gbps FC ports Up to 16x10Gbps iSCSI | 128GB |
| 10800 | 8 | 1600TB | 1920 | Up to 192x8Gbps FC ports Up to 32x10Gbps iSCSI | 512GB |
(Note: All current 3PAR arrays have dedicated gigabit network ports on each controller for IP-based replication)
In a nut shell, vs the F-class mid range systems, the new 7000-series:
- Doubles the data cache per controller to 12GB compared to F200, almost triple if you compare the 7400 to the F200/F400)
- Doubles the control cache per controller to 8GB, The control cache is dedicated memory for the operating system completely isolated from the data cache.
- Brings PCI-Express support to the 3PAR mid range allowing for 8Gbps Fibre Channel and 10Gbps iSCSI
- Brings the mid range up to spec with the latest 4th generation ASIC, and latest Intel processor technology.
- Nearly triples the raw capacity
- Moves from an entirely Fibre channel based system to a SAS back end with a Fibre front end
- Moves from exclusively 3.5″ drives to primarily 2.5″ drives with a couple 3.5″ drive options
- Brings FC0E support to the 3PAR mid range (in 2013) for the four customers who use FCoE.
- Cuts the size of the controllers by more than half
- Obviously dramatically increases the I/O and throughput of the system with the new ASIC with PCIe, faster CPU cores, more CPU cores(in 7400)Â and the extra cache.
Where’s the Control Cache?
Control cache is basically dedicated memory associated with the Intel processors to run the Debian Linux operating system which is the base for 3PAR’s own software layer.
HP apparently has removed all references to the control cache in the specifications, I don’t understand why. I verified with 3PAR last night that there was no re-design in that department, the separated control cache still exists, and as previously mentioned is 8GB on the 7000-series. It’s important to note that some other storage platforms share the same memory for both data and control cache and they give you a single number for how much cache there is – when in reality the data cache can be quite a bit less.
Differences between the 7200 and 7400 series controllers
Unlike previous generations of 3PAR systems, where all controllers for a given class of system were identical, the new controllers for the 104800 vs 10800, as well as the 7200 vs 7400 are fairly different.
- 7200 has quad core 1.8Ghz CPUs, 7400 has hex core 1.8Ghz CPUs.
- 7200 has 12GB cache/controller, 7400 has 16GB/controller.
- 7200 supports 144 disks/controller pair, 7400 is 240 disks.
- Along that same note 7200 supports 5 disk enclosures/pair, 7400 supports nine.
- 7400 has extra cluster interconnects to link two enclosures together forming a mesh active cluster.
iSCSI No longer a second class citizen
3PAR has really only sort of half heartily embraced iSCSI over the years, their customer base was solidly fibre channel. When you talk to them of course they’ll say yes they do iSCSI as well as anyone else but the truth is they didn’t. They didn’t because the iSCSI HBA that they used was the 4000 series from Qlogic. The most critical failing of this part is it’s pathetic throughput. Even though it has 2x1Gbps ports, the card itself is only capable of 1Gbps of throughput. So you look at your 3PAR array and make a decision:
- I can install a 4x4Gbps Fibre channel card and push the PCI-X bus to the limit
- I can install a 2x1Gbps iSCSI card and hobble along with less capacity than a single fibre channel connection
I really don’t understand why they did not go back and re-visit alternative iSCSI HBA suppliers since they kept the same HBA for a whole six years. I would of liked to have seen at least a quad port 1Gbps card that could do 4Gbps of throughput. I hammered on them for years it just wasn’t a priority.
But no more! I don’t know what card they are using now, but it is PCIe and it is 10Gbps! Of course the same applies to the 10000-series – I’d assume they are using the same HBA in both but I am not certain.
Lower cost across the board for the SME
For me these details are just as much, if not more exciting than the new hardware itself. These are the sorts of details people don’t learn about until you actually get into the process of evaluating or purchasing a system.
Traditionally 3PAR has all been about margin – at one point I believe they were known to have the highest margins in the industry (pre acquisition). I don’t know where that point stands today, but from an up front standpoint they were not a cheap platform to use. I’ve always gotten a ton of value out of the platform, making the cost from my standpoint trivial to justify. But to less experienced management out there they often see cost per TB or cost per drive or support costs or whatever, compared to other platforms at a high level they often cost more. How much value you derive from those costs can very greatly.
Now it’s obvious that HP is shifting 3PAR’s strategy from something that is entirely margin focused to most likely lower margins but orders of magnitude more volume to make up for it.
