Assuming HP gets them, which I am optimistic will occur. This is what I think HP should do.
I’m sure this is all pretty obvious but it gives me something to write about 🙂
Why the changes to the EVA offerings and dropping of the F200 from 3PAR? To me, it all comes down to the 4 node architecture that 3PAR has, and the ability to offer persistent cache.
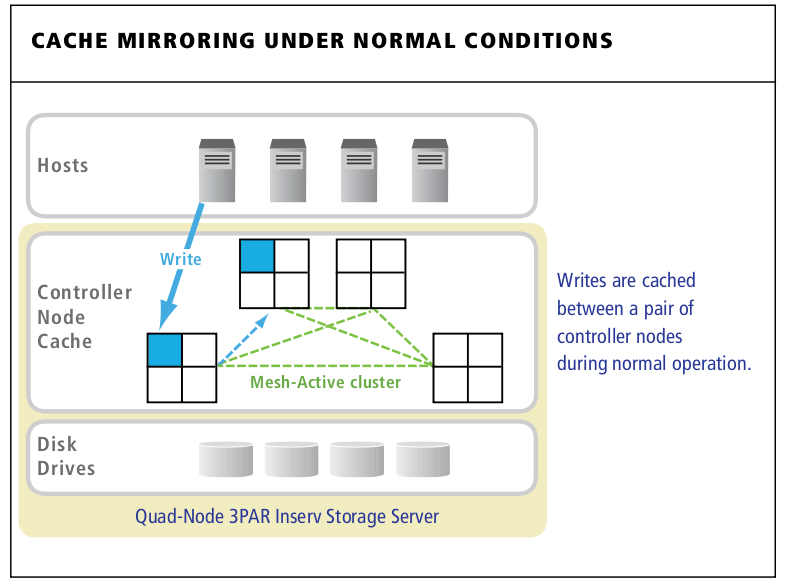
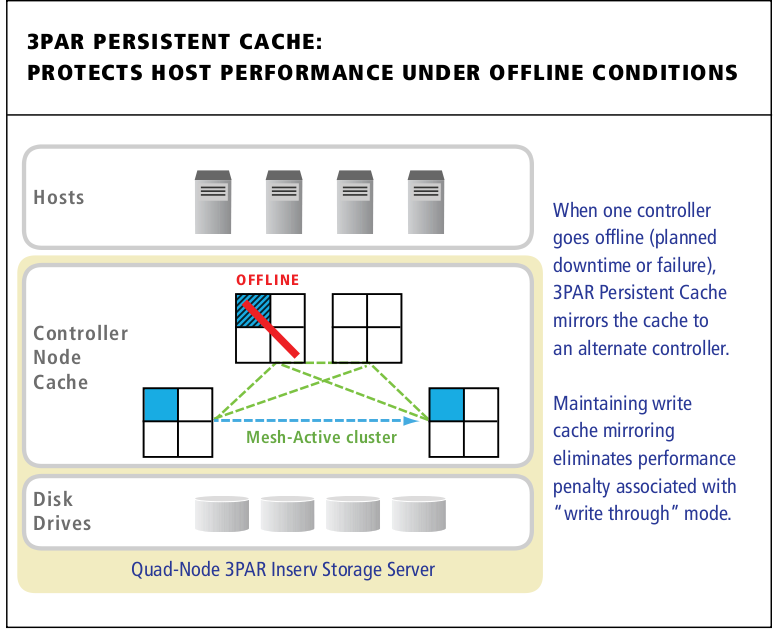
3PAR Persistent Cache is a resiliency feature designed to gracefully handle component failures by eliminating the substantial performance penalties associated with “write-through†mode. Supported on all quad-node and larger InServ arrays, Persistent Cache leverages the InServ’s unique Mesh-Active design to preserve write-caching by rapidly re-mirroring cache to the other nodes in the cluster in the event of a controller node failure.
-
-
-
3PAR Persistent Cache mirrors cache from a degraded controller pair to another pair in the cluster automatically.
(click on images for larger version)
Persistent cache allows service providers to operate at higher levels of utilization because they know they can maintain high performance even when a controller fails(or if two/three controllers fail in a 6/8 node T800 as long as they are the right nodes!), one of my former employers has a bunch of NetApp stuff, and I’m told they run them pretty much entirely active/passive, so as to protect performance in the event a controller fails. I’m sure that is a fairly common setup.
This is also useful during software upgrades, where the controllers have to be rebooted, or hardware upgrades (adding more FC ports or whatever).
Another reason is the ease of use around configuring multi site replication, and the ability to do synchronous long distance replication on the mid range systems.
3PAR® is the first storage vendor to offer autonomic disaster recovery (DR) configuration that enables you to set up and test your entire DR environment—including multi-site, multi-mode replication using both mid-range and high-end arrays—in just minutes.
[..]
Synchronous Long Distance replication combines the best of both worlds by offering the data integrity of synchronous mode disaster recovery and the extended distances (including cross-continental reach) possible with asynchronous replication. Remote Copy makes all of this possible without the complexity or professional services required by the monolithic vendors that offer multi-target disaster recovery products, and at half the cost or less.
I can understand why 3PAR came up with the F200, it is a bit cheaper, the only difference is the chassis the nodes go in, the nodes are the same, everything else is the same. So to me it’s a no brainer to spend the extra what 10-15% up front and get the capability to go to four controllers even if you don’t need that up front. Takes an extra 4U of rack space. If you really want to be cheap, go with the small 2-node EVA.
I find it kind of funny that on the main page for EVA, the EVA-4000’s blurb for what it is “Ideal for” is blank.
Assuming HP gets them, which I am optimistic will occur. This is what I think HP should do.
* Phase out current USP-based XP line with the 800-series of 3PAR systems, currently the T800
* Phase out the EVA Cluster with the enterprise 400-series of 3PAR systems, currently the T400
* Phase out the EVA 6400 and 8400 with the mid range 400-series of 3PAR systems, currently the F400
* Phase out the 3PAR F200, replace it with the EVA 4400-series
I’m sure this is all pretty obvious but it gives me something to write about 🙂
Why the changes to the EVA offerings and dropping of the F200 from 3PAR? To me, it all comes down to the 4 node architecture that 3PAR has, and the ability to offer persistent cache.
3PAR Persistent Cache is a resiliency feature designed to gracefully handle component failures by eliminating the substantial performance penalties associated with “write-through†mode. Supported on all quad-node and larger InServ arrays, Persistent Cache leverages the InServ’s unique Mesh-Active design to preserve write-caching by rapidly re-mirroring cache to the other nodes in the cluster in the event of a controller node failure.
-
-
-
3PAR Persistent Cache mirrors cache from a degraded controller pair to another pair in the cluster automatically.
(click on image for larger version)
Persistent cache allows service providers to operate at higher levels of utilization because they know they can maintain high performance even when a controller fails(or if two controllers fail in a 6/8 node T800 as long as they are the right nodes!), one of my former employers has a bunch of NetApp stuff, and I’m told they run them pretty much entirely active/passive, so as to protect performance in the event a controller fails. I’m sure that is a fairly common setup.
Another reason is the ease of use around configuring multi site replication, and the ability to do synchronous long distance replication on the mid range systems.
I can understand why 3PAR came up with the F200, it is a bit cheaper, the only difference is the chassis the nodes go in, the nodes are the same, everything else is the same. So to me it’s a no brainer to spend the extra what 10-15% up front and get the capability to go to four controllers even if you don’t need that up front. Takes an extra 4U of rack space. If you really want to be cheap, go with the small 2-node EVA.