I do not know if any of these apply to anything other than the 7000-series, for now assume they do not.
Thin licensing included in base software
Winning the no brainer of the year award in the storage category HP is throwing in all thin licensing as part of the array with the base license. Prior to this there were separate charges to license thin functionality based on how much written storage was used for thin provisioning. You could license only 10TB on a 100TB array if you want, but you lose the ability to provision new thin provisioned volumes if you exceed that license (I believe there is no impact on existing volumes, but the system will pester you on a daily basis that you are in violation of the license). This approach often caught customers off guard during upgrades – they sometimes thought they only needed to buy disks – but they needed software licenses for those disks, as well as support for those software licenses.
HP finally realized that thin provisioning is the norm rather than the exception. HP is borrowing a page from the Dell Compellent handbook here.
Software License costs capped
Traditionally, most of 3PAR’s software features are based upon some measure of capacity of the system, in most cases it is raw capacity, for thin provisioning it is a more arbitrary value.
HP is once again following the Dell Compellent handbook which caps license costs at a set value(in Dell’s case I believe it is 96 spindles). For the 3PAR 7000-series the software license caps are:
- 7200: 48 drives (33% of array capacity)
- 7400: 168 drives (35% of array capacity)
Easy setup with Smart Start
Leveraging technology from the EVA line of arrays, HP has radically simplified the installation process of a 7000-series array, so much so that the customer can now perform the installation on their own without professional services. This is huge for this market segment. The up front professional services to install a mid range F200 storage system had a list price of $10,000 (as of last year anyway).
User serviceable components
Again for the first time in 3PAR’s history a customer will be allowed to replace their own components (disks at least, I assume controllers as well though). This again is huge – it will slash the entry level pricing for support for organizations that have local support staff available.
The 7000-series comes by default with a 24x7x365 4-hour on site support (parts only). I believe software support and higher end on site services are available for an additional charge.
All SSD 7000 series
Like the 10000-series, the 7000-series can run on 100% SSDs, a configuration that for some reason was not possible on the previous F-series of midrange systems (also I think T-class could not as well).
HP claims that with a maximum configuration, a 4-node 7400 maxed out with 240 x 100 or 200GB SSDs the system can achieve 320,000 IOPS, a number which HP claims is a 2.4x performance advantage to their closest priced competitor. This number is based on a 100% random read test with 8kB block sizes @ 1.6 milliseconds of latency. SPC-1 numbers are coming – I’d guesstimate that SPC-1 for the 7400 will be in the ~110,000 IOPS range since it’s roughly 1/4th the power of a 10800 (half the nodes, and each node has half the ASICs & CPUs and far less data cache).
HP is also announcing their intention to develop a purpose built all-SSD solution based on 3PAR technology.
Other software announcements
Most of them from here.
Priority Optimization
For a long time 3PAR has touted it’s ability to handle many workloads of different types simultaneously, providing multiple levels of QoS on a single array. This was true, to a point.

3PAR: Mixed quality of service in the same array
While it is true that you can provide different levels of QoS on the same system, 3PAR customers such as myself realized years ago that it could be better. A workload has the potential to blow out the caches on the controllers (my biggest performance headache with 3PAR – it doesn’t happen often, all things considered I’d say it’s probably a minor issue compared to competing platforms but for me it’s a pain!). This is even more risky in a larger service provider environment where the operator has no idea what kind of workloads the customers will be running. Sure you can do funky things like carve the system up so less of it is impacted when that sort of event happens but there are trade offs there as well.

Priority Optimization
The 3PAR world is changing – with Priority Optimization – a feature that essentially beta at this point, allows the operator to set thresholds both on an IOPS as well as bandwidth perspective. The system reacts basically in real time. Now on a 3PAR platform you can guarantee a certain level of performance to a workload. Whereas in the past, there was a lot more hope involved. Correct me if I’m wrong but I thought this sort of QoS was exactly the sort of thing that Oracle Pillar used to tout. I’m not sure if they had knobs like this, but I do recall them touting QoS a lot.
Priority Optimization will be available sometime in 2013 – I’d imagine it’d be early 2013 but not sure.
Autonomic Replication
As I’ve said before – I’ve never used 3PAR replication – never needed it. I’ve tended to build things so that data is replicated via other means, and low level volume-based replication is just overkill – not to mention the software licensing costs.

3PAR Synchronous long distance replication: unique in the mid range
But many others I’m sure do use it, and this industry first as HP called it is pretty neat. Once you have your arrays connected, and your replication policies defined, when you create a new volume on the source array, all details revolving around replication are automatically configured to protect that volume according to the policy that is defined. 3PAR replication was already a breeze to configure, this just made it that much easier.
Autonomic Rebalance
3PAR has long had the ability to re-stripe data across all spindles when new disks were added, however this was always somewhat of a manual process, and it could take a not insignificant amount of time because your basically reading and re-writing every bit of data on the system. It was a very brute force approach. On top of that you had to have a software license for Dynamic Optimization in order to use it.
Autonomic rebalance is now included in the base software license and will automatically re-balance the system when resources change, new disks, new controllers etc. It will try, whenever possible, to move the least amount of data – so the brute force approach is gone, the system has the ability to be more intelligent about re-laying out data.
I believe this approach also came from the EVA storage platform.
Persistent Ports
This is a really cool feature as well – it gives the ability to provide redundant connectivity to multiple controllers on a 3PAR array without having to have host-based multipathing software. How is this possible? Basically it is NPIV for the array. Peer controllers can assume the world wide names for the ports on their partner controller. If a controller goes down, it’s peer assumes the identities of that controller’s ports, instantaneously providing connectivity for hosts that were (not directly) connected to the ports on the downed controller. This eliminates pauses for MPIO software to detect faults and fail over, and generally makes life a better place.
HP claims that some other tier 1 vendors can provide this functionality for software changes, but they do not today, provide it for hardware changes. 3PAR provides this technology for both hardware and software changes – on all of their currently shipping systems!
Peer Persistence
This is basically a pair of 3PAR arrays acting as a transparent fail over cluster for local or metro distances. From the PDF –
The Peer Persistence software achieves this key enhancement by taking advantage of the Asymmetric Logical Unit Access (ALUA) capability that allows paths to a SCSI device to be marked as having different characteristics.
Peer persistence also allows for active-active to maximize available storage I/O under normal conditions.
Initially Peer Persistence is available for VMware, other platforms to follow.

3PAR Peer Persistence
Virtualized Service Processor
All 3PAR systems have come with a dedicated server known as the Service Processor, this acts as a proxy of sorts between the array and 3PAR support. It is used for alerting as well as remote administration. The hardware configuration of this server was quite inflexible and it made it needlessly complex to deploy in some scenarios (mainly due to having only a single network port).
The service processor was also rated to consume a mind boggling 300W of power (it may of been a legacy typo but that’s the number that was given in the specs).
The Service processor can now be deployed as a virtual machine!
Web Services API
3PAR has long had a CIM API (never really knew what that was to be honest), and it had a very easy-to-use CLI as well (used that tons!), but now they’ll have a RESTful Web Services API that uses JSON (ugh, I hate JSON as you might recall! If it’s not friends with grep or sed it’s not friends with me!). Fortunately for people like me we can keep using the CLI.
This API is, of course, designed to be integrated with other provisioning systems, whether it’s something off the shelf like OpenStack, or custom stuff organizations write on their own.
Additional levels of RAID 6
3PAR first introduced RAID 6 (aka RAID DP) with the aforementioned last major software release three years ago, with that version there were two options for RAID 6:
- 6+2
- 14+2
The new software adds several more options:
- 4+2
- 8+2
- 10+2
Thick Conversion
I’m sure many customers have wanted this over the years as well. The new software will allow you to convert a thin volume to a thick (fat) volume. The main purpose of this of course is to save on licensing for thin provisioning when you have a volume that is fully provisioned (along with the likelihood of space reclamation on that volume being low as well). I know I could of used this years ago.. I always shook my fist at 3PAR when they made it easy to convert to thin, but really impossible to convert back to thick (without service disruption anyway). Basically all that is needed is to flip a bit in the OS (I’m sure the nitty gritty is more complicated).
Online Import
This basically allows EVA customers to migrate to 3PAR storage without disruption (in most cases).
System Tuner now included by default
The System Tuner package is now included in the base operating system (at least on 7000-series). System Tuner is a pretty neat little tool written many years ago that can look at a 3PAR system in real time, and based on thresholds that you define recommend dynamic movement of data around the system to optimize the data layout. From what I recall it was written in response to a particular big customer request to prove that they could do such data movement.

3PAR System Tuner moves chunklets around in real time
It is important to note that this tool is an on demand tool, when running it gathers tens of thousands of additional performance statistics from the chunklets on the system. It’s not something that can(or should be) run all the time. You need to run it when the workload you want to analyse is running in order to see if further chunklet optimization would benefit you.
System Tuner will maintain all existing availability policies automatically.
In the vast majority of cases the use of this tool is not required. In fact in my experience going back six years I’ve used it on a few different occasions, and in all cases it didn’t provide any benefit. The system generally does a very good job of distributing resources. But if your data access patterns change significantly, System Tuner may be for you – and now it’s included!
3PAR File Services
This announcement was terribly confusing to me at first. But I got some clarification. The file services module is based on the HP StoreEasy 3830 storage gateway.
- Hardware platform is a DL380p Gen8 rack server attached to the 3PAR via Fibre Channel
- Software platform is Microsoft Windows Storage Server 2012 Standard Edition
- Provides NFS, CIFS for files and iSCSI for block
- SMB 3.0 supported (I guess that is new, I don’t use CIFS much)
- NFS 4.1 supported (I’ll stick to NFSv3, thanks – I assume that is supported as well)
- Volumes up to 16TB in size
- Integrated de-duplication (2:1 – 20:1)
- VSS Integration – I believe that means no file system-based snapshots (e.g. transparent access of the snapshot from within the same volume) ?
- Uses Microsoft clustering for optional HA
- Other “Windowsey” things
The confusion comes from them putting this device under the 3PAR brand. It doesn’t take a rocket scientist to look at the spec sheets and see there are no Ethernet ports on the arrays for file serving. I’d be curious to find out the cost of this file services add-on myself, and what it’s user interface is like. I don’t believe there is any special integration between this file services module and 3PAR – it’s just a generic gateway appliance.
For someone with primarily a Linux background I have to admit I wouldn’t feel comfortable relying on a Microsoft implementation of NFS for my Linux boxes (by the same token I feel the same way about using Samba for serious Windows work – these days I wouldn’t consider it – I’d only use it for light duty simple stuff).
Oh while your at it HP – gimme a VSA of this thing too.
Good-bye EVA and VSP, I never knew thee
Today I think was one of the last nails in the coffin for EVA. Nowhere was EVA present on the presentation other than providing tools to seamlessly migrate off of EVA onto 3PAR. Well that and they have pulled some of the ease of use from EVA into 3PAR.
Literally nowhere was Hitachi VSP (aka HP P9500). Since HP acquired 3PAR the OEM’d Hitachi equipment has been somewhat of a fifth wheel in the HP storage portfolio. Like the EVA, HP had customers who wanted the VSP for things that 3PAR simply could not or would not do at the time. Whether it was mainframe connectivity, or perhaps ultra high speed data warehousing. When HP acquired 3PAR, the high end was still PCI-X based and there wasn’t a prayer it was going to be able to dish out 10+ GB/second. The V800 changed that though. HP is finally making inroads into P9500 customers with the new 3PAR gear. I personally know of two shops that have massive deployments of HP P9500 that will soon have their first 3PAR in their respective data centers. I’m sure many more will follow.
Time will tell how long P9500 sticks around, but I’d be shocked – really shocked if HP decided to OEM whatever came next out of Hitachi.
What’s Missing
This is a massive set of announcements, the result of blood sweat and tears of many engineers work, assuming it all works as advertised they did an awesome job!
BUT.
There’s always a BUT isn’t there.
There is one area that I have hammered on 3PAR for what feels like three years now and haven’t gotten anywhere, the second area is more of a question/clarification.
SSD-Accelerated write caching
Repeat after me – AO (Adaptive Optimization) is not enough. Sub LUN auto tiering is not enough. I brought this up with David Scott himself last year, and I bring it up every time I talk to 3PAR. Please, I beg you please, come out with SSD-accelerated write caching technology. The last time I saw 3PAR in person I gave them two examples – EMC FastCache which is both a read and a write back cache. The second is Dell Compellent’s Data Progression technology. I’ve known about Compellent’s storage technology for years but there was one bit of information that I was not made aware of until earlier this year. That is their Data Progression technology by default automatically sends ALL writes (regardless of what tier the blocks live on), to the highest tier. On top of that, this feature is included in the base software license, it is not part of the add-on automatic tiering software.
The key is accelerating writes. Not reads, though reads are nice too. Reads are easy to accelerate compared to writes. The workload on my 3PAR here at my small company is roughly 92% write (yes you read that right). Accelerating reads on the 3PAR end of things won’t do anything for me!
If they can manage to pull themselves together and create a stable product, the Mt. Rainier technology from Qlogic could be a stop gap. I believe NetApp is partnered with them already for those products. Mt. Rainier, other than being a mountain near Seattle, is a host-based read and write acceleration technology for fibre channel storage systems.
Automated Peer Motion
HP released this more than a year ago – however to-date I have not noticed anything revolving around automatic movement of volumes. Call it what you want, load balancing, tiering, or something, as far as I know at this point any actions involving peer motion are entirely manual. Another point is I’m not sure how many peers an array can have. HP tries to say it’s near limitless – could you have 10 ? 20 ? 30 ? 100 ? I don’t know the answer to that.
Again going back to Dell Compellent (sorry) their Live Volume software has automatic workload distribution. I asked HP about this last year and they said it was not in place then – I don’t see it in place yet.
That said – especially with the announcements here I’m doubling down on my 3PAR passion. I was seriously pushing Compellent earlier in the year(one of the main drivers was cost – one reseller I know calls them the Poor Man’s 3PAR) but where things stand now, their platform isn’t competitive enough at this point, from either a cost or architecture standpoint. I’d love to have my writes going to SSD as Compellent’s Data Progression does things, but now that the cost situation is reversed, it’s a no brainer to stick with 3PAR.
More Explosions
HP needs to take an excursion and blow up some 3PAR storage to see how fast and well it handles disaster recovery, take that new Peer Persistence technology and use it in the test.
Other storage announcements
As is obvious by now, the rest of the announcements pale in comparison to what came out of 3PAR. This really is the first major feature release of 3PAR software in three years (the last one being 2.3.1 which my company at the time participated in the press event and I was lucky enough to be the first production customer to run it in early January 2010 (had to for Exanet support – Exanet was going bust and I wanted to get on their latest code before they went *poof*)).
StoreOnce Improvements
The StoreOnce product line was refreshed earlier in the year and HP made some controversial performance claims. From what I see the only improvement here is they brought down some performance enhancements from the high end to all other levels of the StoreOnce portfolio.
I would really like to see HP release a VMware VSA with StoreOnce, really sounds like a no brainer, I’ll keep waiting..
StoreAll Improvements
StoreAll is the new name for the IBRIX product line, HP’s file and object storage offering. The main improvement here is something called Express Query which I think is basically a meta data search engine that is 1000s of times faster than using regular search functions for unstructured data. For me I’d rather just structure the data a bit more, the example given is tagging all files for a particular movie to make it easier to retrieve later. I’d just have a directory tree and put all the files in the tree – I like to be organized. I think this new query tool depends on some level of structure – the structure being the tags you can put on files/objects in the system.

HP Converged storage growth - 38% YoY - notice no mention of StoreAll/IBRIX! Also no mention of growth for Lefthand either
HP has never really talked a whole lot about IBRIX – and as time goes on I’m understanding why. Honestly it’s not in the same league (or sport for that matter) for quality and reliability as 3PAR is, not even close. It lacks features, and according to someone I know who has more than a PB on HP IBRIX storage (wasn’t his idea it’s a big company)Â it’s really not pleasant to use. I could say more but I’ll end by saying it’s too bad that HP does not have a stronger NAS offering. IBRIX may scale well on paper, but there’s a lot more to it than the paper specs of course. I went over the IBRIX+3PAR implementation guide, for using 3PAR back end storage on a IBRIX system and wasn’t impressed with some of the limitations.
Like everything else, I would like to see a full IBRIX cluster product deployable as a VMware VSA. It would be especially handy for small deployments(e.g. sub 1TB). The key here is the high availability.
HP also announced integration between StoreAll ExpressQuery and Autonomy software. When the Autonomy guy came on the stage I really just had one word to describe it: AWKWARD – given what happened recently obviously!
StoreVirtual
This was known as the P4000, or Lefthand before that. It was also refreshed earlier in the year. Nothing new announced today. HP is trying to claim the P4000 VSA as Software Defined Storage (ugh).
Conclusion
Make no mistake people – this storage announcement was all about 3PAR. David Scott tried his best to share the love, but there just wasn’t much exciting to talk about outside of 3PAR.
6,000+ words ! Woohoo. That took a lot of time to write, hopefully it’s the most in depth review of what is coming out.





{kind=link}